声明:本文来自于微信公众号 量子位,作者:梦晨 衡宇,授权Soraor转载发布。
AI大行其道的时代,网络安全正面临前所未有的威胁。
化身黑客的AI学会了自动化攻击,还有相当高的成功率,伊利诺伊大学香槟分校研究团队的最新研究显示:GPT-4能够在阅读CVE漏洞描述后,学会利用漏洞攻击,成功率高达87%。
既然攻击方都与时俱进,用上AI新技术来搞破坏。
防御方自然也不会坐以待毙,也在积极把AI大模型纳入自己的反制招数里,最近就有这样一件大事:
今年刚刚完成10亿融资的新生代网络安全领军企业长亭科技,联手同为清华系的AI Infra厂商趋境科技,共同发布新一代安全大模型解决方案,此次合作将长亭问津(ChaitinAI)安全大模型参数规模提升至超过千亿,安全能力全方位大幅提升。
至此网络安全行业迈入千亿大模型时代。
从百亿到千亿,大模型参数规模升级,究竟能给网络安全带来什么改变?
网络安全领域有两个核心的指标:攻击识别准确率、检测时延。
在一个企业的网络系统里,每天都有各种各样的访问/调用请求,需要识别每一个请求是正常的业务还是恶意的攻击。加入大模型后,能够协助系统进行更快速、更准确的攻击判断。
举个栗子经常会收到的欺诈邮件就是一种恶意攻击,一旦点击其中的链接或者下载文件之后,电脑就会被攻击。
加入了大模型之后,在大家收到邮件的同时,大模型就会对邮件进行内容识别,根据多条线索来进行多个步骤的恶意攻击研判,在判定为恶意邮件后,秒级自动向用户告警,并提醒用户尽量避免点击链接和下载附件。
在长亭科技30万+自有的多类型攻击样本测评中,某国内头部大模型攻击识别率为48.3%,而通过长亭联合趋境科技发布的千亿参数的安全大模型解决方案,可以把成绩提升到92.1%。
在另一个基于真实攻击流量构建的私有数据集的测试中,问津(ChaitinAI)也成功把成绩从65.5%提升到95.8%。
再拿对安全要求更高的金融企业举例,交易行为和数据对安全性要求极高,拥有复杂的网络环境,同时由于在系统里的各种交易行为活动量大,通常会有海量的日志数据,而对应的攻击手段也非常多样。
某金融企业在一次网络环境中出现异常行为时,问津(ChaitinAI)安全大模型同样秒级响应。
首先从海量日志数据中迅速提取对应的数据行为并进行标准化处理,根据行为模式研判属于APT攻击(Advanced Persistent Threat,高级长期威胁),同时提取攻击行为相关的关键资产,扫描其中的安全漏洞,明确威胁行为来源。随后再对攻击行为流量、文件等进行分析,成功揪出背后伪装成合法软件的恶意工具包。
