声明:本文来自于微信公众号 新智元,作者:新智元,授权Soraor转载发布。
近期,腾讯混元推出新一代旗舰大模型——混元Turbo。
作为国内率先采用MoE结构大模型的公司,腾讯继续在这一技术路线上进行技术创新。
相较上一代混元Pro的同构MoE大模型结构,混元Turbo采用了全新的分层异构MoE结构,在参数总规模上依然保持万亿级。

公开信息显示,当前混元Turbo模型在业界公认的benchmark指标上处于国内行业领先地位,与国外头部模型如GPT-4o等相比也处于第一梯队。
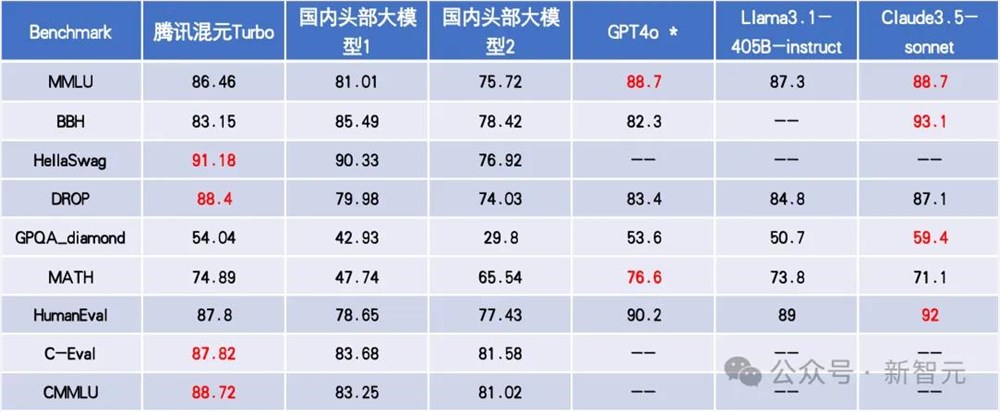
另外,在刚刚发布的国内第三方权威评测机构评测中,混元Turbo模型位列国内第一。
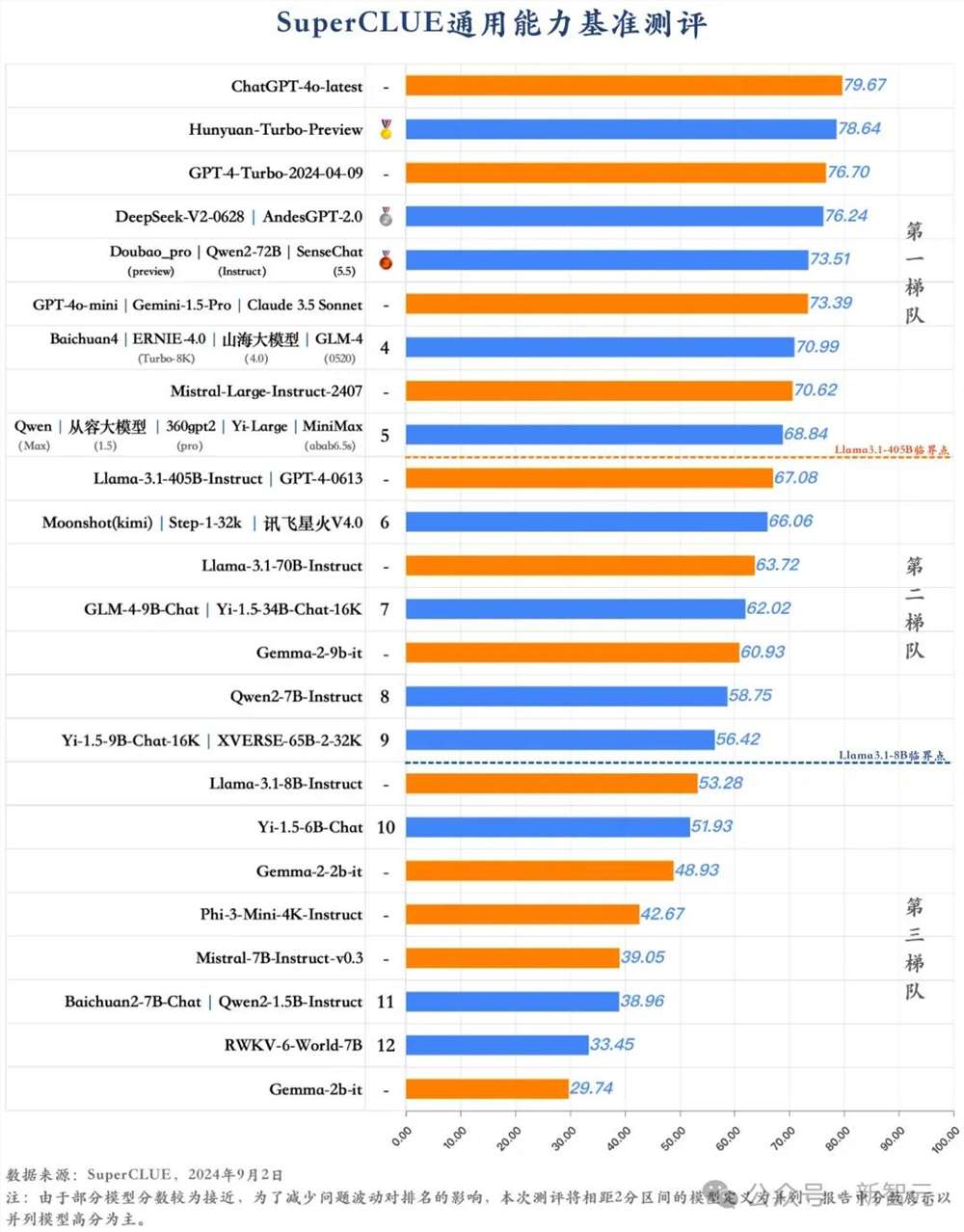
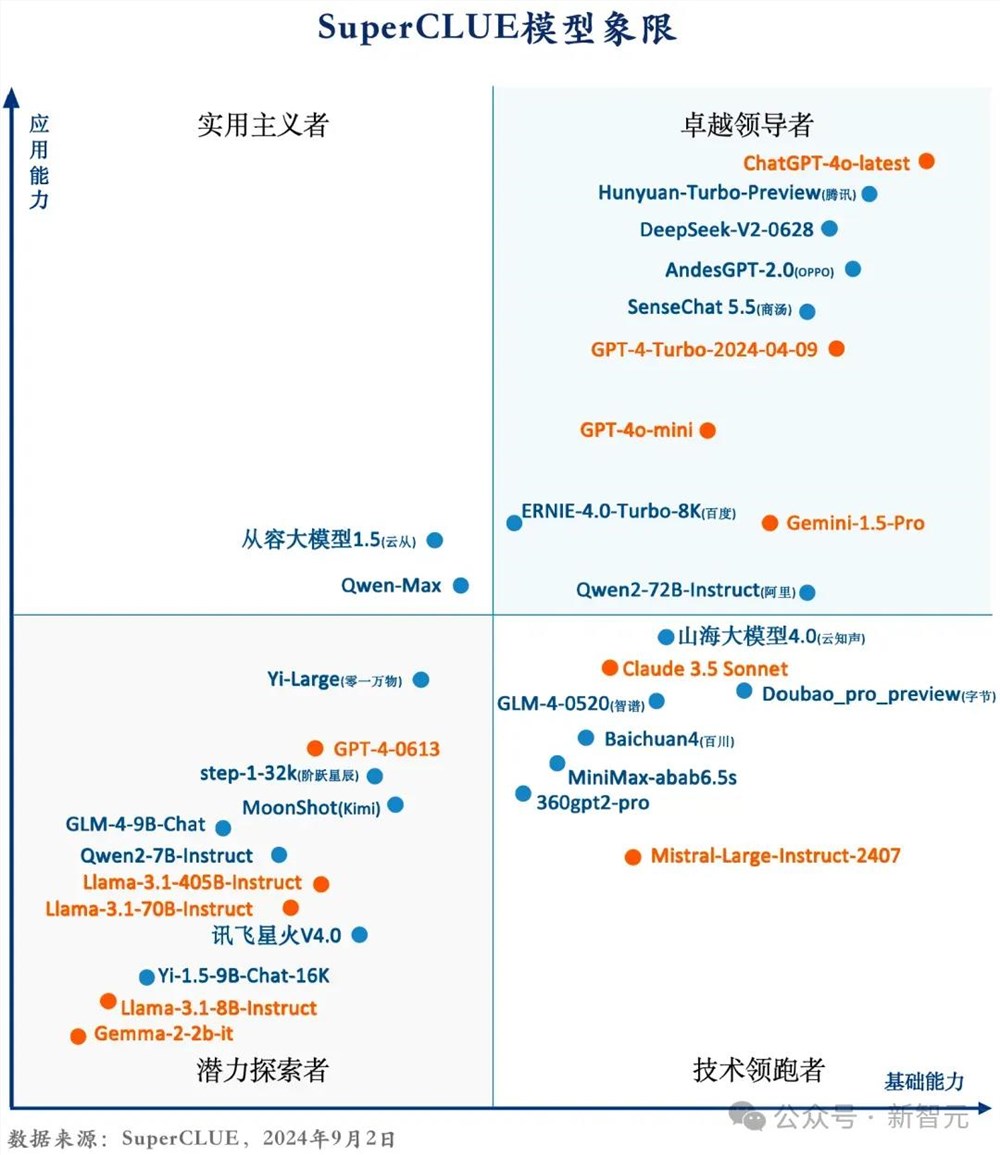
混元Turbo是如何做到如此快速的进步?
背后技术细节首公开
我们拿到了混元Turbo的技术解读,从Pretrain、Postrain和专项能力突破几个角度,深入展示了模型升级的秘密。
首先,业界目前普遍公认,大模型Pretrain成功的关键秘诀之一是Scaling Law。
可以简单理解为,训练数据量越大,模型效果越好;参数量越大,模型效果越好。
