标题:OCR2.0:新一代光学字符识别模型,轻松转换图像文本
最近,研究人员开发了一种新的通用光学字符识别(OCR)模型,名为 GOT(通用 OCR 理论)。在他们的论文中,首次提出了 “OCR2.0” 的概念,这个新模型旨在将传统 OCR 系统的优点与大型语言模型的强大功能结合起来。
GOT 的架构相当先进,包含了一个大约8000万参数的图像编码器和一个500万参数的解码器。图像编码器能够将1024x1024像素的图像压缩成 tokens,而解码器则负责将这些 tokens 转换成最长可达8000个字符的文本。通过这种方式,OCR2.0模型能够处理的不仅仅是简单的文本。
这项新技术的魅力在于它能够识别并转换多种类型的视觉信息,包括英文和中文的场景文本和文档文本、数学与化学公式、音乐符号、简单几何图形以及包含组件的图表等。这样的功能无疑为科学、音乐和数据分析等领域的自动化处理带来了新的可能性。
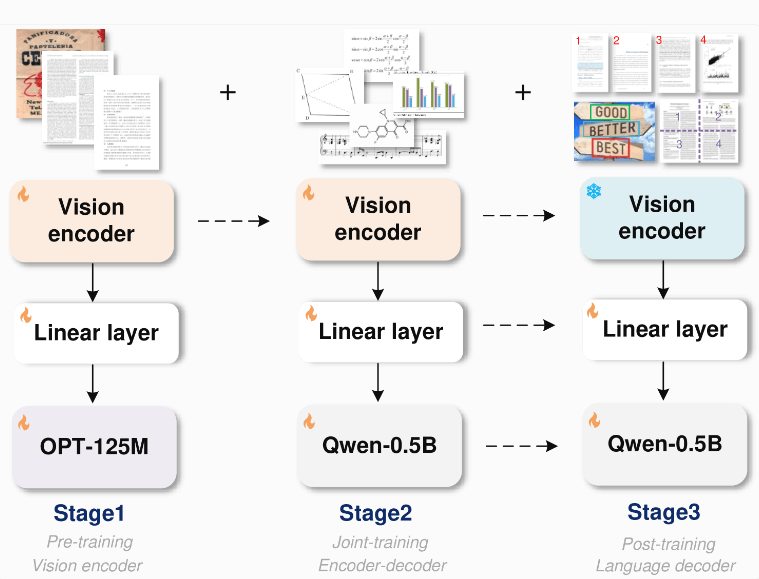
为了优化训练过程,研究团队首先仅针对文本识别任务训练了编码器,随后引入了阿里巴巴的 Qwen-0.5B 作为解码器,并利用多样化的合成数据进行了模型的微调。他们通过使用 LaTeX、Mathpix-markdown-it、TikZ、Verovio、Matplotlib 和 Pyecharts 等渲染工具生成了数百万对图像和文本的训练数据。

GOT 的模块化设计使得未来可以灵活地扩展新功能,而不需要重新训练整个模型,这样的设计大大提高了系统的更新效率。此外,研究者们表示,GOT 在各类 OCR 任务中表现优异,尤其是在文档和场景文本识别方面,甚至在图表识别上超越了一些专用模型和大型语言模型。

值得一提的是,研究团队已将 GOT 的免费演示和代码在 Hugging Face 上发布,供其他人使用和进一步开发。这个新模型无疑将推动 OCR 技术的发展,开启更为广泛的应用前景。
demo入口:https://huggingface.co/spaces/stepfun-ai/GOTofficialonline_demo
划重点:
📌 GOT(通用 OCR 理论)是一种新型 OCR 模型,将传统 OCR 系统与大型语言模型相结合,称为 OCR2.0。
📌 该模型能识别和转换多种视觉信息,包括文本、公式、音乐符号和图表,适用领域广泛。
📌 模块化设计和合成数据训练使 GOT 具备灵活扩展能力,并在多项 OCR 任务中表现出色。