Meta近日发布了一款名为"Imagine yourself"的创新AI模型,它能够仅凭一张参考照片,生成各种个性化图像,无需额外训练。这项技术突破让人仿佛置身魔法世界,能够在不同姿势、风格和环境中展示同一个人。
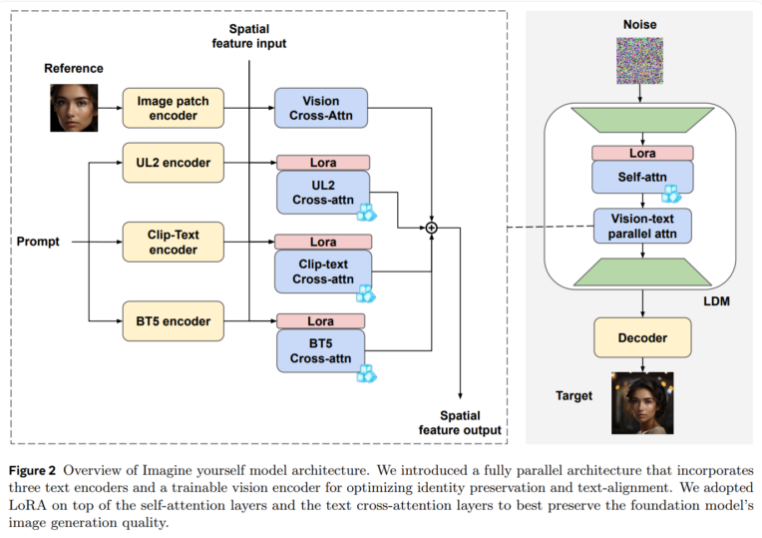
与传统AI模型不同,"Imagine yourself"采用全新的运作方式。它能同时处理照片和文本指令,灵活应对新的要求和人物,大大提高了效率和适应性。为实现这一突破,Meta在技术上做了两项关键创新:
利用合成训练数据:通过生成与真实照片对应的合成变体,让模型学会更加生动多样地展示人物,而非简单复制参考图像。

全新架构设计:搭载三个平行的文本处理模块和一个可训练的图像处理模块,实现了图像和文本的更好协调。
根据Meta的说法,"Imagine yourself"在处理复杂指令时表现优异,如改变表情、头部姿势,甚至将人物置于全新环境中。虽然在身份保留方面偶有不及其他模型之处,但这主要是因为竞争对手往往简单复制参考图像,导致结果不够自然。
值得一提的是,这个模型还能扩展到多人图像生成,通过并行处理多个参考图像,轻松制作出一群人在新姿势和环境中的照片。
尽管"Imagine yourself"已经展现出惊人的能力,Meta仍在持续改进。未来,他们计划将技术扩展到视频生成,甚至处理复杂姿势如跳跃等。虽然目前模型和代码尚未公开,但可以预见,这项技术将引领个性化图像生成的新潮流,为创意产业带来革命性变革。
随着AI技术不断进步,我们期待看到更多令人惊叹的应用出现,推动视觉创作和个性化内容生成向前发展。Meta的这一突破无疑为未来AI图像处理技术指明了新的方向。