其中后者意味着,如果想要模型具备更高的效果天花板,就需要设计较高参数量的大模型,但大参数量设计也意味着较高的部署成本和较低的训练推理性能。
为此,混元Turbo采用了全新的异构MoE结构。
通过较多的专家数和较小激活量设计,在模型整体参数量依然保持万亿级规模前提下,通过整体算法升级和训练推理框架加速的端对端优化,模型效果相比上代混元Pro有较大提升。
与此同时,模型训练推理效率也有超1倍的提升,并最终带来了50%的推理部署成本下降,以及20%推理时延降低。
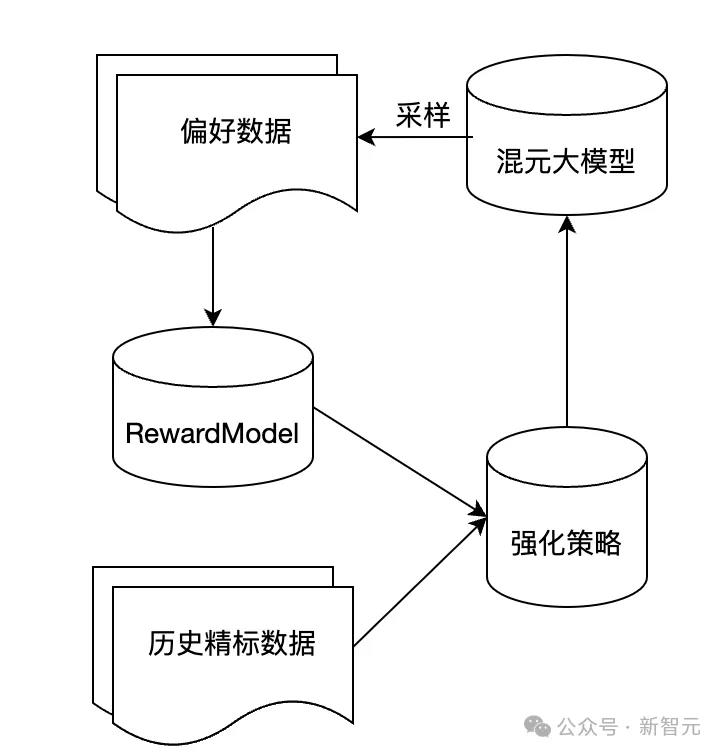
其次,在Postrain阶段,腾讯混元Turbo自研了混元CriticModel和RewardModel,用于构建自提升pipeline,并在RLHF阶段全面采用了离线数据和在线采样结合的强化学习策略。
相对传统PPO及DPO,其整体可控性更好,效果上限更高。
除了在通用能力方面持续优化外,针对当前业界大模型普遍存在的文科能力「重而不强」,理科能力普遍偏弱的现状,本次混元Turbo大模型也专项强化了高质量文本创作、数学、逻辑推理等典型大模型文理科能力。
文本创作、数学、逻辑推理能力全面提升
- 专项能力-高质量文本创作
当前大模型普遍存在的一般文本创作尚可,但专业化写作机器味浓、不够信雅达,字数控制等指令跟随能力不足等问题。
腾讯混元Turbo模型做了大量高质量文本创作专项优化。