问津(ChaitinAI)在这次攻击行为中给出了精确的事件研判报告和处理对策,整个流程仅需3分钟,MTTD(平均检测时间)和MTTR(平均响应时间),从原来的三十分钟到数小时,减少到10分钟以内,帮助该企业安全团队迅速定位和决策,成功阻断了APT攻击的进⼀步渗透和破坏。
像这样的提升,接下来还有……这么多:
事件研判处理建议采纳率提升
安全报告的内容生成质量评分提升
对于代码的问题发现和检测的准确率提升
漏洞修复建议的采纳率提升
对于违法、有害、暴力、色情等不良内容的识别能力更强。即对不良内容的识别准确率、召回率提升
同一目标的渗透测试任务,大模型驱动的智能渗透测试的漏洞发现数量以及可真实利用数量提升
基于不同场景选择合适工具/策略的准确率提升
综合的输出健壮性和稳定性,不同场景下输出质量的波动率降低
Scaling Law的威力,在垂直领域大模型上再一次得到验证:
参数规模的数量级提升,会体现在模型的通用性、泛化能力上。再落实到应用场景上,就不只是单点的指标突破,而是全方位提升了。
接下来的问题就是,过去安全行业怎么不用千亿大模型,是因为不喜欢吗?(狗头)
其实主要涉及安全检测效果、用户响应效率和私有部署成本,三者之间的矛盾。
安全行业对于检测效果的追求永无止境,任何一个小小的安全漏洞很可能带来巨大的损失。安全大模型依然遵循Scaling Law,千亿参数的模型相比于百亿参数,安全效果进一步升级。
同时,网络安全防护是24小时一刻也不能松懈的任务,需要不断调用大模型进行推理。一旦检测到攻击事件,接下来的响应速度也非常关键。
此外,对于安全行业来说,数据的隐私性也极其重要,使用大模型需要在本地部署,并用特定数据进行训练。而训练和维护一个千亿参数的模型,背后是巨大的计算资源和投入,成本动辄需要数百万。
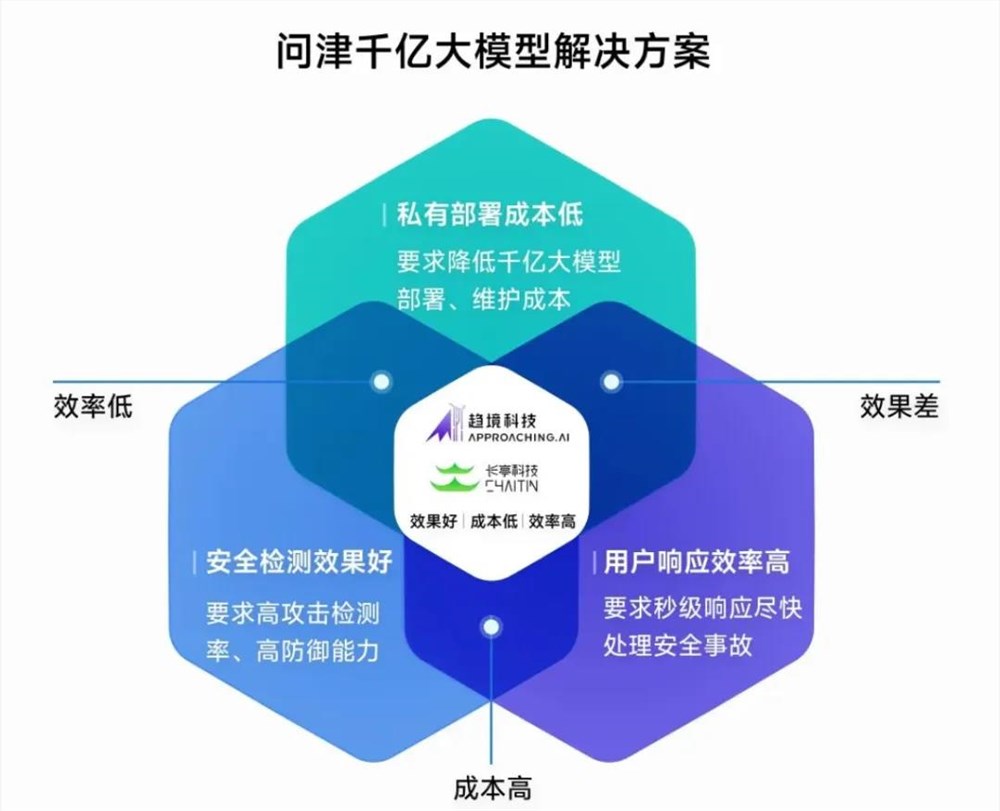
既要安全效果好、又要落地成本低、还要检测效率高,安全大模型落地中的看似“不可能三角”,被长亭和趋境联手破解了。
这是一个掌握垂直行业场景的公司与大模型技术公司合作的典型案例。
长亭科技是国内顶尖的网络信息安全公司之一,专注为企业级用户提供智能、简单、省心的安全防护产品和解决方案。
趋境科技则是一家AI Infra新秀,专注于构建和开发先进的大模型推理加速平台,为企业和开发者提供高效、低成本的大语言模型推理服务。
趋境科技在不久前,联合清华KVCache.AI团队发布开源项目“KTransformers(https://github.com/kvcache-ai/ktransformers)”,利用 MoE 模型和长文本注意力算子的稀疏特性,采用异构划分策略,大幅度提升了超大模型和超长文本的推理性能,降低了他们本地部署的门槛。
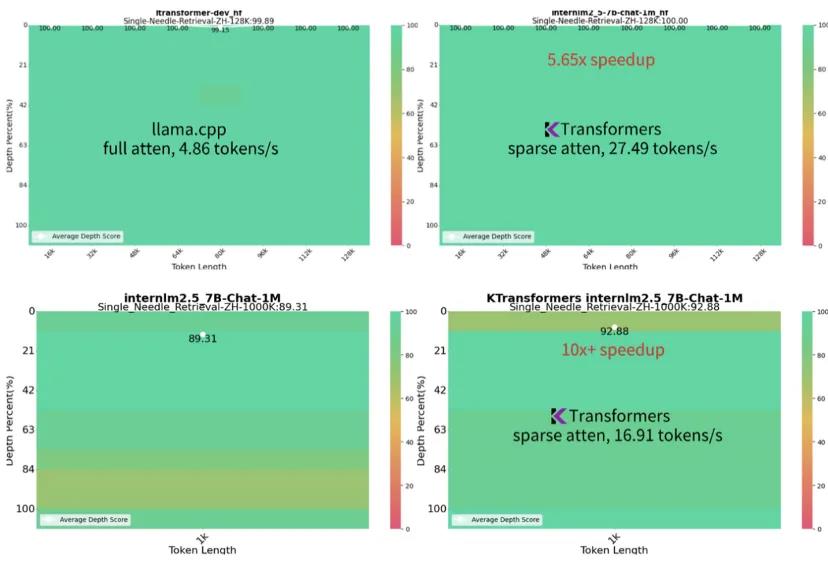
