声明:本文来自于微信公众号新智元,作者:新智元,授权Soraor转载发布。
Nature的一篇文章透露:你发过的paper,很可能已经被拿去训练模型了!有的出版商靠卖数据,已经狂赚2300万美元。然而辛辛苦苦码论文的作者们,却拿不到一分钱,这合理吗?
全球数据告急,怎么办?
论文来凑!
最近,Nature的一篇文章向我们揭露了这样一个事实:连科研论文,都被薅去训AI了……
据悉,很多学术出版商,已经向科技公司授权访问自家的论文,用来训练AI模型。
一篇论文从酝酿idea到成稿,包含了多少作者日日夜夜的心血,如今很可能在不知情的情况下,就成为训AI的数据。
这合理吗?
更可气的是,自己的论文还被出版商拿来牟利了。
根据Nature报告,上个月英国的学术出版商Taylor & Francis已经和微软签署了一项价值1000万美元的协议,允许微软获取它的数据,来改进AI系统。
而6月的一次投资者更新显示,美国出版商Wiley允许某家公司使用其内容训模型后,直接一举豪赚2300万美元!
但这个钱,跟广大论文的作者是半毛钱关系都没有的。
而且,华盛顿大学AI研究员Lucy Lu Wang还表示,即使不在可开放获取的存储库内,任何可在线阅读的内容,都很可能已经被输入LLM中。
更可怕的是,如果一篇论文已经被用作模型的训练数据,在模型训练完成后,它是无法删除的。
如果现在,你的论文还尚未被用于训练AI,那也不用担心——它应该很快就会了!
数据集如黄金,各大公司纷纷出价
我们都知道,LLM需要在海量数据上进行训练的,而这些数据通常是从互联网上抓取的。
正是从这些训练数据中数十亿的token中,LLM推导出模式,从而生成文本、图像、代码。
而学术论文篇幅又长,信息密度又高,显然就是能喂给LLM的最有价值的数据之一。
而且,在大量科学信息上训练LLM,也能让它们在科学主题上的推理能力大大提高。
Wang已经共同创建了基于8110万篇学术论文的数据集S2ORC。起初,S2ORC数据集是为了文本挖掘而开发的,但后来,它被用于训练LLM。
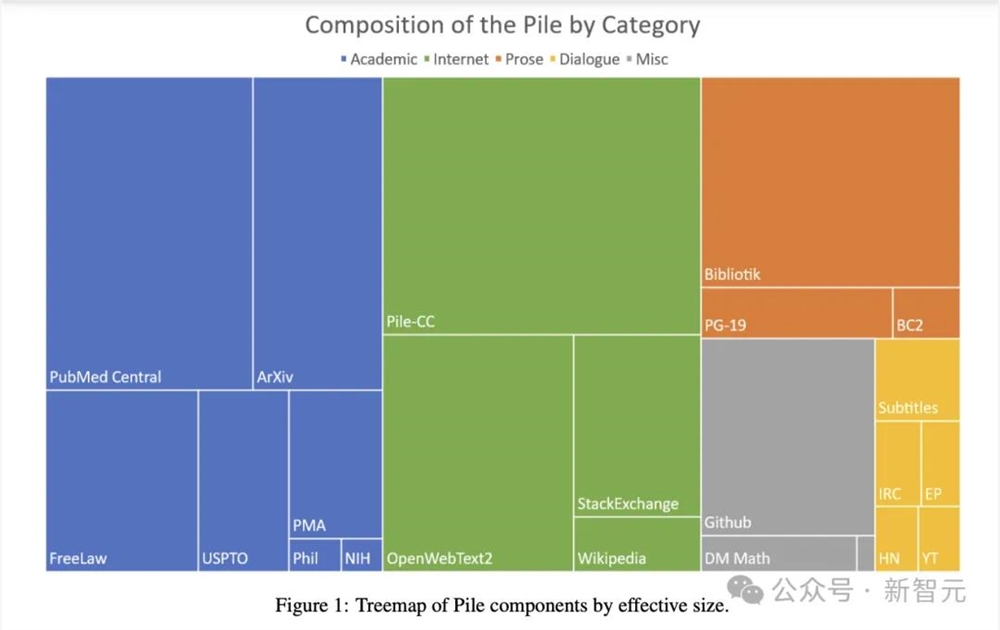
2020年非营利组织Eleuther AI构建的Pile,是NLP研究中应用最广泛的大型开源数据集之一,总量达到800GB。其中就包含了大量学术来源的文本,arXiv论文比例为8.96%,此外还涵盖了PubMed、FreeLaw、NIH等其他学术网站。
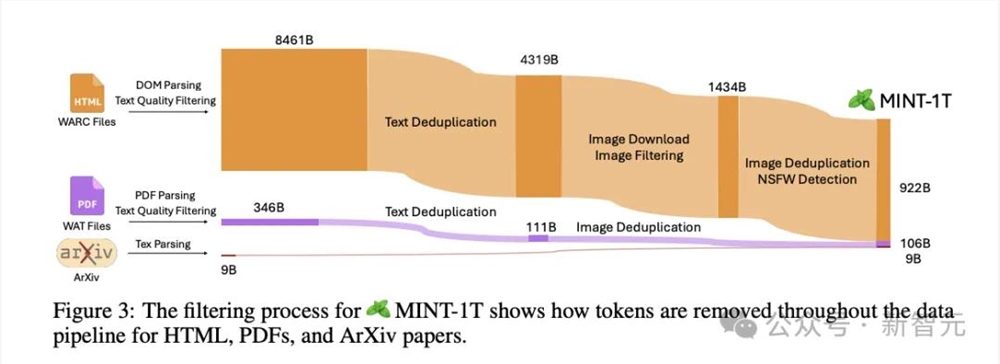
前段时间开源的1T token数据集MINT也挖掘到了arXiv这个宝藏,共提取到了87万篇文档、9B token。
从下面这张数据处理流程图中,我们就能发现论文数据的质量有多高——几乎不需要太多的过滤和去重,使用率极高。
而现在,为了应对版权争议,各大模型公司也开始真金白银地出价,购买高质量数据集了。
今年,「金融时报」已经把自己的内容以相当可观的价格,卖给了OpenAI;Reddit也和谷歌达成了类似的协议。
而以后,这样的交易也少不了。
证明论文曾被LLM使用,难度极高
有些AI开发者会开放自己的数据集,但很多开发AI模型的公司,会对大部分训练数据保密。
Mozilla基金会的AI训练数据分析员Stefan Baack表示,对于这些公司的训练数据,谁都不知道有什么。
而最受业内人士欢迎的数据来源,无疑就是开源存储库arXiv和学术数据库PubMed的摘要了。
目前,arXiv已经托管了超过250万篇论文的全文,PubMed包含的引用数量更是惊人,超过3700万。
虽然PubMed等网站的一些论文全文有付费墙,但论文摘要是免费浏览的,这部分可能早就被大科技公司抓取干净了。
所以,有没有技术方法,能识别自己的论文是否被使用了呢?
目前来说,还很难。
伦敦帝国理工学院的计算机科学家Yves-Alexandre de Montjoye介绍道:要证明LLM使用了某篇确定的论文,是很困难的。
有一个办法,是使用论文文本中非常罕见的句子来提示模型,看看它的输出是否就是原文中的下一个词。

