在数字化时代,将图像中的文字内容快速转换成可编辑文本是一个常见且重要的需求。现在,一项名为GOT(通用光学字符识别理论)的新型光学字符识别(OCR)模型的问世,标志着OCR技术迈入了2.0时代。这一创新模型结合了传统OCR系统与大型语言模型的优势,旨在打造一个更高效、更智能的文本识别工具。
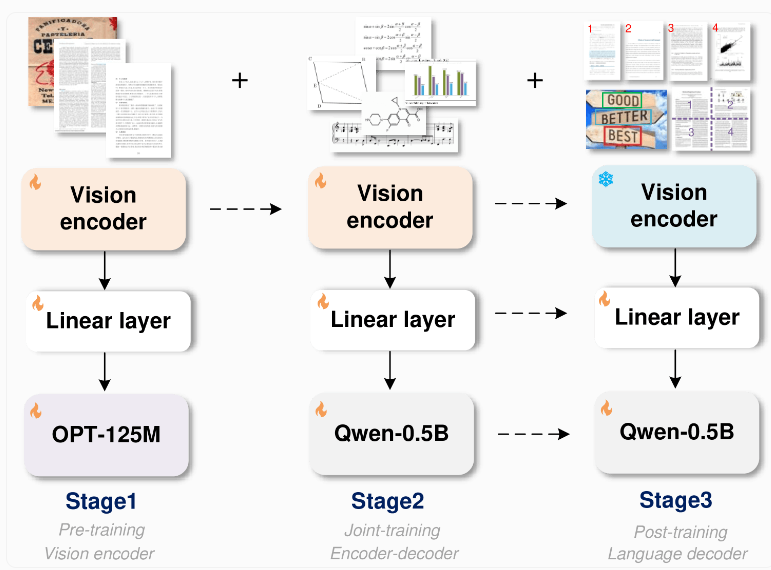
GOT模型采用了一种创新的端到端架构,这一设计不仅节省资源,还极大地扩展了识别能力,使其不仅限于文本识别。该模型由一个参数约8000万的图像编码器和一个参数约500万的解码器组成。图像编码器能够将高达1024x1024像素的图像压缩成数据单元,而解码器则将这些数据转换为长达8000字符的文本。
GOT的强大之处在于其全能性,不仅能识别转换英文和中文文档及场景文本,还能处理数学化学公式、音乐符号、简单几何图形及各种图表。这使得GOT成为一个真正的多面手。
为了训练这一模型,研究团队首先集中于文本识别任务,然后采用阿里巴巴的Qwen-0.5B作为解码器,并通过多种合成数据进行微调。他们使用LaTeX、Mathpix-markdown-it和Matplotlib等专业渲染工具生成了数百万图像-文本对,用于模型训练。

OCR2.0技术的另一大亮点是其能够提取格式化文本、标题,甚至多页图像,并将其转换为结构化的数字格式。这为科学、音乐和数据分析等领域的自动处理和分析提供了新的可能性。
在各种OCR任务的测试中,GOT展现了卓越的性能,在文档和场景文本识别方面取得了行业领先成绩,甚至在图表识别方面也超越了许多专业模型和大型语言模型。无论是复杂的化学结构公式,还是音乐符号和数据可视化,OCR2.0都能准确捕捉并转换为机器可读格式。
为了让更多用户能够体验并利用这一技术,研究团队在Hugging Face平台上发布了免费的演示和代码。OCR2.0的到来,无疑为信息处理领域带来了一场革命,它不仅提高了效率,还增加了灵活性,让我们对图像中的文字信息处理更加得心应手。