声明:本文来自于微信公众号 新智元,作者:新智元,授权Soraor转载发布。
Nicholas Carlini是谷歌DeepMind的一位研究科学家,近日,他撰写了一篇长达8万字的文章,介绍自己是怎么使用AI的。
他详细列举了自己日常使用AI的50个实例,而且说这些只是他所有AI应用的不到2%。

文章地址:https://nicholas.carlini.com/writing/2024/how-i-use-ai.html
一开篇,Nicholas就亮出了自己的观点:「我不认为AI模型(LLM)被过度炒作了」。
他承认AI泡沫的存在——「许多公司喜欢说自己『正在使用人工智能』 ,就像他们以前说自己由『区块链』驱动一样」。
但是,Nicholas认为AI所取得的进展可不仅仅是炒作。
因为在过去的一年里,他每周至少花几个小时与各种大语言模型进行交互,这些大语言模型能够胜任越来越困难的工作。
有了这些模型,Nicholas在研究项目和副业项目中编写代码的速度至少提高了50%。
以下就是Nicholas使用LLM的几个实例——
用他从未使用过的技术构建整个网络应用程序
让模型教我如何使用以前从未使用过的各种框架
将数十个程序自动转换为C语言或Rust语言,将性能提高10-100倍
缩减大型代码库,大幅简化项目
为他去年撰写的几乎每一篇研究论文编写初始实验代码
将几乎所有单调的任务或一次性脚本自动化
在帮助他设置和配置新软件包或项目时,它几乎完全取代了网络搜索
约50%的网络搜索被取代,以帮助他调试错误信息
Nicholas将这些例子分为了两大类,一类是「帮助我学习」,另一类是「自动化无聊的任务」。
这些应用可能并不花哨,因为它们都来自于Nicholas完成实际工作的需要,就像我们一样——每天所做的大部分工作并不迷人。
但LLM的魅力正基于此:自动化完成那些工作中boring的部分。
作者背景
有一点很重要,Nicholas特别写在了前面,他自己并不是一个乐于相信新技术的人。
尽管他经历了十年前安全界的加密炒作,但他没有写过关于区块链的任何一篇论文,也从未拥有过比特币,「它们基本上没有任何用途,除了赌博和欺诈」。
除此之外,Nicholas作为一名安全研究员,近十年来,他的日常工作就是向人们展示人工智能模型在面对未经训练的环境时会以何种方式惨遭失败。
他已经证明,对机器学习模型的输入稍加扰动,就能让它们产生大错特错的输出。
或者,大多数机器学习模型都会记住训练数据集中的特定示例,并在你使用它们时重复这些示例。
所以,他完全理解这些系统的局限性。
然而,Nicholas毅然决然地宣称「大语言模型为我的工作效率创造了自互联网诞生以来的最大提升」。
如何使用语言模型
去年,Nicholas做了一个「GPT-4能力预测挑战赛」的小游戏,共设置了28个由易到难任务,让人们逐步预测GPT-4成功解决它们的概率。
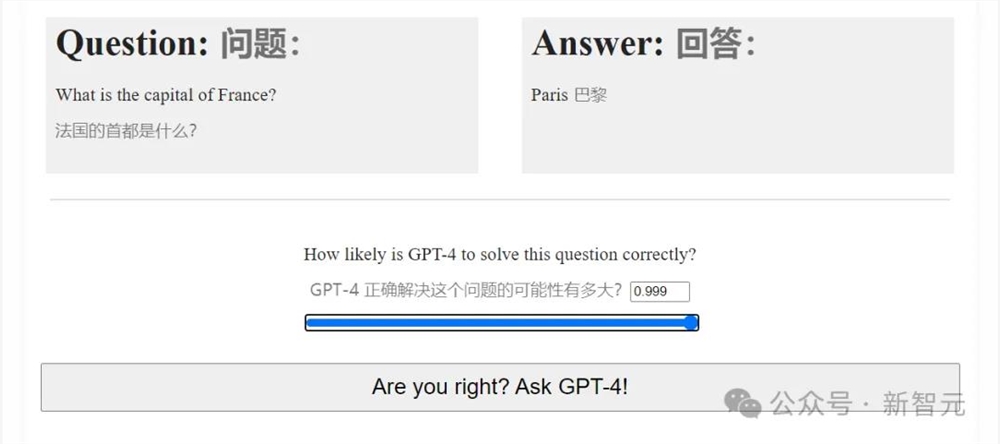
GPT-4能力预测挑战赛
结果很受欢迎,页面浏览量超过了一千万。你猜怎么着?整个应用程序的初始版本几乎全部是GPT-4编写的。
Nicholas是通过一系列的问题来完成的,从询问应用程序的基本结构开始,然后慢慢建立各种功能。
这段对话总共长达3万字,真正凸显了GPT-4(当时最先进的)原始模型的能力。
语言模型擅长解决人们以前解决过的问题,而这个测验99%的内容都是一些基本的HTML和Python网络服务器后台,世界上任何人都可以写出来。
