苹果公司最近为其多模态人工智能模型MM1推出了重大更新,将其升级为MM1.5版本。这次升级不仅仅是简单的版本号变更,而是全方位的能力提升,使得模型在各个领域都展现出了更强大的性能。
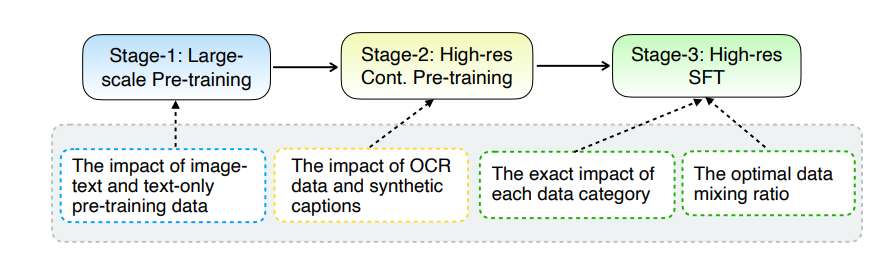
MM1.5的核心升级在于其创新的数据处理方法。该模型采用了以数据为中心的训练方法,精心筛选和优化了训练数据集。具体而言,MM1.5使用了高清晰度的OCR数据和合成图像描述,以及优化的视觉指令微调数据混合。这些数据的引入使得模型在文字识别、图像理解和执行视觉指令等方面都有了显著提升。
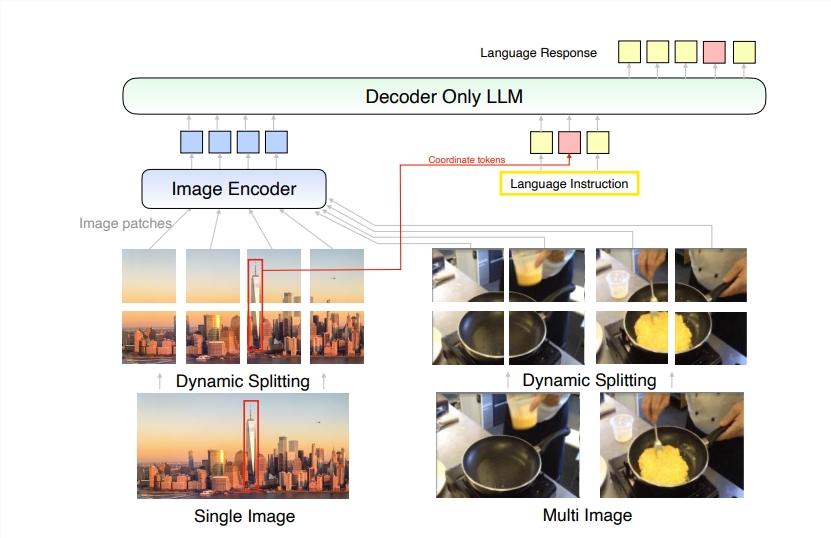
在模型规模方面,MM1.5涵盖了从10亿到300亿参数不等的多个版本,包括密集型和专家混合(MoE)变体。值得注意的是,即使是较小规模的10亿和30亿参数模型,通过精心设计的数据和训练策略,也能达到令人印象深刻的性能水平。
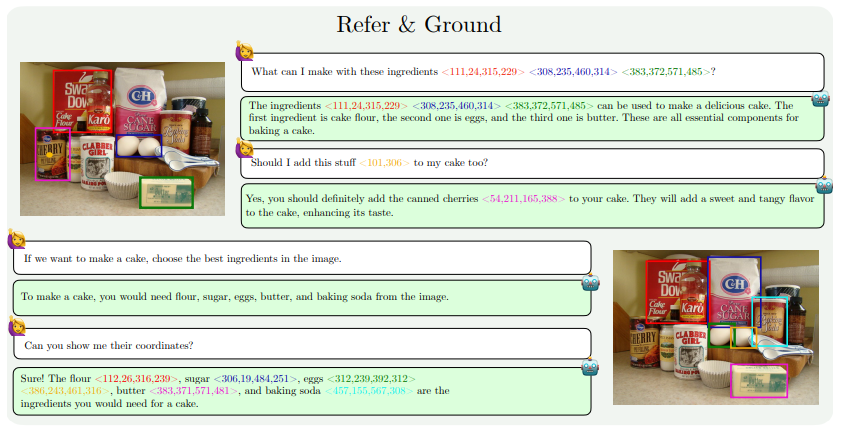
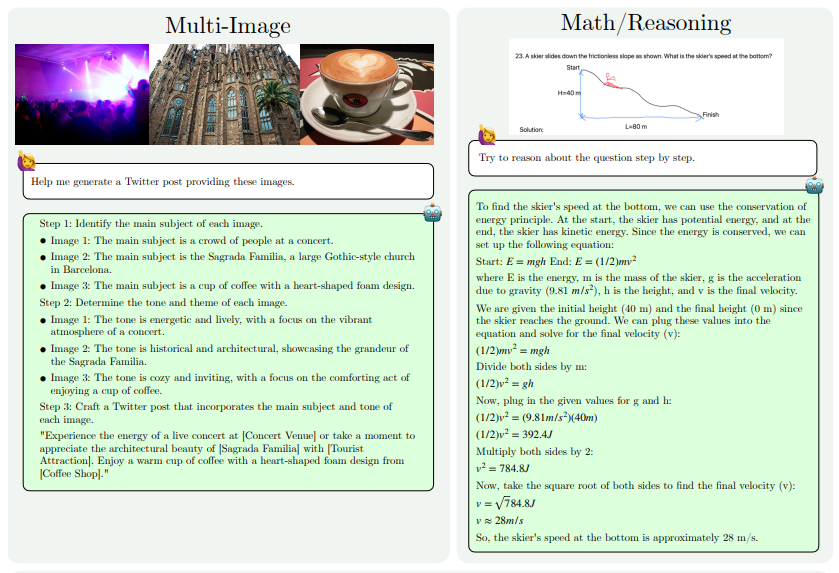
MM1.5的能力提升主要体现在以下几个方面:文本密集型图像理解、视觉指代和定位、多图像推理、视频理解以及移动UI理解。这些能力使得MM1.5可以应用于更广泛的场景,如从音乐会照片中识别表演者和乐器、理解图表数据并回答相关问题、在复杂场景中定位特定物体等。
为了评估MM1.5的性能,研究人员将其与其他先进的多模态模型进行了对比。结果显示,MM1.5-1B在10亿参数规模的模型中表现出色,明显优于同级别的其他模型。MM1.5-3B的表现超越了MiniCPM-V2.0,并与InternVL2和Phi-3-Vision不相上下。此外,研究还发现,无论是密集型模型还是MoE模型,随着规模的扩大,性能都会显著提升。
MM1.5的成功不仅体现了苹果公司在人工智能领域的研发实力,也为多模态模型的未来发展指明了方向。通过优化数据处理方法和模型架构,即使是较小规模的模型也能实现强大的性能,这对于在资源受限的设备上部署高性能AI模型具有重要意义。
论文地址:https://arxiv.org/pdf/2409.20566