有学者曾以「哈利·波特与魔法石」第三章的开头提示GPT-3,模型很快正确地吐出了大约一整页书中的内容
如果是的话,那就没跑了——论文就在模型的训练集中。
如果不是呢?这也未必是有效证据,能证明论文未被使用。
因为开发者可以对LLM进行编码,让它们过滤响应,从而不和训练数据过于匹配。
可能的情况是,我们费了老大劲,依然无法明确地证明。
另一种方法,就是「成员推理攻击」。
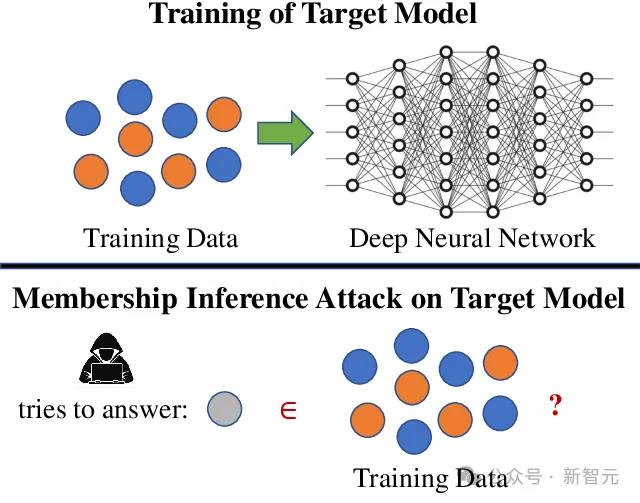
这种方法的原理,就是当模型看到以前见过的东西时,会对输出更有信心,

