欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:soraor.com
1、豆包推出Ola Friend智能体耳机:售价1199元
豆包推出Ola Friend智能体耳机,这款集成了人工智能技术的耳机旨在为用户提供一个随时陪伴在耳边的AI朋友。用户可以享受听音乐、学习英语、获取导游服务等多种功能,需要下载豆包APP来充分利用。

【AI摘要:】
🎧 Ola Friend智能体耳机售价1199元,支持智能对话功能。
🤖 Ola Friend耳机是随时陪伴在耳边的AI朋友,提供听音乐、学习英语、导游服务等功能。
📱 用户需下载豆包APP来充分利用Ola Friend耳机的功能,APP支持搜索信息、答疑解惑、激发灵感等多种功能。
2、vivo发布全新蓝心大模型矩阵
vivo在2024vivo开发者大会上发布了全新蓝心大模型矩阵,升级了语言、语音、图像和多模态能力,提供更强大的性能和功能。新的蓝心大模型矩阵将行业标准提升至新高度,为用户带来更优质的体验。
【AI摘要:】
🚀 蓝心大模型矩阵全面升级,包括语言、端侧、语音、图像和多模态大模型。
💡 推出30亿蓝心端侧大模型3B,性能提升300%,功耗优化46%,内存减小63%,出词速度达80字/s。
🔊 新自研蓝心语音大模型支持自然语义理解、情感表达和同声传译,图像&多模态大模型强化中国特色与东方美学融合生成能力。
3、开源版NotebookLM来了!Podcastfy:输入PDF、文本、网址等即可转换成播客
在数字时代,制作引人入胜的多语言音频内容成为热门话题。谷歌的NotebookLM备受好评,而开源Python软件包Podcastfy引起广泛关注。Podcastfy是开源版NotebookLM,采用先进的生成式人工智能技术,让用户实现更多个性化和规模化的播客制作。
【AI摘要:】
🌟 Podcastfy是开源Python软件包,可将文本和网络内容转换为多语言音频对话。
🎧 用户可以通过Gradio演示应用或HuggingFace体验Podcastfy,操作简单易上手。
⚠️ 使用外部内容时,需确保拥有版权和权限,生成的音频内容由AI生成,不模仿现实人物。
详情链接:https://github.com/souzatharsis/podcastfy-demo?tab=readme-ov-file
4、图像修复新魔法!突破性算法PMRF
PMRF(后验均值修正流)算法是图像处理领域的一项创新技术,解决了图像恢复中失真与感知质量之间的矛盾,开辟了高质量图像重建的新可能。其独特之处在于在多种图像恢复任务中展现卓越性能,取得了令人瞩目的成绩,平衡了失真和感知质量。
【AI摘要:】
✨ PMRF算法巧妙结合后验均值预测和修正流模型,创造全新图像恢复框架,最大程度减少失真,提升感知质量。
🌟 应用广泛,涵盖去噪、超分辨率、修复受损区域和颜色恢复等多个方面,生成自然真实图像。
💡 在基准和真实数据集测试中,PMRF表现优异,平衡失真和感知质量,树立新的图像恢复标准。
详情链接:https://huggingface.co/spaces/ohayonguy/PMRF
5、沃尔玛推出新型人工智能模型 Wallaby
沃尔玛最近推出了名为Wallaby的大型语言模型,专注于零售行业数据,旨在提升客户服务体验。他们采用多模型组合的方法,灵活应对不同应用需求。升级后的客户支持助手能够更精准地理解客户意图,提供个性化服务。
【AI摘要:】
✨ 沃尔玛推出 Wallaby 大型语言模型,专注于零售行业数据,旨在提升客户服务体验。
🤖 沃尔玛采用多模型组合的方法,灵活应对不同应用需求。
🛍️ 升级后的客户支持助手能够更精准地理解客户意图,提供个性化服务。
6、夸张!GPT-4无意中掌握面部识别技术,准确率超越专业算法
