火山引擎科技有限公司在2024年AI创新巡展上宣布推出豆包·视频生成模型,这是其大模型家族的新成员。
火山引擎总裁谭待表示,豆包·视频生成模型在视频生成方面具有多项先进性能,包括精准的语义理解、多动作多主体交互、强大的动态效果和一致性多镜头生成能力。

该模型能够理解和遵从复杂的指令,实现多个主体间的交互,并能够在视频主体的大动态和镜头间进行炫酷切换。此外,它还能够在多镜头切换中保持一致性,10秒内讲述一个完整的故事,并支持多种风格和比例,如黑白、3D动画、国画等。
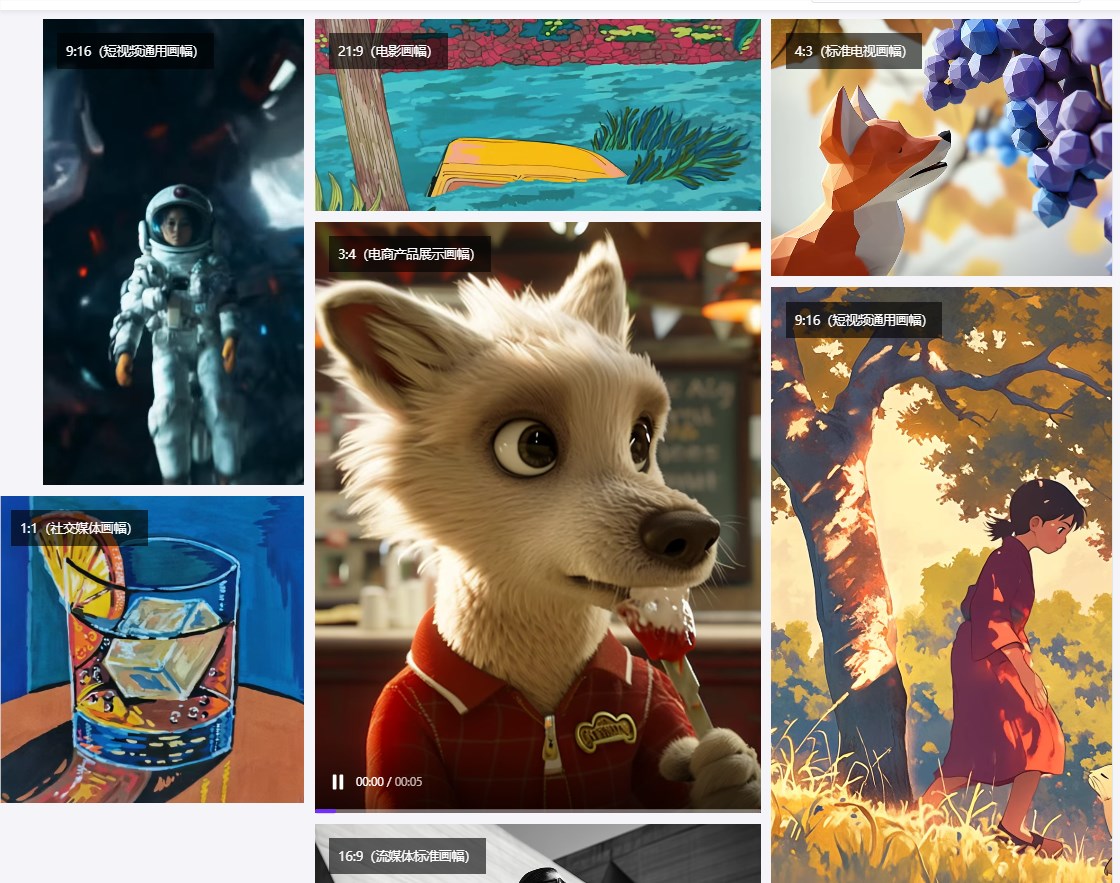
同时,模型支持包括黑白、3D动画、2D动画、国画等多种风格,并能适应1:1、3:4、4:3、16:9、9:16、21:9等多种比例,以适配不同终端和画幅。
豆包·视频生成模型不仅能够提升视频画质的高保真度,还能够让视频在主体的大动态与镜头中进行炫酷切换,拥有变焦、环绕、平摇、缩放、目标跟随等丰富的镜头语言能力。
豆包视频生成大模型,主要包含两个版本:Doubao-视频生成PixelDance和Doubao-视频生成-Seaweed 。
进入火山引擎,可以看到上线了PixelDance和Seaweed两个Doubao-视频生成版本。
一、Doubao-视频生成PixelDance
PixelDance V1.4是ByteDance Research团队开发的 DiT 结构的视频生成大模型,同时支持文生视频和图生视频,能够一次性生成长达10秒的精彩视频片段。
这个模型支持用户输入文本、图片生成视频,模型具备出色的语义理解能力,能快速生成优质的视频片段,可应用于影视创作、广告传媒等多个场景。
以下是PixelDance版本生成案例:
精准的语义理解
PixelDance V1.4可以遵从复杂prompt,解锁时序性多拍动作指令与多个主体间的交互能力
prompt:一个男人走进画面,女人转头看着他,他们互相拥抱,背景周围的人在走动。
强大动态与炫酷运镜
支持超多镜头语言,灵活控制视角,带来真实世界的体验。
一致性多镜头生成
具备一键生成故事性多镜头短片的能力,并且成功攻克了多镜头切换时一致性的技术挑战,可10秒讲述一个起承转合的故事。在一个prompt内实现多个镜头切换,同时保持主体,风格,氛围的一致性。
多风格、多比例兼容
深度优化后的Transformer结构,大大提升了视频生成的泛化能力,支持包括黑白、3d动画、2d动画、国画、水彩、水粉等多种风格,包含1:1、3:4、4:、16:9、9:16、21:9六个比例。
二、Doubao-视频生成-Seaweed
这个模型支持两种视频生成方式:文生视频和图生视频。该技术基于Transformer结构,利用时空压缩的潜空间进行训练,模型原生支持多分辨率生成,适配横屏、竖屏,并能够根据用户输入的高清图像分辨率进行适配和保真。默认输出为720p分辨率、24fps、时长5秒,并可动态延长至20-30秒。
以下是Seaweed 版本生成案例:
逼真度极高,细腻丰富的细节层次
prompt:一只大熊猫正在享用热腾腾的火锅。
专业级色彩与光影
动态流畅
豆包·视频生成模型的推出,预计将为电商营销、动画教育、城市文旅、微剧本(音乐MV、微电影、短剧等)等多个领域带来创新和效率提升。火山引擎表示,该模型的发布将全面加速AIGC应用创新。
火山引擎承诺,将继续推进模型能力的升级和迭代,探索模型能力在更多场合的应用,并为企业实现云上智能化提供动力。
数据显示,截至到9月,豆包大模型的日均 tokens 使用量已经超过1.3万亿,4个月的时间里 tokens 整体增长超过了10倍。在多模态方面,豆包·文生图模型日均生成图片5,000万张,此外,豆包目前日均处理语音85万小时。