声明:本文来自于微信公众号 新智元,作者:新智元,授权Soraor转载发布。
【新智元导读】谷歌的AlphaChip,几小时内就能设计出芯片布局,直接碾压人类专家!这种超人芯片布局,已经应用在TPU、CPU在内的全球硬件中。人类设计芯片的方式,已被AI彻底改变。
能设计芯片的AI黑科技来了!
就在刚刚,谷歌DeepMind推出名为AlphaChip的AI系统。
无论是设计最先进的用于构建AI模型的TPU,还是数据中心的CPU,它在相关的众多领域,都产生了广泛影响。
在谷歌的许多款芯片设计中,它都取得了出色的效果,比如Axion芯片(一种基于Arm 的通用数据中心CPU)。
AlphaChip设计芯片,用的是强化学习的原理。
也就是说,芯片布局设计对它来说是一种游戏,就像AlphaGo一样,它在游戏中,学习如何设计出最好的芯片布局。
几小时内,它就能生成超出人类水平,或是与人类专家相当的芯片布局了。
现在,它已经用于设计多代TPU芯片(TPU v5e、TPU v5p和Trillium)。而且跟人类专家相比,AlphaChip放置的块数越来越多,线长也减少了许多。
布局五年,谷歌多代TPU全由AI设计
其实谷歌对于这个AI,已经布局多年了。
早在2020年,团队就发表了一篇预印本论文,介绍了谷歌的全新强化学习方法,用于设计芯片布局。

