10月2日消息,美东时间10月1日OpenAI举行了年度开发者大会DevDay,推出系列新工具,包括四大创新:实时API(Realtime API)、视觉微调(Vision Fine-Tuning)、提示词缓存(Prompt Caching)、模型蒸馏(Model Distillation),为开发者带来在降低模型成本、提高模型视觉理解水平、提升语音AI功能和小模型性能的新选择。在OpenAI官网主要,上述功能介绍已经做了全面更新,一起看看。

实时 API(Realtime API)
OpenAI DevDay发布了Realtime API,目前处于公开测试beta阶段。
Realtime API 能够构建低延迟、多模式对话体验。它目前支持文本和音频作为输入和输出,以及函数调用。Realtime API 中的音频功能由新的 GPT-4o 模型“gpt-4o-realtime-preview”提供支持。

通过此更新,开发人员可以将任何文本或音频输入传递到 GPT-4o,并让模型以他们选择的文本、音频或两者做出响应。
本质上,Realtime API 简化了构建语音助手和其他对话式 AI 工具的过程,无需将多个模型拼接在一起进行转录、推理和文本到语音的转换。
Realtime API 定价方面,Realtime API 同时使用文本tokens和音频tokens。文本输入tokens的价格为5 美元/百万tokens,输出tokens的价格为20 美元/百万tokens。音频输入的价格为100 美元/百万tokens,输出的价格为200美元/百万tokens。这相当于每分钟音频输入约 0.06 美元,每分钟音频输出约 0.24 美元。
视觉微调(Vision Fine-Tuning)
OpenAI DevDay公布,OpenAI最新的大语言模型(LLM) GPT-4o 引入了视觉微调。此功能让开发人员可以自定义模型以获得更强大的图像理解能力,从而实现增强的视觉搜索功能、改进的自动驾驶汽车或智能城市的物体检测以及更准确的医学图像分析等应用。
视觉微调遵循与文本微调类似的过程——开发人员可以准备他们的图像数据集,然后将该数据集上传到Open AI的平台。他们可以用少至 100 张图像来提高 GPT-4o 在视觉任务中的性能,并使用更大量的文本和图像数据来提高性能。
OpenAI举例称,东南亚食品配送和拼车公司Grab已经利用这项技术改进其地图服务。仅使用 100 个示例进行视觉微调,教会 GPT-4o 正确定位交通标志并计算车道分隔线以优化其地图数据,结果,与基础 GPT-4o 模型相比,Grab 能够将车道计数准确度提高 20%,限速标志定位率提高13%。
价格方面,截至 2024年10月31日,OpenAI每天免费提供100万tokens,以使用图像微调 GPT-4o。2024 年 10 月 31 日之后,GPT-4o 微调训练将花费每 100 万tokens 25 美元,推理将花费每 100 万个输入tokens 3.75 美元和每 100 万个输出tokens 15 美元。图像输入首先根据图像大小进行标记,然后按与文本输入相同的每令牌费率定价。
提示词缓存(Prompt Caching)
提示词缓存被视为本次DevDay发布的最重要更新。该功能旨在降低开发者的成本、减少延迟。
许多开发人员在构建 AI 应用程序时,会在多个 API 调用中重复使用相同的上下文,例如在编辑代码库或与聊天机器人进行长时间的多轮对话时。今天,我们推出了提示词缓存(Prompt Caching),让开发人员可以降低成本和延迟。通过重复使用最近处理的输入token,开发人员可以获得 50% 的折扣和更快的提示词处理时间。
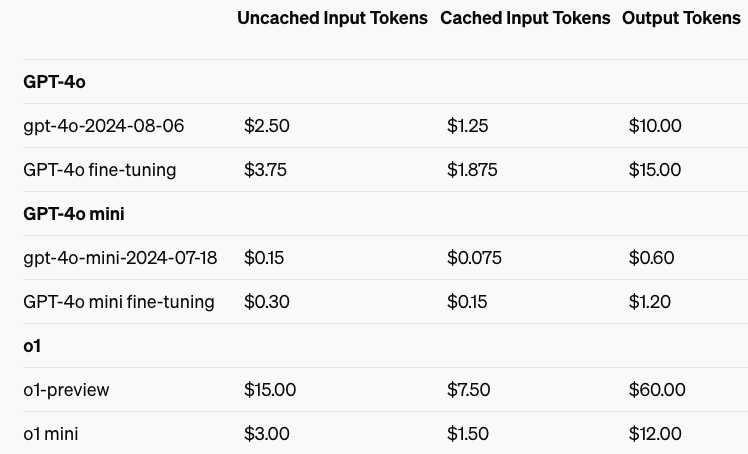
目前,提示词缓存(Prompt Caching)已自动应用于最新版本的 GPT-4o、GPT-4o mini、o1-preview 和 o1-mini,以及这些模型的微调版本。与未缓存的提示相比,缓存的提示可享受折扣。
模型蒸馏(Model Distillation)
OpenAI 推出了一款新的模型蒸馏产品,为开发人员提供集成的工作流程,以直接在 OpenAI 平台内管理整个蒸馏流程。
这让开发人员可以轻松使用前沿模型(如 o1-preview 和 GPT-4o)的输出来微调和提高更具成本效益的模型(如 GPT-4o mini)的性能,让小模型也可拥有尖端模型功能。
这种方法让小公司也可能利用与尖端模型类似的功能,并且无需承担使用这类模型的计算成本。例如一家从事医疗技术的小型初创公司要为农村的诊所开发一种AI 驱动的诊断工具。使用模型蒸馏,该公司可以训练一个紧凑的模型,该模型可以捕捉大模型的大部分诊断能力,同时只需要在标准的笔记本电脑或平板电脑上运行。