这个测验之所以有趣,人们之所以喜欢,并不是因为它背后的技术,而是因为测验的内容。因此,将所有枯燥的部分自动化,让Nicholas制作这个测验变得非常容易。
Nicholas说,事实上,如果没有语言模型的帮助,他可能就不会做这个测验。因为他自己没有兴趣花时间从头开始编写整个网络应用程序。
一个人一天只有这么多时间,而且由于工作原因,Nicholas大部分时间都花在了解最新的研究进展上,而不是JavaScript框架。

这意味着,当需要在他的特定研究领域之外启动一个新项目时,他通常有两种可能的选择。
首先,可以利用已经知道的知识,这些知识往往已经过时一二十年,但如果项目规模较小,往往已经足够。
或者,可以尝试学习新的(通常是更好的)做事方法。
这就是LLM的用武之地。
因为像Docker、Flexbox或React这样对Nicholas来说很新的框架/工具,对其他人来说并不陌生。
世界上可能有数以十万计的人对这些东西都了如指掌,这也就意味着当前的语言模型也是如此。
今年早些时候,Nicholas正在构建一个LLM评估框架,希望能够在一个封闭的环境中运行LLM生成的代码,这样它就不会随意删除他电脑上的文件或类似的东西。
Docker是完成这项任务的完美工具,但他以前从未使用过。
重要的是,这个项目的目标并不是使用Docker,Docker只是实现目标所需的工具。
Nicholas想要的只是了解他所需要的10%的 Docker,这样他就能确信自己正在以最基本的方式安全地使用它。
如果是在上世纪90年代做这件事,Nicholas基本上只能买一本介绍如何从第一原理开始使用 Docker 的书,读完前几章,然后试着跳来跳去,找出如何做他想做的事。
如果是在前十年,情况有所改善。他会在网上搜索一些介绍如何使用Docker的教程,并试着跟着做,然后在网上搜索他发现的任何错误信息,看看是否有人遇到过同样的问题。
但今天,「只需要请一个语言模型来教我Docker就好」。
由于篇幅所限,有关Nicholas使用LLM的更多示例,请移步到他的个人网站(文末有参考链接)。
结论
Nicholas称自己写作这篇文章有两个动机,第一个是证明LLM已经为他提供了很多价值。
第二个是为那些「很喜欢使用LLM,但不知道它们如何帮我」的朋友提供一些示例。
在展示这些示例之后,他最常听到的反驳之一就是「但这些任务很简单!任何计算机科学专业的本科生都能学会!」
只要花几个小时四处搜索,本科生就能告诉你如何正确诊断CUDA错误,以及可以重新安装哪些软件包。
一个本科生只要花几个小时,就能用C语言重写那个程序。
一个本科生只要花几个小时,就能研究相关的教科书,教给你任何你想知道的知识。
但不幸的是,我们没有那个「神奇的本科生」,他会放下一切,回答你的任何问题。
但我们有语言模型。当然,语言模型还没有好到可以解决程序员工作中最难也最有趣的部分,目前的模型只能解决简单的任务。
五年前,LLM所能做到的最好的事情就是写出一段听起来像是英语的段落,但它们的实际效用完全为零。
但如今,它们已经让Nicholas在编程方面的工作效率平均提高了至少50%,并且消除了足够多的繁琐工作,让他做出了许多他从未尝试过的东西。
所以,Nicholas才会旗帜鲜明地反对「LLM只是炒作」的观点。
作为一个拥有20年编程经验的科学家,Nicholas利用LLM显著提高了自己的工作效率,他相信,其他人也可以从中受益。