论文地址:https://arxiv.org/pdf/2004.10746
后来在2021年,这项工作发表在了Nature上,并且进行了开源。

论文地址:https://www.nature.com/articles/s41586-021-03544-w
而自从首次发表这项工作以来,谷歌内部一直在对它进行改进。
今天,团队发表了Nature附录,详细描述了具体方法,及其对芯片设计领域的影响。
同时,他们还发布了一个预训练的检查点,分享了模型权重,公布模型名称为AlphaChip。
谷歌表示,AlphaChip是最早用于解决现实世界工问题的强化学习方法之一。
在数小时内,它就可以生成超人或类似的芯片布局,而不需要花费数周或数月的人类。它设计的芯片布局,已经被用于世界各地的芯片中,包括数据中心和移动电话。
为了设计TPU布局,AlphaChip首先在来自前几代的各种芯片模块上进行实践,例如片上和片间网络模块、内存控制器和数据传输缓冲区。这一过程被称为预训练。
然后,团队在当前的TPU模块上运行AlphaChip,以生成高质量的布局。
与之前的方法不同,AlphaChip在解决更多芯片布局任务时变得更好、更快,类似于人类专家的工作方式。
对于每一代新的TPU,包括谷歌最新的Trillium(第6代),AlphaChip都设计了更好的芯片布局,并提供了更多的总体布局图,从而加快了设计周期,产生了更高性能的芯片。
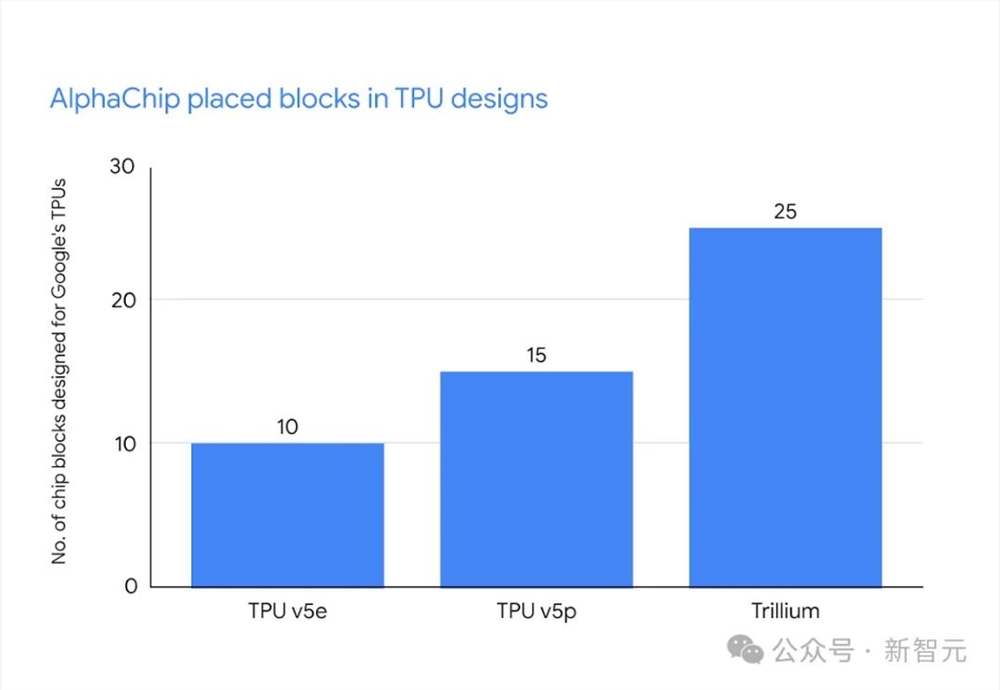
条形图显示了谷歌三代TPU上AlphaChip设计的芯片块的数量,包括v5e、v5p和Trillium
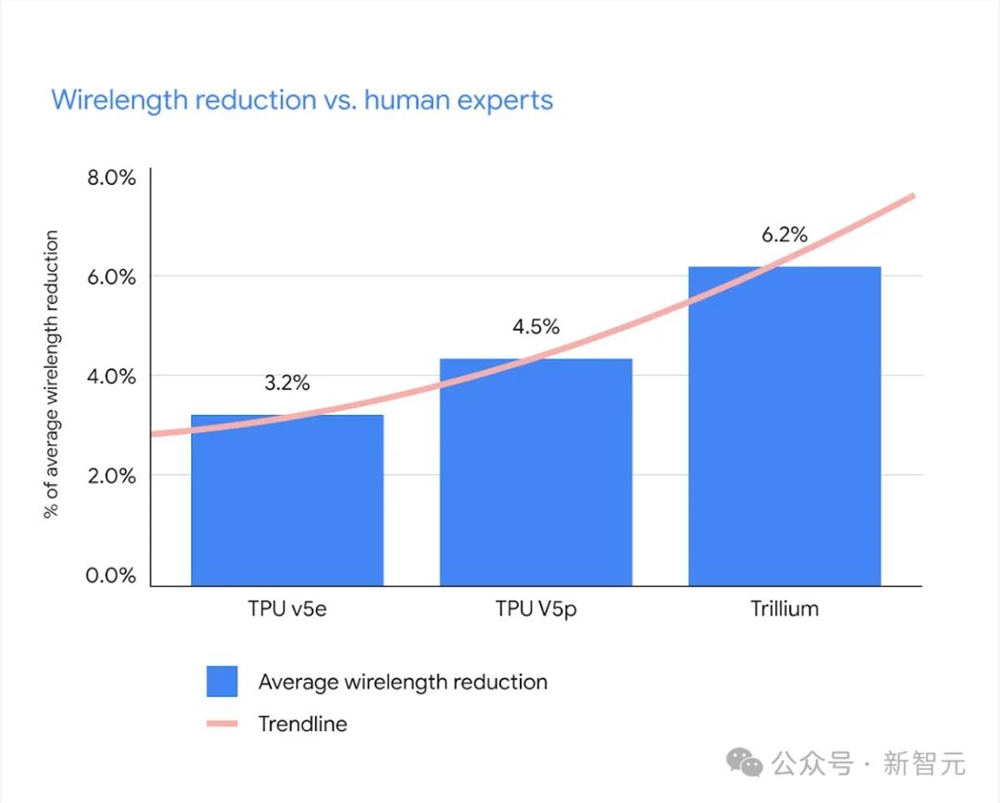
条形图显示,跟TPU物理设计团队生成的布局相比,AlphaChip在TPU三代产品中的平均有线长度减少
工作原理:一边设计,一边奖励
其实,设计芯片布局并不是一项简单的任务。
一般来说,计算机芯片有许多相互连接的模块、多层电路元件组成,所有这些部件都由纤细无比的导线连接起来。
此外,还有许多复杂且相互交织的设计约束,必须同时满足。
由于设计的复杂性,60多年来,芯片设计工程师一直在努力自动化芯片布局规划过程。
谷歌表示,AlphaChip的研发,从AlphaGo和AlphaZero中汲取了经验。
众所周知,通过深度学习和博弈论,AlphaGo和AlphaZero逐渐从0掌握了围棋、国际象棋和将棋的潜在规则。
AlphaChip同样是采用了,将芯片底层规划视为一种游戏的策略。
从空白栅格开始,AlphaChip每次放置一个电路元件,直至放置完所有元件。
然后,根据最终布局的质量,给予模型奖励。
一种全新的「基于边」的图神经网络让AlphaChip,能够学习相互连接的芯片元件之间的关系,并在芯片之间进行泛化,让AlphaChip在设计的每种布局中都有所改进。
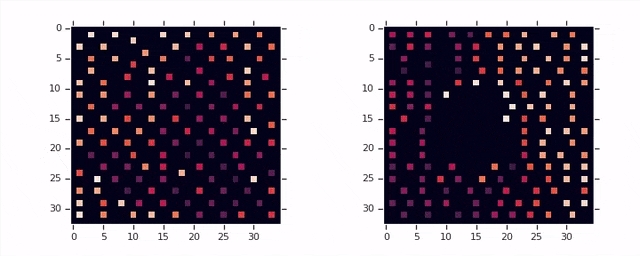
左图:动画显示AlphaChip在没有任何经验的情况下,将开源的Ariane RISC-V CPU置入。右图:动画显示AlphaChip在对20个TPU相关设计进行练习后,放置相同的块。
AI大牛带队,2页浓缩版力作
让我们从最新论文中深扒一下,AlphaChip的整个训练过程。
值得一提的是,这项研究依旧是由Jeff Dean带队,所有核心要素全都浓缩在了这两页论文中。

