最近,超长上下文窗口的大型语言模型(LLMs)成为了人们讨论的热点。这些模型能够在一个提示中处理数十万甚至上百万个标记,为开发者开启了许多新的可能性。不过,这些长上下文 LLM 到底能多好地理解和利用所接收到的大信息呢?
为了解决这个问题,谷歌 DeepMind 的研究人员推出了名为 Michelangelo 的新基准,旨在评估长上下文推能力。
研究结果表明,尽管当前的顶尖模型在从大量上下文数据中提取信息方面取得了一定进展,但在需要推理和理解数据结构的任务上仍然存在困难。
随着长上下文窗口的 LLM 逐渐涌现,研究人员开始意识到,需要新的基准来评估这些模型的能力。现有的评估多集中在信息检索任务上,比如 “从干草堆中找针” 的评估,即在大量上下文中寻找特定的信息。然而,简单的检索并不等同于模型对整体上下文的理解。
为了解决这些问题,Michelangelo 提出了一种全新的评估方法,通过设置复杂的任务,要求模型在处理长文本时进行更深入的推理和综合。例如,该评估框架中包含多个与编程和自然语言相关的任务,这些任务不仅考验模型的记忆能力,更注重其理解和处理信息的深度。
在 Michelangelo 的评估任务中,模型需解决三种基本的长文档综合任务,分别是 “潜在列表”、“多轮共指消解” 和其他多种应用场景。这些任务不仅有助于评估模型在长文档中的表现,还能揭示其在推理和综合方面的不足之处。
第一项是 “潜在列表”,模型需要处理一长串对 Python 列表的操作,过滤掉无关的或冗余的语句,以确定列表的最终状态。
第二项是 “多轮指代解析”,模型需在长对话中理解对话结构并解决引用问题。
第三项是 “我不知道”,模型在回答多个选择题时,需要判断上下文中是否包含答案,并能够准确回应 “我不知道”。
研究人员在Michelangelo 上面对十个顶尖的 LLM(包括不同版本的 Gemini、GPT-4和 Claude)进行评估,他们在多达100万个令牌的上下文中测试了模型。Gemini 模型在 MRCR 上表现最好,GPT 模型在 Latent List 上表现出色,Claude3.5Sonnet 在 IDK 上获得最高分。
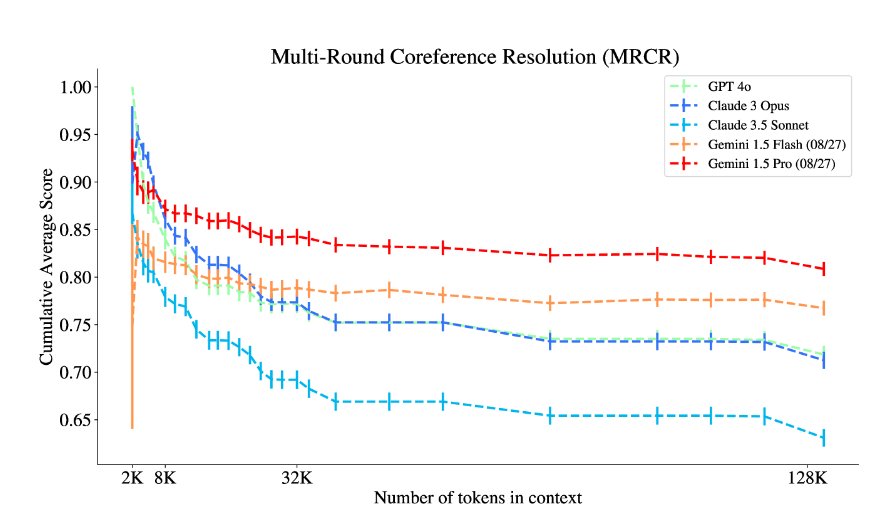
研究人员发现尽管这些模型在处理长上下文方面表现各异,但它们在面对更复杂的推理任务时,整体性能都有显著下降。
这意味着即便在拥有超长上下文窗口的情况下,目前的 LLM 在推理能力上仍有待提高。
研究人员计划持续扩展 Michelangelo 的评估项目,并希望将其直接开放,供其他研究者测试他们的模型。
论文入口:https://arxiv.org/abs/2409.12640
划重点:
🔍 长上下文 LLM 的新基准 Michelangelo 旨在评估模型的推理能力。
🧩 研究表明现有模型在处理复杂推理任务时存在显著性能下降。
📈 研究人员计划扩展评估项目,以促进模型推理能力的进一步研究。