最近的研究显示,GPT-4具备了面部识别、性别判断和年龄估算能力,准确率超越专业算法,但存在安全隐患。研究揭示了绕过GPT-4安全机制的方法,引发了对大型语言模型安全性的思考。尽管GPT-4在生物识别任务表现出色,研究作者警告不能完全依赖其识别能力。
【AI摘要:】
🌟 GPT-4在性别识别测试中达到了100%的完美准确率,超越了DeepFace模型。
📊 GPT-4的年龄估算准确率为74.25%,但对年长者的估算可能较宽泛。
🔒 研究发现可绕过GPT-4的安全机制,需加强对大型语言模型安全性的研究。
7、200万用户量!Hugging Face旗下Gradio5发布:用自然语言轻松构建AI应用
Hugging Face旗下Gradio5发布,致力于简化AI开发,提供企业级安全性和AI Playground功能,进一步推动AI应用开发体验。
【AI摘要:】
🌟 Gradio5引入企业级安全性,确保应用安全无忧。
🚀 新增的AI Playground功能,简化开发流程,让生成应用变得轻松。
🔮 Hugging Face规划未来,推出多种新功能,进一步提升AI应用开发体验。
详情链接:https://www.gradio.app/
8、OpenAI 申请法庭驳回马斯克诉讼,称其为 “骚扰” 行为
在这篇文章中,OpenAI向法庭申请驳回马斯克对公司的诉讼,称其为“骚扰”行为。文章揭示了马斯克和OpenAI之间的法律纠纷背景,强调马斯克的指控缺乏证据,并质疑他的法律地位。
【AI摘要:】
🌟 马斯克对 OpenAI 的多项诉讼被 OpenAI 称为 “骚扰”,并申请驳回。
📉 OpenAI 强调马斯克的指控缺乏证据,称其为不切实际的主张。
⚖️ 马斯克声称 OpenAI 未遵循创始协议的承诺,但法律上被质疑无权提出此类指控。
9、Zoom推数字分身功能:便利还是隐忧?
Zoom计划推出数字分身功能引发了人们对于深度伪造技术的担忧。虽然这项功能能提高视频创作效率,但也可能带来虚假信息传播的风险。
【AI摘要:】
✨ Zoom计划推出数字分身功能,将用户视频转化为AI驱动的逼真数字化身,提高异步交流效率。
💡 深度伪造技术的普及使得区分真相和虚假信息变得困难,可能导致虚假视频的滥用。
🔒 Zoom对安全措施描述模糊,仍需加强保护措施以防止恶意虚假视频的生成。
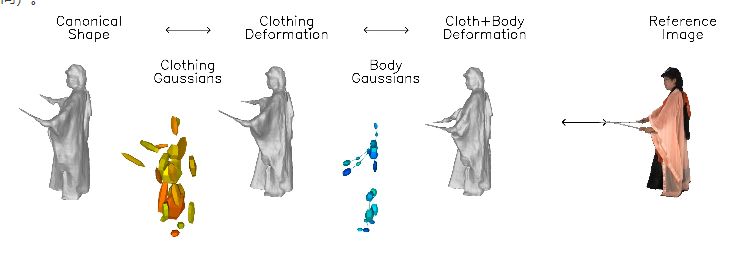
10、DressRecon:输入视频就能构建出还原服装细节的3D模型
近日,卡内基梅隆大学的研究团队发布了名为“DressRecon”的新技术,通过单目视频实现高质量的人体重建,尤其适用于宽松衣物和手持物体的场景。该技术利用神经隐式模型将身体与衣物变形分开处理,借助图像基础的先验知识捕捉细微几何特征。重建结果生成高保真的三维模型,支持从任意角度渲染,提升了可视化体验。
【AI摘要:】
👗 研究团队推出DressRecon技术,通过单目视频实现高质量的人体重建,特别适用于宽松衣物和手持物体的场景。
📷 该技术利用神经隐式模型将身体与衣物变形分开处理,借助图像基础的先验知识来捕捉细微几何特征。
🎥 重建结果不仅生成高保真的三维模型,还支持从任意角度渲染,提升了可视化体验。
详情链接:https://jefftan969.github.io/dressrecon/
11、DreamWaltz-G:从文本生成生动的3D 可动画头像
在数字化时代,个性化的虚拟形象受到关注。DreamWaltz-G框架通过结合骨骼引导的得分蒸馏和混合3D高斯表示,提升了头像生成的一致性和动画表现力。该框架支持形状控制、视频重演和多主体场景构建,拓展了数字内容创作的可能性。

【AI摘要:】
📌 创新框架DreamWaltz-G能根据文本描述生成生动的3D可动画头像。
🎨 结合骨骼引导的得分蒸馏和混合3D高斯表示,提升头像生成的一致性和动画表现力。
🎥 支持形状控制、视频重演和多主体场景构建,拓展了数字内容创作的可能性。