谷歌DeepMind研究团队最近取得重大突破,开发出名为SCoRe(Self-Correction through Reinforcement Learning,通过强化学习进行自我纠正)的创新技术。这一技术旨在解决大型语言模型(LLM)难以自我纠正的长期挑战,无需依赖多个模型或外部检查即可识别和修复错误。
SCoRe技术的核心在于其两阶段方法。第一阶段优化模型初始化,使其能在第二次尝试时生成修正,同时保持初始响应与基础模型的相似性。第二阶段采用多阶段强化学习,教导模型如何改进第一和第二个答案。这种方法的独特之处在于它仅使用自生成的训练数据,模型通过解决问题并尝试改进解决方案来创建自己的示例。
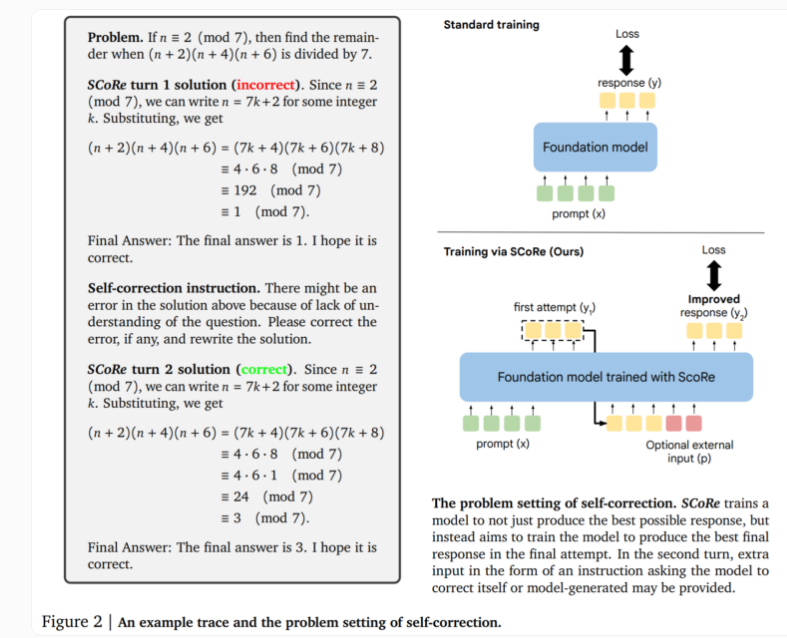
在实际测试中,SCoRe展现出显著的性能提升。使用Google的Gemini1.0Pro和1.5Flash模型进行的测试显示,在MATH基准测试的数学推理任务中,自我纠正能力提高了15.6个百分点。在HumanEval的代码生成任务中,性能提升了9.1个百分点。这些结果表明,SCoRe在提高AI模型自我修正能力方面取得了实质性进展。
研究人员强调,SCoRe是首个实现有意义的积极内在自我纠正的方法,使模型能够在没有外部反馈的情况下改进答案。然而,当前版本的SCoRe仅进行一轮自我纠正训练,未来的研究可能会探索多个纠正步骤的可能性。
DeepMind团队的这项研究揭示了一个重要洞见:教授自我纠正等元策略需要超越标准的语言模型训练方法。多阶段强化学习为AI领域开辟了新的可能性,有望推动更智能、更可靠的AI系统的发展。
这一突破性技术不仅展示了AI自我完善的潜力,也为解决大型语言模型的可靠性和准确性问题提供了新的思路,可能对未来AI应用的发展产生深远影响。