以中、高考中文写作为例,腾讯混元团队引入专家标注团队,构建高质量写作评估模型,同时,构建创作指令约束体系,提升复杂指令跟随能力。
通过以上优化,高考作文写作这一项能力上,混元Turbo在专家标注团队中自评达一类卷水平,在刚刚过去的24年高考中,混元Turbo获得第三方大模型高考作文写作评测第一名。
- 专项能力-数学
如何大幅提升模型的数学能力是一项非常有挑战性的任务。腾讯混元采用了以下几种技术方案来提升模型效果。
提升数据量:针对已有题库模拟大量数学题用于模型的增训。对于一些比较难的题目,也会采用MCTS等技术来提高模型的做题能力。
强化学习:为了进一步提升模型能力,采用了强化学习技术,包括DPO/PPO等技术。训练了一个基于过程的reward模型对结果进行打分。
最终,混元Turbo在数学推理能力上有了较大提升,在内外部多种评测集上达到了业界先进水平。
- 专项能力-逻辑推理
推理的第一大难点在于推理问题的多样性,往往用户的问题千奇百怪,要在PostTrain阶段比较好的解决这个难点,必须要提升SFT数据中推理问题的广度和质量。
预训练中的推理问题非常丰富,但是结构化不足,往往一个比较好的问题隐藏在某一个文档的最后。
为了解决这个问题,腾讯基于腾讯混元训练了一个问题抽取模型(Problem Extraction Model),抽取出千万级量级的推理类指令。
另外,通过公开渠道获取全网偏推理的问题,大幅补充了SFT数据中推理问题的多样性。
