最近大语言模型(LLM)发展迅猛,其中Transformer模型功不可没。Transformer的核心是注意力机制,它像一个信息过滤器,让模型关注句子中最重要的部分。但即使是强大的Transformer,也会被无关信息干扰,就好比你在图书馆想找本书,结果被一堆无关的书淹没,效率自然低下。
这种注意力机制产生的无关信息,在论文中被称为注意力噪音。想象一下,你想在文件中找一个关键信息,结果Transformer模型的注意力却分散到各种无关的地方,就像一个近视眼,看不清重点。
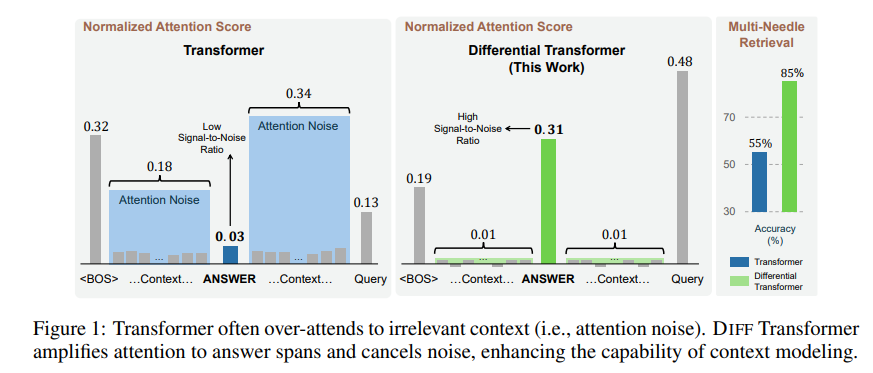
为了解决这个问题,这篇论文提出了Differential Transformer (DIFF Transformer)。这个名字很高级,但原理其实很简单,就像降噪耳机一样,通过两个信号的差异来消除噪音。
Differential Transformer 的核心是差分注意力机制。它把查询和键向量分成两组,分别计算两个注意力图,再将这两个图相减,得到最终的注意力分数。这个过程就像用两台相机分别拍摄同一个物体,然后将两张照片叠加,差异的地方就会凸显出来。
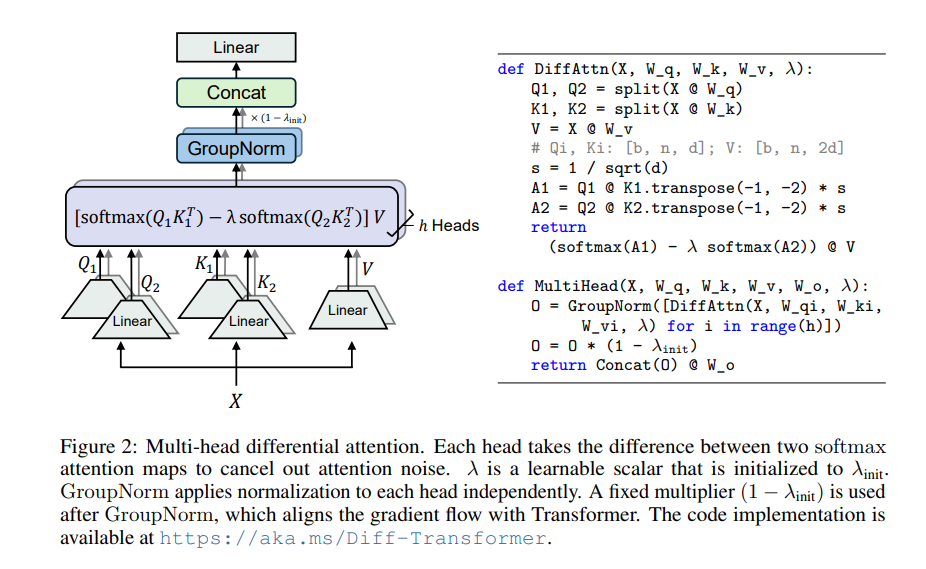
通过这种方式,Differential Transformer 能够有效地消除注意力噪音,让模型更加专注于关键信息。就好比你戴上降噪耳机,周围的噪音消失了,你就能更清晰地听到想要的声音。
论文中进行了一系列实验,证明了Differential Transformer 的优越性。首先,它在语言建模方面表现出色,只需要Transformer65% 的模型大小或训练数据,就能达到类似的效果。
