智源研究院推出了一个名为Infinity-Instruct的千万级指令微调数据集,旨在提升语言模型在对话等方面的性能。近日,Infinity Instruct完成了新一轮迭代,包括Infinity-Instruct-7M基础指令数据集和Infinity-Instruct-Gen对话指令数据集。
Infinity-Instruct-7M基础指令数据集包含超过744万条数据,涵盖数学、代码、常识问答等领域,致力于提升预训练模型的基础能力。测试结果显示,使用此数据集微调的Llama3.1-70B和Mistral-7B-v0.1模型,在综合能力上已接近官方发布的对话模型,其中Mistral-7B甚至超过了GPT-3.5,而Llama3.1-70B接近GPT-4。
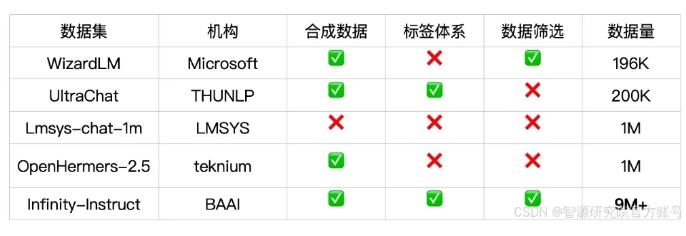
Infinity-Instruct-Gen对话指令数据集则包含149万条合成的复杂指令,目的是提高模型在真实对话场景中的鲁棒性。使用此数据集进行进一步微调后,模型的表现可超过官方对话模型。
智源研究院在MTBench、AlpacaEval2、Arena-Hard等主流评测榜单上对Infinity-Instruct进行了测试,结果表明,经过Infinity-Instruct微调的模型在对话能力上已超越了官方模型。
Infinity-Instruct为每条指令数据提供了详细的标注,如语种、能力类型、任务类型和数据来源,方便用户根据需求筛选数据子集。智源研究院通过数据选择与指令合成的方式构建了高质量的数据集,以弥补开源对话模型与GPT-4之间的差距。
项目还采用了FlagScale训练框架来降低微调成本,并通过MinHash去重和BGE检索剔除重复样本。智源计划未来开源数据处理和模型训练的全流程代码,并探索将Infinity-Instruct数据策略扩展到对齐、预训练阶段,以支持语言模型的全生命周期数据需求。
数据集链接:
https://modelscope.cn/datasets/BAAI/Infinity-Instruct