在信息爆炸的时代,如何高效获取知识成为众多学习者和专业人士面临的挑战。近日,一款名为PDF2Audio的开源工具应运而生,它巧妙地将人工智能技术与传统阅读方式相结合,为用户提供了一种全新的信息获取方式。
PDF2Audio的核心功能是将PDF文档转换为音频内容。这款工具借助OpenAI的GPT模型进行文本生成和语音合成,能够将各类PDF文件转化为播客、讲座或摘要等多种音频形式。用户只需通过简单的操作,就能将枯燥的文字资料变成生动有趣的有声内容。
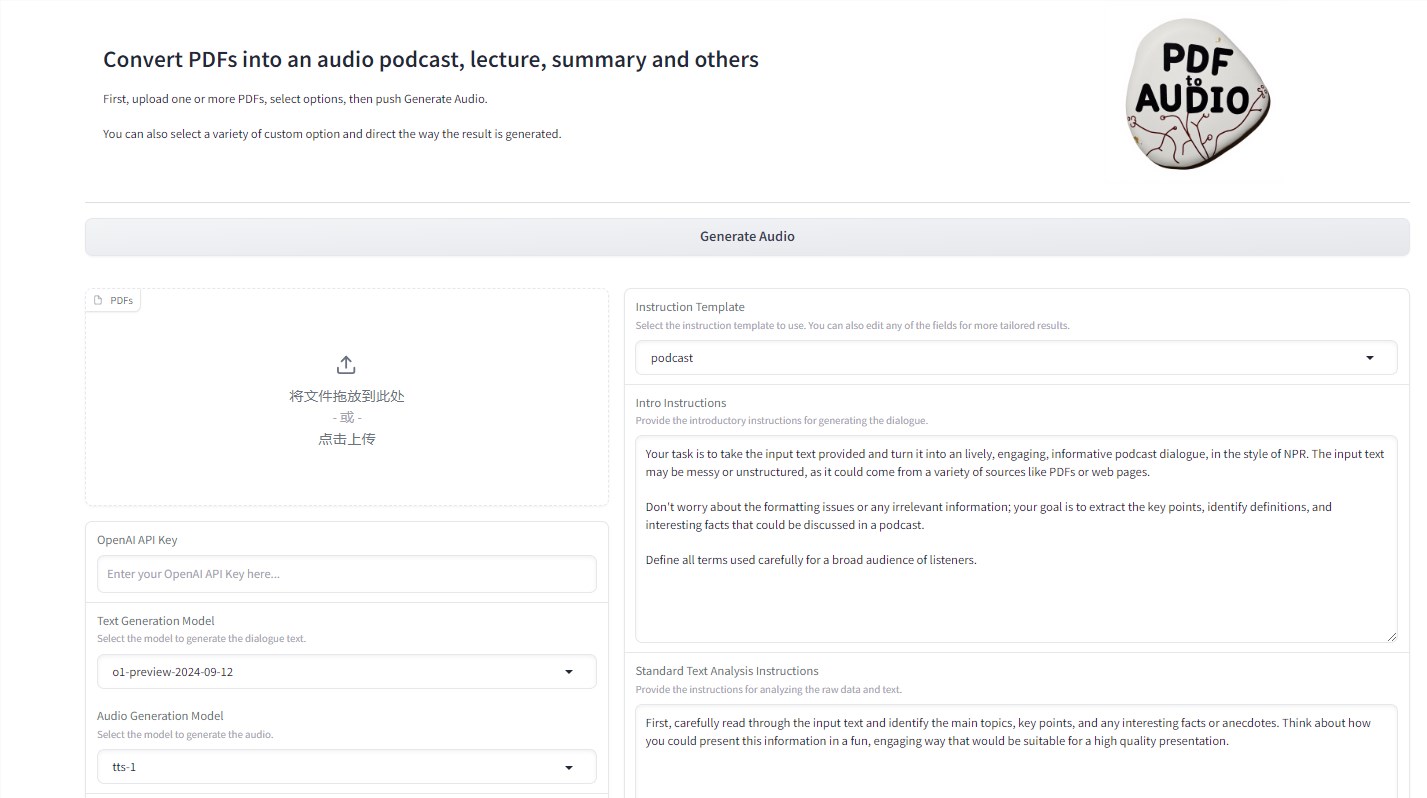
这款工具的设计充分考虑了用户的多样化需求。它支持同时上传多个PDF文件,让用户能够批量处理文档,大大提高了工作效率。同时,PDF2Audio提供了多种内容模板,包括播客、讲座和摘要等,用户可以根据自己的需求选择最合适的模板,轻松将学术论文、行业报告或个人笔记转化为易于理解的音频格式。
个性化是PDF2Audio的另一大特色。用户可以自由选择GPT文本生成模型和文本转语音模型,还能够从多种语音风格和音色中挑选,打造独特的听觉体验。这种灵活性使得用户能够根据个人喜好或特定场景需求,调整音频输出效果。
为了确保生成内容的质量,PDF2Audio还提供了草稿编辑和反馈迭代功能。用户可以多次修改生成的脚本,并提供具体反馈,系统会根据这些意见不断优化音频内容,最终呈现出令人满意的结果。
在技术实现方面,PDF2Audio采用了Gradio接口,用户只需在本地机器上完成安装,即可通过浏览器轻松上传文件并生成音频。这种设计极大地降低了使用门槛,让更多非技术背景的用户也能享受到AI带来的便利。
在线体验地址:https://huggingface.co/spaces/lamm-mit/PDF2Audio
项目地址:soraor.com