最近AI圈子发生了一件怪事,就像一个吃播博主突然开始吃自己做的菜,而且越吃越上瘾,菜也越来越难吃。这事儿说起来还挺吓人,专业的术语叫模型崩溃(model collapse)。
模型崩溃是啥?简单来说,就是AI模型在训练过程中,如果大量使用自己生成的数据,就会陷入一个恶性循环,导致模型生成的质量越来越差,最终完犊子。
这就像一个封闭的生态系统,AI模型就是这个系统里的唯一生物,它生产的食物就是数据。一开始,它还能找到一些天然的食材(真实数据),但随着时间的推移,它开始越来越依赖自己生产的“人造”食材(合成数据)。问题是,这些“人造”食材营养不良,而且还带有模型自身的一些缺陷。吃多了,AI模型的“身体”就垮了,生成的东西也越来越离谱。
这篇论文就研究了模型崩溃现象,并试图回答两个关键问题:
模型崩溃是不可避免的吗?能不能通过混合真实数据和合成数据来解决问题?
模型越大,是不是越容易崩溃?
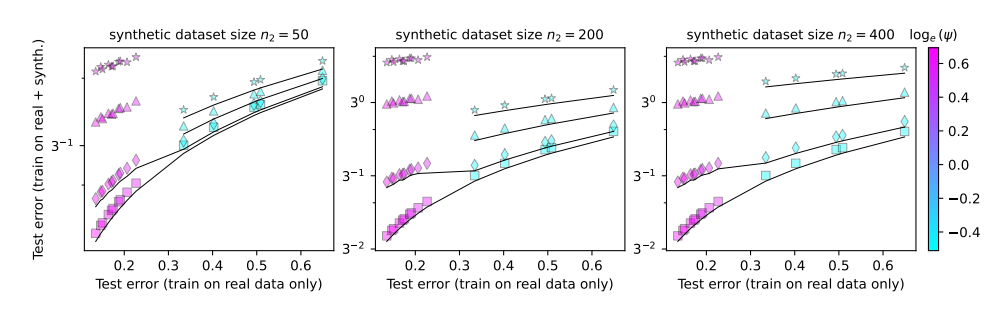
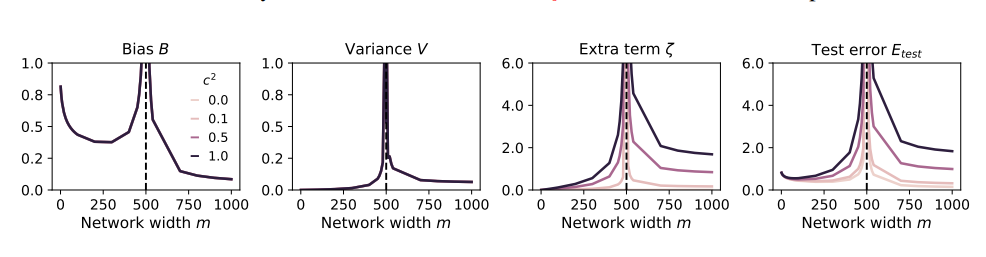
为了研究这些问题,论文作者们设计了一系列实验,并用随机投影模型来模拟神经网络的训练过程。他们发现,就算只使用一小部分合成数据(比如1%),也可能导致模型崩溃。更糟糕的是,随着模型规模的增大,模型崩溃的现象会更加严重。
这就好比吃播博主为了吸引眼球,开始尝试各种奇葩食材,结果吃坏了肚子。为了挽回损失,他只能加大食量,吃更多更奇葩的东西,结果肚子越来越糟糕,最终只能退出吃播界。
那么,我们应该如何避免模型崩溃呢?
论文作者们提出了一些建议:
优先使用真实数据:真实数据就像天然食材,营养丰富,是AI模型健康成长的关键。
谨慎使用合成数据:合成数据就像人造食材,虽然可以补充一些营养,但不能过度依赖,否则会适得其反。
控制模型规模:模型越大,胃口就越大,越容易吃坏肚子。在使用合成数据时,要控制模型的规模,避免过度喂养。
模型崩溃是AI发展过程中遇到的一个新挑战,它提醒我们,在追求模型规模和效率的同时,也要关注数据的质量和模型的健康。只有这样,才能让AI模型持续健康地发展,为人类社会创造更大的价值。
论文:https://arxiv.org/pdf/2410.04840