作为项目的首个展示案例,使用 KTransformers ,只需不到12GB 的显存和百余 GB 的内存即可在本地运行Mixtral8x22B 和 DeepSeek-Coder-V2等千亿级大模型,达到数倍于 Llama.cpp 的性能。
这一技术使得千亿大模型的本地使用成本降低了10倍以上。

另一方面,对于安全场景下同样非常重要的长文本推理能力 KTransformers 同样可以实现大幅度优化。
即便是长达1M 的超长上下文,KTransformers 也可以在仅配备24GB 显存的设备上即可完成,生成速度达到16.91token/s,比 Llama.cpp 快10倍以上的同时维持了接近满分的“大海捞针”。
项目在GitHub上开源后,马上被Hugging Face注意到,收获了开源项目负责人 Lysandre Debut 的点赞,同时还在国内外社区里引起很多讨论。
推出开源版本的同时,趋境科技也推出了高性能 KTransformers 商业版引擎和基于此的推理服务平台,通过高级内核优化和放置/并行策略,在开源版的基础上推理能力更强,速度更快,同时也增加了针对企业级的高并发策略,更适合团队/企业级用户。
在AI Infra日益完善、大模型安全备受关注的行业背景下,同为清华系的长亭科技也很快注意到趋境科技。

由于问津(ChaitinAI)安全大模型同样具备参数和注意力两方面的稀疏性,这与趋境科技的技术优势十分贴切,双方一拍即合:
采用KTransformers的技术策略对问津(ChaitinAI)安全大模型进行升级。
问津(ChaitinAI)安全千亿大模型解决方案应运而生。
双方联手,不仅是技术实力的验证,更是深入场景落地能力、方案交付能力的验证。
大模型在各行业的快速落地,离不开行业场景公司和AI Infra公司的联合。
大模型的安全性和可靠性一直是持续关注和优化的重点所在。这次的合作只是一次创新试验,是大模型技术发展的一个缩影。
更长远来看,未来,随着AI技术的不断发展和行业需求的日益旺盛,会有更多这样的合作出现。
可以预见,这些合作将不仅局限于技术层面的创新,更将涉及到安全、伦理、治理等多个维度的探索和实践,共同推动大模型一步步落到千行百业。
问津(ChaitinAI)千亿大模型解决方案试用链接:https://jsj.top/f/lzjQag
问津官网:https://www.chaitin.cn/zh/chaitinAI
KTransformers 开源链接:https://github.com/kvcache-ai/ktransformers
趋境科技官网:https://approaching-ai.com/