来自智源研究院的Emu3团队发布了一套全新的多模态模型Emu3,该模型仅基于下一个token预测进行训练,颠覆了传统的扩散模型和组合模型架构,在生成和感知任务上均取得了最先进的性能。
一直以来,下一个token预测被认为是通向人工智能通用智能(AGI)的希望之路,但在多模态任务上却表现不佳。目前,多模态领域仍然由扩散模型(如Stable Diffusion)和组合模型(如CLIP与LLM的结合)主导。Emu3团队将图像、文本和视频都标记化到离散空间中,并在混合的多模态序列上从头开始训练单个Transformer模型,从而实现了多模态任务的统一,无需依赖扩散或组合架构。
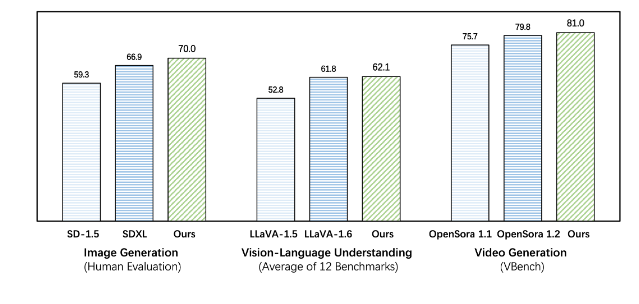
Emu3在生成和感知任务上的表现都超越了现有的特定任务模型,甚至超越了SDXL和LLaVA-1.6等旗舰模型。Emu3还能够通过预测视频序列中的下一个token来生成高保真视频。 不同于Sora使用视频扩散模型从噪声中生成视频,Emu3通过预测视频序列中的下一个token,以因果的方式生成视频。该模型可以模拟现实世界中环境、人物和动物的某些方面,并在给定视频上下文的情况下,预测接下来会发生什么。
Emu3简化了复杂的多模态模型设计,将重点集中在token上,从而释放了训练和推理过程中的巨大扩展潜力。 研究结果表明,下一个token预测是构建超越语言的通用多模态智能的有效途径。为了支持该领域进一步的研究,Emu3团队开源了关键技术和模型,包括一个强大的视觉标记器,可以将视频和图像转换为离散token,这在以前是公开不可用的。
Emu3的成功为多模态模型的未来发展指明了方向,也为实现AGI带来了新的希望。
项目地址:https://github.com/baaivision/Emu3