腾讯优图实验室与上海交通大学的研究团队联手推出了一项革命性的知识增强方法,为大模型优化开辟了全新道路。这项创新技术摒弃了传统模型微调的局限,直接从开源数据中提取知识,大幅简化了模型优化流程,在多项任务中实现了超越现有最先进技术(SOTA)的卓越表现。
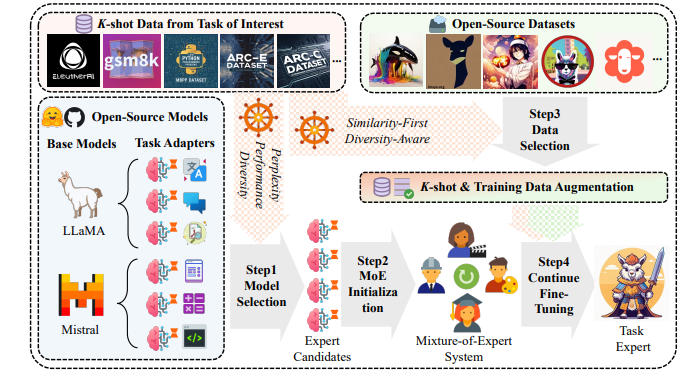
近年来,大型语言模型(LLMs)虽然在各领域取得了显著进展,但在实际应用中仍面临着诸多挑战。传统的模型微调方法需要大量标注数据和计算资源,这对许多实际业务而言往往难以实现。尽管开源社区提供了丰富的微调模型和指令数据集,但如何在有限标注样本的情况下有效利用这些资源,提升模型的任务能力和泛化性能,一直是业界面临的难题。
针对这一问题,研究团队提出了一种新颖的实验框架,专注于在K-shot有标签的真实业务数据条件下,利用开源知识增强模型能力。这一框架充分发挥了有限样本的价值,为大型语言模型提供了定向任务的性能提升。
该研究的核心创新点包括:
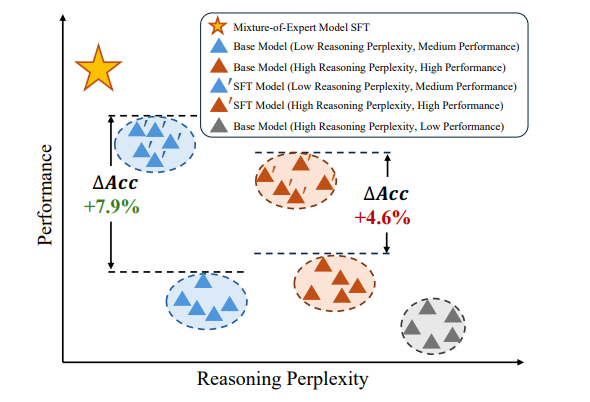
高效模型选择:通过综合评估推理困惑度、模型表现及知识丰富度,在有限数据条件下最大化现有模型潜力。
知识提取优化:设计了从开源数据中提取相关知识的方法,通过平衡相似性与多样性的数据筛选策略,为模型提供补充信息,同时降低过拟合风险。
自适应模型系统:构建了基于混合专家模型结构的自适应系统,实现多个有效模型之间的知识互补,提升整体性能。
在实验阶段,研究团队使用六个开源数据集进行了全面评估。结果显示,这种新方法在各项任务中均优于基线和其他先进方法。通过可视化专家激活模式,研究还发现每个专家对模型的贡献都是不可或缺的,进一步证实了该方法的有效性。
这项研究不仅展示了开源知识在大模型领域的巨大潜力,更为人工智能技术的未来发展提供了新的思路。它突破了传统模型优化的局限,为企业和研究机构在有限资源条件下提升模型性能提供了可行的解决方案。
随着这项技术的不断完善和推广,我们有理由相信,它将在各行各业的智能化升级中发挥重要作用。腾讯优图与上海交通大学的这次合作,不仅是学术界和产业界联手的典范,更是推动人工智能技术走向更高层次的重要一步。
论文地址:https://www.arxiv.org/pdf/2408.15915