推理能力的第二个难点是,复杂问题的答案如何构建。
对此,腾讯训练一个critique模型对推理类训练数据进行打分,然后迭代更新答案,直到构建推理过程和结论完全正确的训练。
最终,推理数据质量得分提升10%。
经过上述优化,混元Turbo较以往的版本在内部推理评测中总体提升9%,在一些较为难的子类上例如因果、符号推理等上都取得了明显进步。
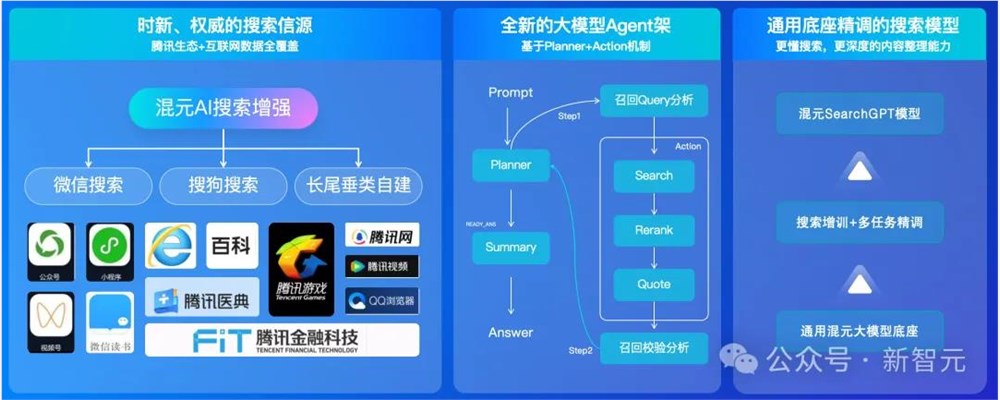
- 联网插件-AI搜索
作为腾讯混元新一代旗舰大模型,混元Turbo除支持各类大模型能力外,也支持AI搜索联网插件。
通过整合腾讯优质的内容生态(如微信公众号、视频号等)和全网搜索能力,同时基于Planner+Action Agent架构,混元Turbo AI搜索基于混元通用大模型底座,使用丰富的搜索数据进行多任务精调,得到更懂搜索、具备精准阅读理解能力的SearchGPT,用于AI深度问答。
目前通过AI搜索的强大加持,混元Pro具备强大的时新、深度内容获取和AI问答能力。
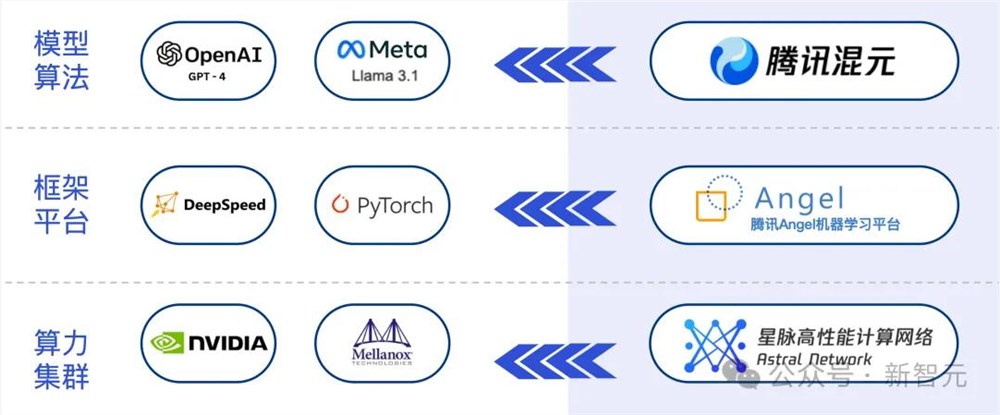
自研工程平台的牢固支撑
惊艳的模型效果,离不开底层算法和平台的支持。
腾讯混元大模型全面建立在腾讯全面自研的Angel机器学习平台和强大的算力基础设施之上。
