最近,Meta、加州大学伯克利分校和纽约大学的科学家们合作研发了一种新技术,名为 “思维偏好优化”(Thought Preference Optimization,简称 TPO)。这项技术的目标是提升大型语言模型(LLMs)在执行各种任务时的表现,让 AI 在回答之前更加仔细地考虑自己的反应。
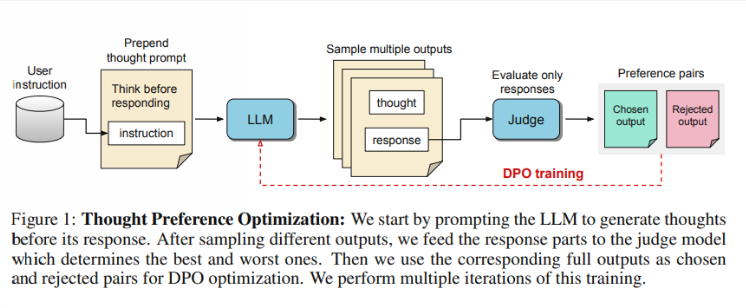
研究人员表示,“思考” 应该具有广泛的实用性。比如,在创意写作任务中,AI 可以利用内在的思维过程来规划整体结构和角色发展。这种方法与以往的 “链式思考”(Chain-of-Thought,CoT)提示技术有显著不同。后者主要应用于数学和逻辑任务,而 TPO 的应用范围则更加广泛。研究人员提到 OpenAI 的新 o1模型,认为思考的过程对更广泛的任务也有帮助。
那么,TPO 是如何运作的呢?首先,模型会在回答问题之前生成一系列思维步骤。接下来,它会创造多个输出,随后由一个评估模型只评估最终的答案,而不是思维步骤本身。最后,通过对这些评估结果的偏好优化,模型得以进行训练。研究人员希望,提升回答质量能够通过改进思维过程实现,从而使模型在隐性学习中获得更有效的推理能力。
在测试中,使用 TPO 的 Llama38B 模型在一般指令遵循的基准测试中表现优于没有采用显式推理的版本。在 AlpacaEval 和 Arena-Hard 基准测试中,TPO 的胜率分别达到了52.5% 和37.3%。更令人兴奋的是,TPO 在一些通常不需要显式思考的领域,比如常识、市场营销和健康等方面也取得了进展。
不过,研究团队指出,目前的设置不适用于数学问题,因为在这些任务中,TPO 的表现实际上低于基础模型。这表明,针对高度专业化的任务,可能需要采用不同的方法。未来的研究可能会集中在思维过程的长度控制以及思考对更大模型的影响等方面。
划重点:
🌟 研究团队推出 “思维偏好优化”(TPO),旨在提升 AI 在任务执行中的思考能力。
🧠 TPO 通过让模型在回答前生成思维步骤,利用评估模型优化回答质量。
📈 测试表明,TPO 在常识和市场营销等领域表现出色,但在数学任务上表现不佳。