近期,社交媒体平台上掀起了一股"再见,Meta AI"的浪潮。众多用户,包括知名人士如汤姆·布雷迪和音乐人猫力量(Cat Power),纷纷在Instagram上发布声明,试图阻止Meta使用他们的数据来训练AI模型。这一现象反映出用户对数据隐私和AI技术应用的深切忧虑,也为科技巨头如何平衡技术创新与用户权益提出了新的挑战。
虽然这些声明在法律上并无约束力,Meta也明确表示这些文本不具有法律效力,但我们不能简单地将其视为用户的无知或天真。相反,这种行为背后折射出的是用户对AI技术快速发展的担忧和对个人数据被滥用的恐惧。
事实上,Meta确实在使用自2007年以来的公开Facebook帖子和照片来训练其AI模型。除非身处欧盟,用户几乎没有选择退出的途径,这无疑加剧了用户的不安全感。这种情况下,用户只能通过将帖子设为私密来保护自己的数据,这显然不是一个理想的解决方案。
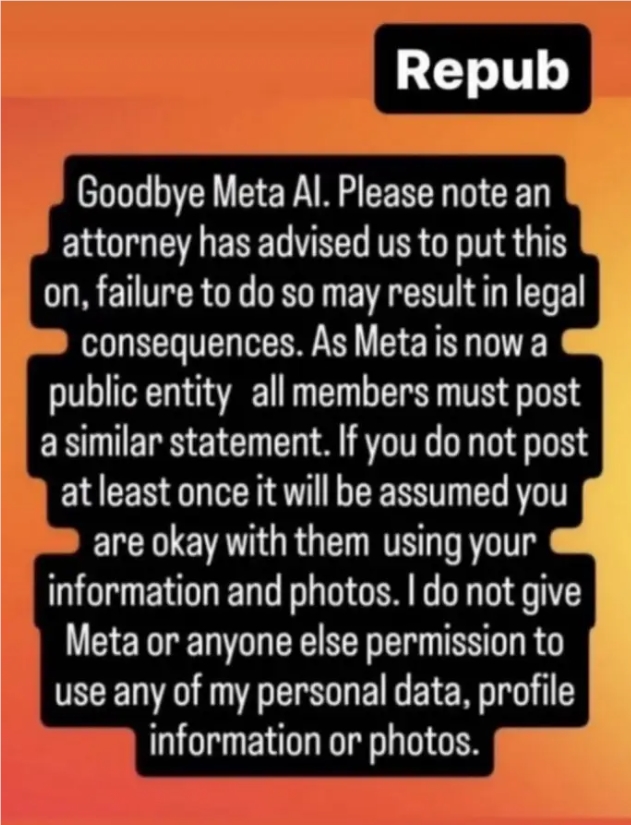
这种在社交媒体上传播的"保护性"声明并非新鲜事。多年来,Facebook和Instagram上时常出现类似的内容,声称可以保护用户免受技术公司的侵犯。尽管这些声明常常被证实是无效的,但它们反映出用户在使用这些平台时感受到的权力失衡。用户享受着免费服务,却又担心自己的数据被不当利用,这种矛盾心理源于Facebook过去在用户隐私保护方面的种种失误。
在即将举行的Meta Connect活动前夕,The Verge记者亚历克斯·希思直接向马克·扎克伯格提出了这个问题。扎克伯格的回应显得有些模糊,他提到在任何新技术领域都会涉及公正使用和控制的边界问题,并表示这些问题在AI时代需要重新讨论和审视。这种回应虽然承认了问题的存在,但并未提供具体的解决方案。
对于Meta来说,如何平衡技术创新与用户权益保护,将是一个长期而艰巨的挑战。公司需要认真倾听用户的声音,理解他们对数据被用于AI训练的担忧。同时,Meta还需要更加透明地解释其数据使用政策,让用户清楚地了解自己的数据将如何被使用,并提供更多的选择权。
此外,业界可能需要重新审视数据使用的伦理标准。在AI快速发展的背景下,如何合理使用用户数据,如何在创新与隐私保护之间找到平衡点,这些都是亟需解决的问题。