随着OpenAI的GPT-4在传统数学评测中屡创佳绩,北京大学和阿里巴巴的研究团队联手推出了一个全新的评测基准——Omni-MATH,旨在评估大型语言模型在奥林匹克数学竞赛级别的推理能力。这一举措不仅为AI数学能力的评估提供了新标准,也为探索AI在高级数学领域的潜力开辟了新途径。
Omni-MATH的独特设计
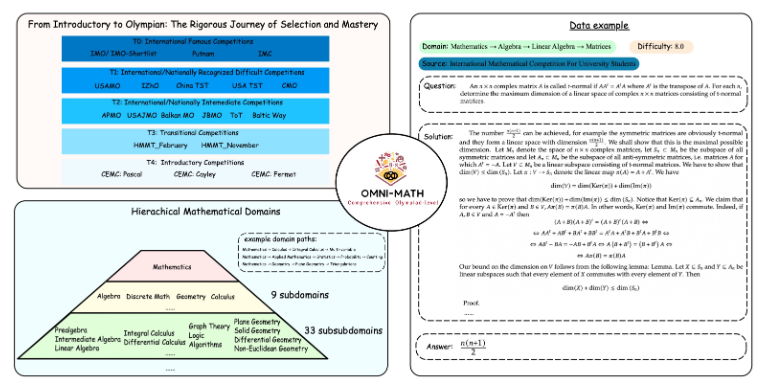
Omni-MATH评测库包含4428道竞赛级别的数学问题,涵盖33个以上的数学子领域,难度分为10个不同级别。其特点包括:
高可靠性:所有题目均来自各种数学竞赛和论坛,答案经过人工验证。
广泛覆盖:从奥林匹克预备级别(T4)到顶级奥林匹克数学竞赛(T0),如IMO、IMC和普特南等。
多样性考虑:通过基于GPT-4和其他评测模型的评价方式,优化了答案多样性的问题。
在最新的排行榜上,除GPT-4满血版外,表现突出的包括:
GPT-4-mini:平均分比GPT-4-preview高出约8%
Qwen2-MATH-72b:超过了GPT-4-turbo的成绩
这些结果显示,即使是小型模型,在特定能力上也可能有出色表现。
评测体系的深度与广度
Omni-MATH的设计充分考虑了国际数学竞赛的选拔流程和难度层级:
参考英国和美国等国家的奥数选拔体系
涵盖从数论、代数到几何等多个数学领域
数据来源包括各类比赛题目、解析和著名数学网站的论坛内容
创新的评测方法
研究团队开发了Omni-Judge开源答案验证器,利用微调过的Llama3-Instruct模型,能快速判断模型输出与标准答案的一致性。这种方法在保证95%一致率的同时,也为复杂数学问题的评测提供了便捷解决方案。
Omni-MATH的推出不仅是对AI数学能力的全新挑战,也为未来AI在高级数学领域的应用和发展提供了重要的评估工具。随着AI技术的不断进步,我们或许能在不久的将来,见证AI在奥林匹克数学竞赛中的惊人表现。
项目地址:https://github.com/KbsdJames/Omni-MATH/