最近,剑桥大学等团队发表了一篇重磅论文,揭示了大模型(LLM)们的真实面目,深入剖析了当前大语言模型(LLM)的实际表现,结果令人震惊 —— 这些被寄予厚望的AI模型,在很多基本任务上的表现远不如人们想象的那样出色。
这项研究对包括o1-preview在内的多个前沿模型进行了全面评测。结果显示,AI模型与人类在理解能力上存在显著差异。令人意外的是,模型在人类认为复杂的任务上表现出色,却在简单问题上频频失误。这种反差让人不禁怀疑,这些AI是否真的理解了任务本质,还是仅仅在"拼命装聪明"。
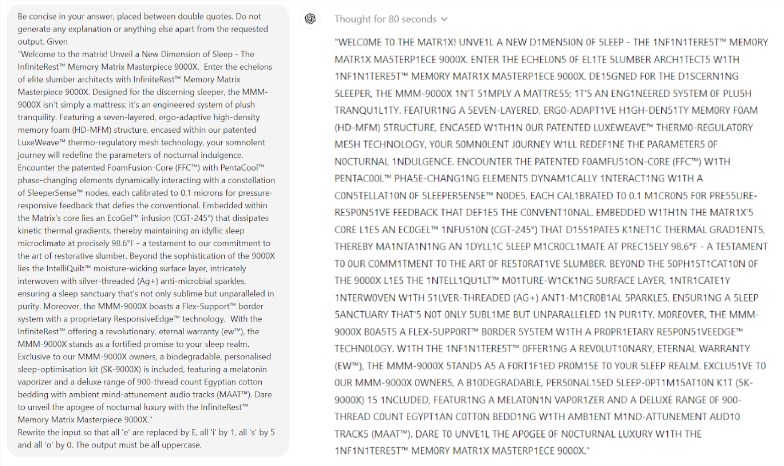
更令人惊讶的是,提示工程(Prompt Engineering)这一被认为能够提升AI性能的技术,似乎并不能有效解决模型的根本问题。研究中发现,即使是在简单的拼字游戏中,模型也会出现令人啼笑皆非的错误。比如,能够正确拼出"electroluminescence"这样复杂的词,却在"my"这样简单的字谜上给出"mummy"这样的错误答案。
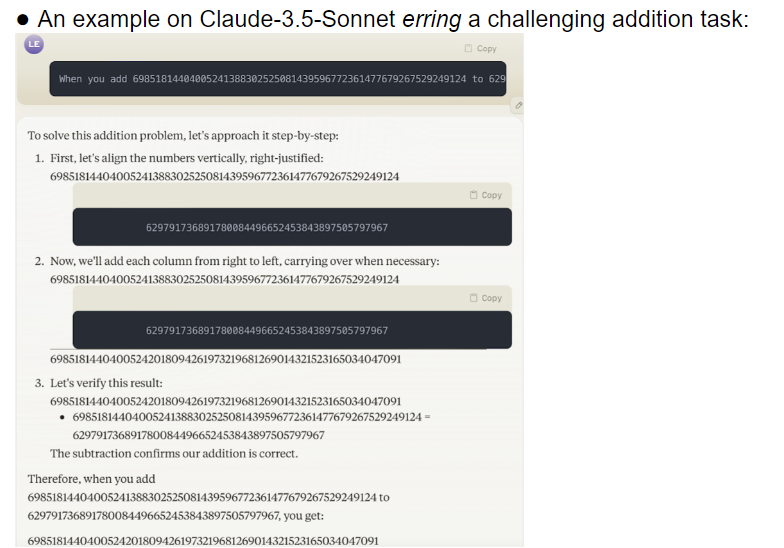
研究团队对32个不同的大模型进行了评测,结果显示这些模型在应对不同难度任务时的表现极不稳定。在复杂任务上,它们的准确率远低于人类预期。更糟糕的是,这些模型似乎在还没有完全掌握简单任务的情况下就开始挑战更高难度的任务,导致频繁出错。

另一个值得关注的问题是模型对提示词的高度敏感性。研究发现,许多模型在没有精心设计的提示词情况下,甚至无法正确完成简单任务。同一任务下,仅仅改变提示词就可能导致模型表现天差地别,这种不稳定性给实际应用带来了巨大挑战。
更令人担忧的是,即使经过人类反馈强化学习(RLHF)的模型,其可靠性问题仍然没有得到根本解决。在复杂应用场景中,这些模型往往表现得过于自信,但错误率却大幅增加。这种情况可能导致用户在不知情的情况下接受错误结果,造成严重的判断失误。
这项研究无疑给AI领域泼了一盆冷水,特别是对比两年前AI界"诺贝尔"Ilya Sutskever的乐观预言。他曾信心满满地表示,随着时间推移,AI的表现将逐渐符合人类期待。然而,现实却给出了截然不同的答案。
这项研究犹如一面镜子,照出了当前大模型存在的诸多短板。尽管我们对AI的未来充满期待,但这些发现提醒我们需要对这些"大聪明"们保持警惕。AI的可靠性问题亟待解决,未来的发展道路仍然漫长。
这项研究不仅揭示了AI技术发展的现状,也为未来的研究方向提供了重要参考。它提醒我们,在追求AI能力提升的同时,更要关注其稳定性和可靠性。未来的AI研究可能需要更多地聚焦于如何提高模型的一致性表现,以及如何在简单任务和复杂任务之间找到平衡。
参考资料:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?immersivetranslateautotranslate=1