最近,科研团队联合推出了一款名为 Meissonic 的开源 AI 图像生成模型。惊喜的是,这款模型仅使用了十亿个参数,却能生成高质量的图像。这种紧凑的设计让 Meissonic 有潜力在移动设备上实现本地化的文本转图像应用。

这项技术的背后,研发团队包括阿里巴巴、Skywork AI 以及多所大学的研究者。他们采用了一种独特的变换器架构和新颖的训练方法,使得 Meissonic 能够在普通游戏 PC 上运行,甚至未来可能在手机上使用。
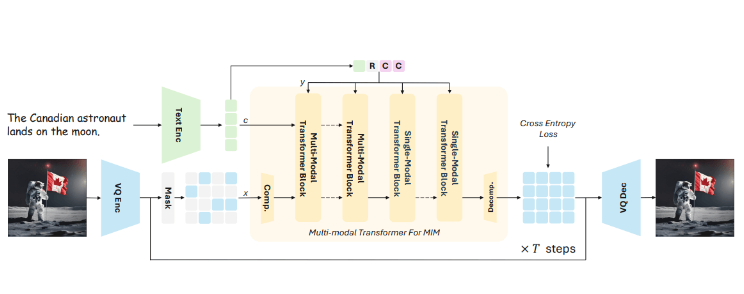
Meissonic 的训练方法采用了一种被称为 “遮蔽图像建模” 的技术,简单来说,就是在训练过程中会隐藏图像的一部分。模型学习如何根据可见的区域和文本描述来重建缺失的部分。这种方式帮助模型理解图像元素和文本之间的关系。
Meissonic 的架构让它能够生成1024x1024像素的高分辨率图像,无论是逼真的场景还是风格化的文本、表情包,甚至卡通贴纸,都能轻松应对。
与传统的自回归模型逐步生成图像不同,Meissonic 则是通过并行的迭代优化来同时预测所有的图像信息,这一创新显著减少了解码的步骤,大约减少了99% 的时间,大幅提升了图像生成的速度。
在模型的构建过程中,研究者们经历了四个步骤:
首先,他们用2亿张256x256像素的图像教授模型基本概念;接着,用1000万对经过严格筛选的图像 - 文本对提升其文本理解能力;然后,通过增加特殊的压缩层,使得模型能够输出1024x1024像素的图像;最后,他们进行了微调,结合人类偏好的数据来提升模型的性能。

有趣的是,尽管 Meissonic 的参数量较小,但在多项基准测试中表现优于一些更大的模型,比如 SDXL 和 DeepFloyd-XL,其在 “人类偏好分数” 上获得了28.83的高分。此外,Meissonic 还能够在不额外训练的情况下进行图像的修补和扩展,允许用户轻松添加缺失的图像部分或创造性地增强现有的图像。
研究团队认为,这种方法可能会促进定制 AI 图像生成器的快速、低成本开发,也有望推动移动设备上文本转图像应用的发展。感兴趣的朋友们可以在 Hugging Face 上找到演示版本,并在 GitHub 上查看模型的代码,使用普通8GB 显存的消费者 GPU 便可轻松运行。
demo:https://huggingface.co/spaces/MeissonFlow/meissonic
项目:https://github.com/viiika/Meissonic
划重点:
🌟 Meissonic 是一款仅用十亿个参数就能生成高质量图像的开源 AI 模型,适合普通游戏 PC 和未来的移动设备使用。
⚡ 采用并行迭代优化的训练方法,Meissonic 在图像生成速度上比传统模型快99%。
🏆 尽管参数量小,Meissonic 在多项测试中表现超越更大模型,且能实现无训练的图像修补和扩展功能。