在2024北京文化论坛上,北京智源人工智能研究院(BAAI)宣布正式发布新一代中文互联网语料库CCI3.0(Chinese Corpora Internet),进一步推动数据共建共享。CCI3.0包含1000GB的数据集及498GB的高质量子集CCI3.0-HQ,是继2023年11月首次开源CCI1.0和2024年4月发布CCI2.0之后的又一次重要更新。
自首次开源以来,CCI系列数据集的下载量已超过4万次,服务于500多个企事业单位的大模型研发,有效支撑了中国人工智能产业生态的发展。
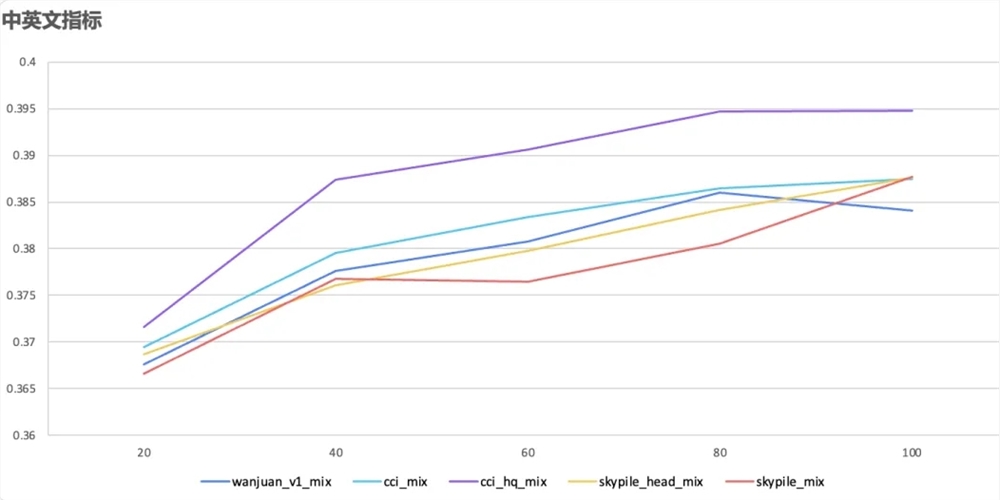
CCI3.0的特点包括:
规模扩大,来源广泛:CCI3.0收录了超过2.68亿个网页,内容覆盖新闻、社交媒体、博客等多个领域。相较于CCI2.0,CCI3.0的数据规模扩大了近一倍,数据来源机构增加至20多家,显著提升了数据的覆盖面和代表性。
精细标注,赋能应用:CCI3.0对原始数据进行了包括语法、句法、教育程度等10多个维度的细粒度分类和详细标记,以筛选出高价值数据。此外,CCI3.0HQ是基于70B模型自动标注样本,然后通过训练小尺寸质量模型进行优选得到的高质量子集,更好地满足不同行业和应用场景的需求。
效果显著,更懂中文:在500M模型从零开始训练100B数据的对比实验中,CCI3.0在单独中文语料训练和中英文语料混合训练的效果上均优于其他数据集,而CCI3.0HQ的效果则更加显著。
智源研究院表示,未来将继续与行业生态合作,推动语料库的共建共享,构建大规模、高质量、高知识密度的中文数据集,为中国人工智能产业的发展做出更大的贡献。
CCI3.0下载地址
Flopsera:
https://open.flopsera.com/flopsera-open/data-details/BAAI-CCI3
Huggingface:https://huggingface.co/datasets/BAAI/CCI3-Data
Datahub:
https://data.baai.ac.cn/details/BAAI-CCI3