论文地址:https://www.nature.com/articles/s41586-024-08032-5
与以往方法不同的是,AlphaChip是基于一种「强化学习」的方法。
这意味着,当它解决了更多芯片布局问题的实例时,会变得更好、更快。
正如Nature论文(2021年),以及ISPD2022后续研究中所讨论的那样,这种预训练过程显著提升了AI的速度、可靠性、布局的性能。
顺便提一句,预训练也能培养出LLM,像Gemini、ChatGPT令人印象深刻的能力。
自此前研究发表以来,谷歌便开源了一个软件库,以重现论文中描述的方法。
开发者们可以使用这个库,对各种芯片进行预训练,然后将预训练的模型应用到新的块。

GitHub地址:https://github.com/google-research/circuit_training
基于最新的AlphaChip训练过程,研究人员在库中添加了预训练的20个TPU块模型检查点(checkpoint)。
显然,如果不进行任何预训练,AlphaChip就无法从先前的经验中学习,从而规避了学习方面的问题。
随着RL智能体(任何ML模型)的投入训练,它的损失通常会逐渐减少。
最终会趋于平稳,这代表着模型对其正在执行的任务有了尽可能多的了解,对外表现就是「收敛」。
从训练到收敛,是机器学习的标准做法。如果不按照这个路径来,可能会损害模型的性能。
AlphaChip的性能随应用的计算资源而扩展,在ISPD2022论文中,谷歌团队曾进一步探讨了这一特性。

论文地址:https://dl.acm.org/doi/10.1145/3505170.3511478
正如Nature论文中所描述的,在对特定块进行微调时,使用了16个工作单元,每个单元由1个GPU和32个RL环境组成,通过多进程处理共享10个CPU。
总言之,用较少的计算资源可能会损害性能,或者需要运行相当长的时间,才能实现相同(或更差)性能。
在运行Nature论文中评估方法之前,团队使用了来自物理综合的近似初始布局,以解决hMETIS标准单元集群大小不平衡的问题。
RL智能体无权访问初始布局,并且不复杂放置标准单元。
尽管如此,谷歌作者还是进行了一项消融研究,排除了任何初始布局的使用,并且也没有观察到AlphaChip性能下降。
如下表1所示。
具体来说,他们跳过了单元集群重新平衡的一步,而是将hMETIS集群不平衡参数降低到最低设置(UBfactor =1)。
由此,这使得hMETIS生成更平衡的集群。

在Nature论文中,研究人员采用了10nm以下制程的TPU块进行实验得出的结果。
这个技术节点的大小,正是现代芯片的典型尺寸。之前许多论文报告中,采用较早的45nm、12nm。
从物理设计角度来看,这种较老的技术节点尺寸的芯片,有着显著的不同。
比如,在10nm以下的芯片中,通常使用多重图案设计,这会在较低密度下导致布线拥堵的问题。
来源:Pushing Multiple Patterning in Sub-10nm: Are We Ready?
因此,对于较早的技术节点尺寸,AlphaChip可能需要调整其奖励函数,以便更好地适应技术。
展望未来:AI将改变整个芯片设计流程
自从2020年发布以来,AlphaChip已经生成了每一代谷歌TPU使用的超人芯片布局。
可以说,正是因为它,才能使大规模放大基于Transformer架构的AI模型成为可能。
无论是在Gemini这样的LLM,还是Imagen和Veo这样的图像和视频生成器中,TPU都位于谷歌强大的生成式AI系统的核心。
另外,这些AI加速器也处于谷歌AI服务的核心,外部用户可以通过谷歌云获得服务。
如今,谷歌的三代旗舰TPU芯片,已经在世界各地的数据中心中制造、部署。
随着每一代TPU的发展,AlphaChip和人类专家之间的性能差距不断扩大。
从TPU v5e中的10个RL放置模块和3.2%的布线长度减少,到TPU v5p中的15个模块和4.5%的减少,再到Trillium中的25个模块和6.2%的减少。
AlphaChip还为数据中心CPU(Axion)和谷歌尚未公布的其他芯片,生成了超越人类的布局设计。
而其他公司,也在谷歌研究的基础上进行了改进。
比如联发科就不仅用AlphaChip加速了最先进芯片的开发,还在功耗、性能和面积上对芯片做了优化。
如今,AlphaChip仅仅是一个开始。
谷歌对未来做出了大胆畅想:AI将实现芯片设计全流程的自动化,
通过超人算法以及硬件、软件和机器学习模型的端到端协同优化,芯片设计的周期会显著加快,还会解锁性能的新领域。
谷歌表示,非常期待和社区合作,实现AI芯片以及芯片AI之间的闭环。
参考资料:
https://deepmind.google/discover/blog/how-alphachip-transformed-computer-chip-design/?utmsource=x&utmmedium=social&utmcampaign=&utmcontent=
https://x.com/JeffDean/status/1839308592408834559