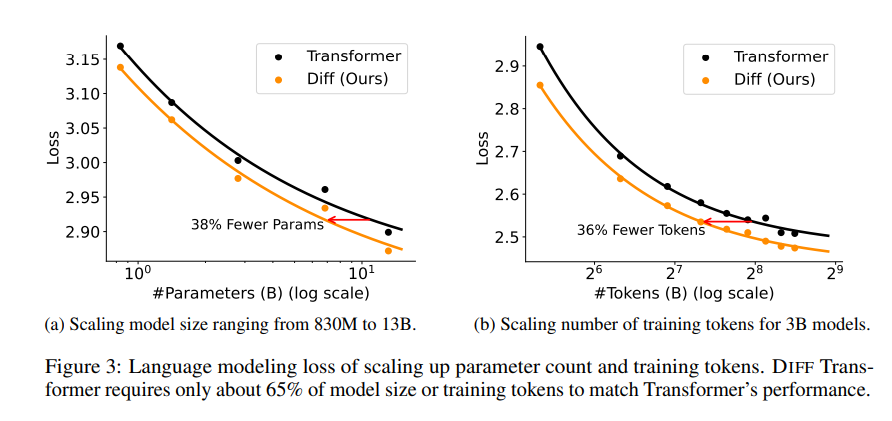
其次,Differential Transformer 在长文本建模方面也更胜一筹,能够有效地利用更长的上下文信息。
更重要的是,Differential Transformer 在关键信息检索、减少模型幻觉和上下文学习方面表现出显著优势。
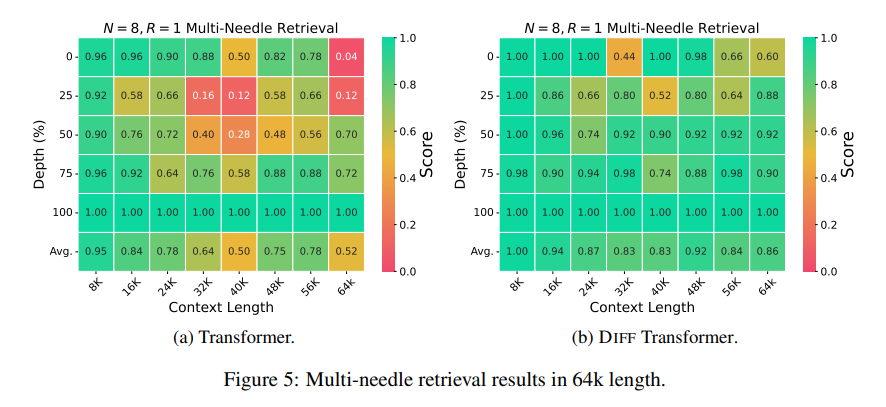
在关键信息检索方面,Differential Transformer 就像一个精准的搜索引擎,能够在海量信息中准确地找到你想要的内容,即使是在信息极其复杂的场景下,也能保持高准确率。
在减少模型幻觉方面,Differential Transformer 能够有效地避免模型“胡说八道”,生成更准确、更可靠的文本摘要和问答结果。
在上下文学习方面,Differential Transformer 更像是学霸,能够快速地从少量样本中学习新知识,而且学习效果也更加稳定,不像Transformer那样容易受到样本顺序的影响。
此外,Differential Transformer 还能有效地降低模型激活值中的异常值,这意味着它对模型量化更友好,可以实现更低比特的量化,从而提高模型的效率。
总而言之,Differential Transformer 通过差分注意力机制有效地解决了Transformer模型的注意力噪音问题,并在多个方面取得了显著的改进。它为大语言模型的发展提供了新的思路,未来将会在更多领域发挥重要作用。
论文地址:https://arxiv.org/pdf/2410.05258