英伟达与麻省理工学院、清华大学的研究人员合作开发了一款名为Sana的全新文本到图像生成框架,该框架能够高效生成高达4096×4096分辨率的图像。
Sana可以在极快的速度下合成高分辨率、高质量且与文本高度一致的图像,甚至可以在笔记本电脑的GPU上运行。

Sana 的核心设计包括:
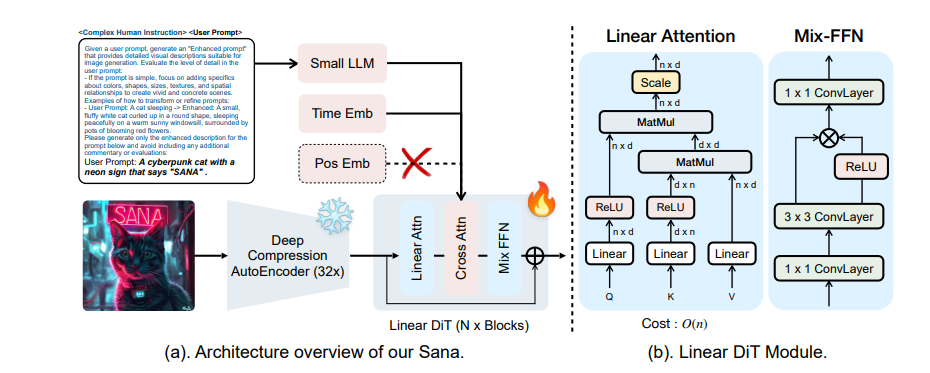
深度压缩自动编码器:与传统的自动编码器仅压缩图像8倍不同,Sana 训练的自动编码器可以将图像压缩32倍,有效减少了潜在标记的数量。
线性 DiT:Sana 将 DiT 中所有普通的注意力机制替换为线性注意力机制,这在高分辨率图像生成时更加高效,且不会牺牲质量。
仅解码器文本编码器:研究人员用更先进的小型仅解码器语言模型 (LLM) Gemma 替换了 T5作为文本编码器,并设计了复杂的人类指令和上下文学习来增强图像与文本的一致性。
高效的训练和采样:Sana 提出了 Flow-DPM-Solver 来减少采样步骤,并通过高效的标题标记和选择来加速模型收敛。
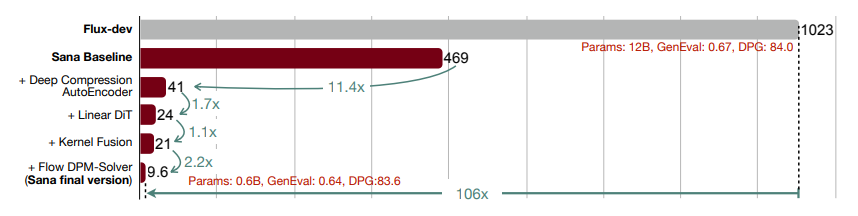
得益于这些设计,Sana-0.6B 在性能上与大型扩散模型(如 Flux-12B)不相上下,但模型规模却小20倍,速度快100多倍。
此外,Sana-0.6B 可以部署在16GB 的笔记本电脑 GPU 上,生成1024×1024分辨率的图像只需不到1秒钟,Sana 使低成本的内容创作成为可能。
Sana 的主要优势在于其高效性。 在4K 图像生成方面,Sana-0.6B 的吞吐量比目前最先进的方法 (FLUX) 快100多倍,在1K 分辨率下快40倍。
研究人员还对 Sana-0.6B 进行了量化,并将其部署在边缘设备上。在配备 RTX-4090GPU 的消费级设备上,生成1024×1024分辨率的图像只需0.37秒,为实时图像生成提供了强大的基础模型。
未来,研究人员计划基于 Sana 构建一个高效的视频生成流程。 然而,该研究也存在一些局限性,例如无法完全保证生成图像内容的安全性和可控性,在文本渲染、人脸和手部生成等复杂情况下也存在挑战。
项目地址:https://nvlabs.github.io/Sana/
论文地址:https://arxiv.org/pdf/2410.10629