在人工智能快速发展的今天,一个名为ORYX的多模态大型语言模型正在悄然改变我们对AI理解视觉世界能力的认知。这个由清华大学、腾讯和南洋理工大学研究人员联合开发的AI系统,堪称视觉处理领域的"变形金刚"。
ORYX,全称Oryx Multi-Modal Large Language Models,是一个专门设计用于处理图像、视频和3D场景时空理解的AI模型。它的核心优势在于能够像人类一样,不仅理解视觉内容,还能洞察内容之间的关联和背后的故事。

这个AI系统的一大亮点是其处理任意分辨率视觉输入的能力。无论是模糊的老照片还是高清视频,ORYX都能轻松应对。这得益于其预训练模型OryxViT,它能将不同分辨率的图像转换为AI可理解的统一格式。
更令人惊叹的是ORYX的动态压缩能力。面对长时间的视频输入,它能够智能地压缩信息,保留关键内容而不失真。这就像是将一本厚重的书精炼成一张内容丰富的便签卡,既保留了核心信息,又大大提高了处理效率。
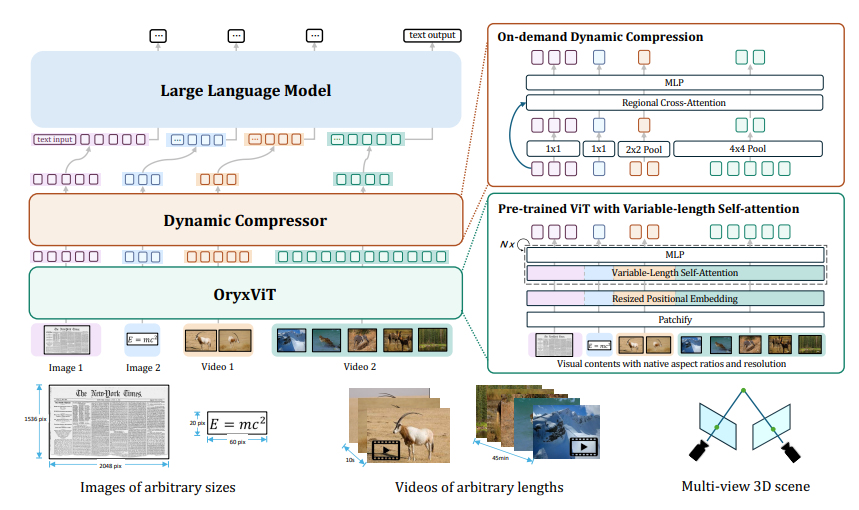
ORYX的工作原理主要依赖于两个核心组件:视觉编码器OryxViT和动态压缩模块。前者负责处理多样化的视觉输入,后者则确保长时间视频等大容量数据能够被高效处理。
在实际应用中,ORYX展现出了惊人的潜力。它不仅能深入理解视频内容,包括对象、情节和动作,还能准确把握3D空间中物体的位置和关系。这种全方位的视觉理解能力,为未来的人机交互、智能监控、自动驾驶等领域带来了无限可能。
值得一提的是,ORYX在多个视觉-语言基准测试中表现卓越,尤其在图像、视频和多视图3D数据的空间和时间理解方面,展现出了领先优势。
ORYX的创新之处不仅在于其强大的处理能力,更在于它为AI视觉理解开辟了新的范式。它能够以原生分辨率处理视觉输入,同时通过动态压缩技术高效处理长视频,这种灵活性和效率是其他AI模型难以企及的。
随着技术的不断进步,ORYX有望在未来的AI领域扮演更加重要的角色。它不仅将帮助机器更好地理解我们的视觉世界,还可能为人类认知过程的模拟提供新的思路。
论文地址:https://arxiv.org/pdf/2409.12961