近日,Cohere 宣布推出两款新的开源 AI 模型,旨在通过其 Aya 项目缩小基础模型的语言差距。这两款新模型名为 Aya Expanse8B 和35B,现已在 Hugging Face 上提供使用。这两个模型的推出,让23种语言的 AI 性能得到了显著提升。

Cohere 在其博客中表示,8B 参数模型让全球研究人员能更轻松地获得突破,而32B 参数模型则提供了业界领先的多语言能力。
Aya 项目的目标是扩展更多非英语语言的基础模型访问。在此之前,Cohere 的研究部门去年启动了 Aya 计划,并在2月份发布了 Aya101大语言模型(LLM),这款模型涵盖了101种语言。此外,Cohere 还推出了 Aya 数据集,以帮助在其他语言上进行模型训练。
Aya Expanse 模型在构建过程中沿用了 Aya101的许多核心方法。Cohere 表示,Aya Expanse 的改进是基于多年来在机器学习突破领域重新思考核心构建块的结果。他们的研究方向主要集中在缩小语言差距,取得了一些关键性突破,如数据套利、针对一般性能和安全性的偏好训练以及模型合并等。
在多项基准测试中,Cohere 表示,Aya Expanse 的两个模型表现超越了 Google、Mistral 和 Meta 等公司同类规模的 AI 模型。
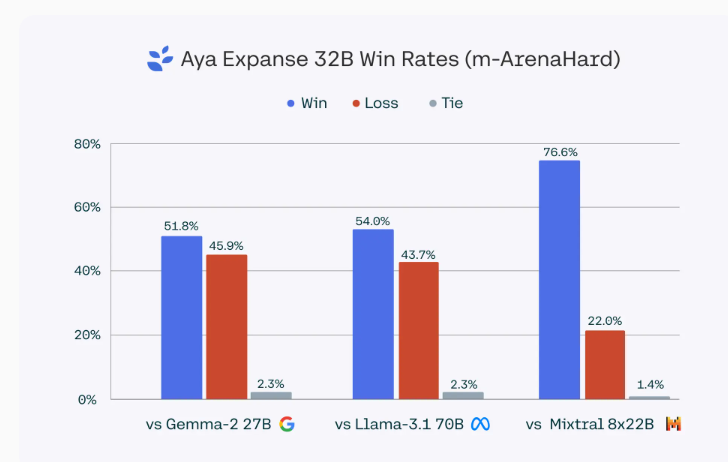
其中,Aya Expanse32B 在多语言基准测试中的表现超越了 Gemma227B、Mistral8x22B,甚至是更大的 Llama3.170B。而小型的8B 模型同样超越了 Gemma29B、Llama3.18B 和 Ministral8B,胜率从60.4% 到70.6% 不等。
为了避免生成难以理解的内容,Cohere 采用了一种名为数据套利的数据采样方法。这种方法能够更好地训练模型,尤其是针对低资源语言时更为有效。此外,Cohere 还专注于引导模型朝向 “全球偏好”,并考虑不同文化和语言的视角,进而提高模型的性能与安全性。
Cohere 的 Aya 计划力求确保 LLM 在非英语语言的研究上能够有更好的表现。虽然许多 LLM 最终会推出其他语言版本,但在训练模型时常常面临数据不足的问题,尤其是对于低资源语言。因此,Cohere 的努力在帮助构建多语言 AI 模型方面显得尤为重要。
官方博客:https://cohere.com/blog/aya-expanse-connecting-our-world
划重点:
🌍 *Cohere 推出两款新 AI 模型 *,致力于缩小基础模型的语言差距,支持23种语言的性能提升。
💡 *Aya Expanse 模型表现优异 *,在多语言基准测试中超越了许多同类竞争对手。
🔍 * 数据套利方法 * 帮助模型避免生成低质量内容,关注全球文化与语言视角,提高了多语言 AI 的训练效果。