面对万亿级MoE模型参数大显存需求高,All2all通信效率低,训练性能低等挑战,腾讯混元训练框架AngelPTM通过引入大BatchSize训练、FP8低精度训练、梯度通信/MoE通信计算、MOE算子融合等优化策略,使得训练性能提升108%,成本下降70%。
针对大模型大窗口能力已成行业必备趋势,AngelPTM采用精度无损的attention均衡通信加速算法,实现了高达10M长窗口的训练能力。
对于混元Turbo这样的万亿级超大MoE大模型,推理成本和速度是很大的挑战。
为此,混元推理加速框架AngelHCF支持FP8量化压缩,定制了一系列算子加速FNN模块的推理性能,使得推理性能整体提升1倍,成本下降50%;
另外,在强化学习阶段,通过在AngelPTM中集成AngelHCF的方式加速sampling采样性能,整体吞吐提升40%以上。
此前,中国电子学会2023科学技术奖评选,腾讯《面向大规模数据的Angel机器学习平台关键技术及应用》获科技进步一等奖。
元宝APP,可以上手了
目前,腾讯混元Turbo模型除已经作为新一代旗舰大模型,在腾讯云官网API正式上架。
此外,它还在腾讯元宝APP中面向所有C端用户开放(点击阅读原文体验),速度更快、体验更好,同时提供AI搜索、AI阅读、AI写作和AI作画等核心功能。
基于混元Turbo模型强大的通用内容理解和推理能力,以及与腾讯生态体系、如微信搜一搜、搜狗搜索、微信公众号、视频号、腾讯新闻和腾讯金融等内容平台全面连接,为用户提供丰富、权威的生态优质内容及全网信息。