伊利诺伊理工学院、浙江大学、中佛罗里达大学以及伊利诺伊大学芝加哥分校的研究团队近日联合发布了全新的3D场景大语言模型Robin3D。
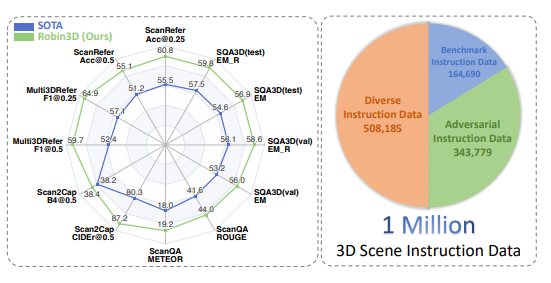
该模型在包含一百万条指令遵循数据的大规模数据集上进行训练,并在五个常用的3D多模态学习基准测试中均取得了当前最佳的性能表现,标志着在构建通用3D智能体方向上的重大进步。
Robin3D的成功得益于其创新的数据引擎RIG (Robust Instruction Generation)。RIG引擎旨在生成对抗性指令遵循数据和多样化指令遵循数据两种关键指令数据。
对抗性指令遵循数据通过混合正负样本来增强模型的辨别理解能力,而多样化指令遵循数据则包含各种指令风格以增强模型的泛化能力。
研究人员指出,现有的3D大语言模型主要依赖于正面的3D视觉语言配对和基于模板的指令进行训练,这导致了泛化能力不足和过度拟合的风险。Robin3D通过引入对抗性和多样化的指令数据,有效地克服了这些局限性。
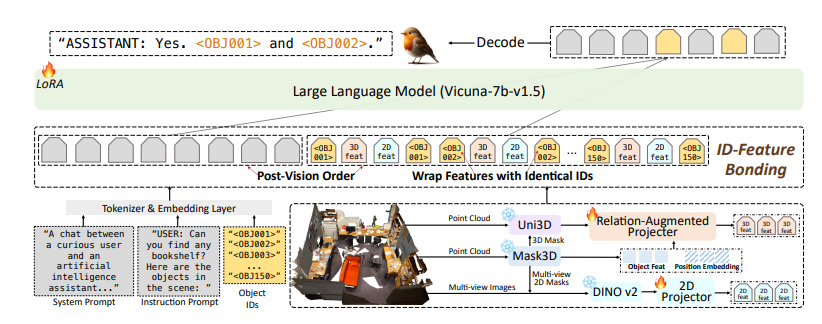
Robin3D模型还集成了关系增强投影器(RAP)ID特征绑定(IFB)指称和定位能力。RAP模块通过丰富的场景级上下文和位置信息来增强以对象为中心的特征,而IFB模块则通过将每个ID与其对应的特征绑定来加强它们之间的连接。
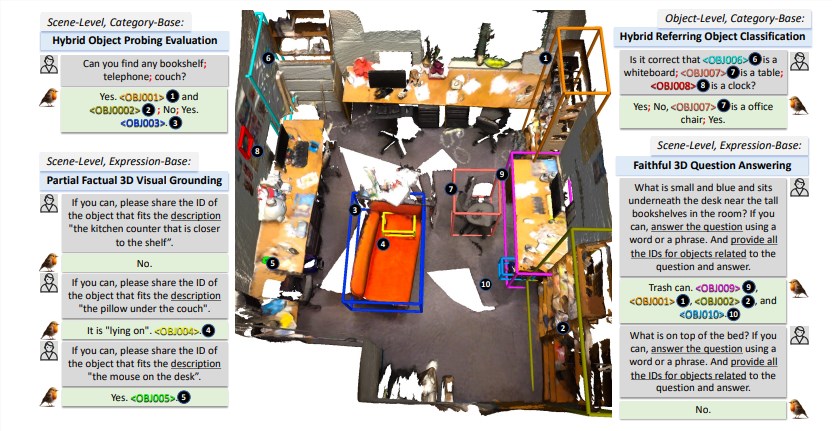
实验结果表明,Robin3D在无需针对特定任务进行微调的情况下,在包括ScanRefer、Multi3DRefer、Scan2Cap、ScanQA和SQA3D在内的五个基准测试中均超越了之前的最佳方法。
尤其是在包含零目标案例的Multi3DRefer评估中,Robin3D在F1@0.25和F1@0.5指标上分别取得了7.8%和7.3%的显著提升。
Robin3D的发布标志着3D大语言模型在空间智能方面取得了重大进步,为未来构建更加通用和强大的3D智能体奠定了坚实的基础。
论文地址:https://arxiv.org/pdf/2410.00255