论文地址:https://arxiv.org/abs/2112.03570
为此,De Montjoye的团队专门开发了一种「版权陷阱」。

论文地址:https://arxiv.org/abs/2402.09363
为了设置陷阱,团队会生成看似合理却无意义的句子,并将其隐藏在作品中,比如白色背景上的白色文本或网页上显示为零宽度的字段。
如果模型对未使用的控制句的困惑度,比对隐藏在文本中的控制句的困惑度更高,这就可以作为陷阱曾被看到的统计证据。
版权争议
然而,即使能证明LLM是在某篇论文上训练的,又能怎么办呢?
这里,就存在一个由来已久的争议。
在出版商看来,如果开发者在训练中使用了受版权保护的文本,且没有获得许可,那铁定就是侵权。
但另一方却可以这样反驳:大模型并没有抄袭啊,所以何来侵权之说?
的确,LLM并没有复制任何东西,它只是从训练数据中获取信息,拆解这些内容,然后利用它们学习生成新的文本。
当然,这类诉讼已经有先例了,比如「纽约时报」对OpenAI那场石破天惊的起诉。
其中更加复杂的问题,是如何划清商用和学术研究用途。
根据目前arXiv网站上的使用条款,如果是个人或研究用途,抓取、存储、使用所有的电子预印本论文和网站元数据都是合规且被支持的。

然而,arXiv对商业方面的使用是严令禁止的。
那么问题来了,如果某个商业公司使用了学术机构发布的开源数据集训练自己的商业模型,且数据来源含有arXiv或类似学术出版机构,这怎么算?
此外,出版商在用户的订阅条款中往往也没有明确规定,能否将论文用作模型的训练数据。
比如,一个付费购买Wiley论文库阅读全文资格的用户,是否被允许将这些文本拷贝下来喂给模型?
现在的问题是,有人想让自己的作品纳入LLM的训练数据中,有人不想。
有人已经做出来一个[haveibeentrained」的同名网站,用来检测自己的内容是否被用于训练AI模型
比如Mozilla基金会的Baack就表示,非常乐于看到自己的作品让LLM变得更准确,「我并不介意有一个以我的风格写作的聊天机器人」。
但是,他只能代表自己,依然有其他很多艺术家和作家,会受到LLM的威胁。
如果提交论文后,这篇论文的出版商决定出售对版权作品的访问权限,那个别的论文作者是根本没有权力干涉的。
整个圈子也是鱼龙混杂,公开发表的文章既没有既定的方法来分配来源,也无法确定文本是否已被使用。
包括de Montjoye在内的一些研究者对此感到沮丧。
「我们需要LLM,但我们仍然希望有公平可言,但目前我们还没有发明出理想的公平是什么样子。」
多模态数据不够,arXiv来凑
事实上,庞大的arXiv论文库中,可以利用的不止文本数据。
ACL2024接收了一篇来自北大和港大学者的论文,他们尝试利用这些论文中的图文构建高质量多模态数据集,取得了非常不错的效果。

项目主页:https://mm-arxiv.github.io/
前段时间,纽约大学谢赛宁教授和Yann LeCun等人发布的Cambrian模型也用到了这个数据集。

之所以要用arXiv论文中的图片,主要还是由于科学领域训练数据集的稀缺。
GPT-4V等视觉语言模型虽然在自然场景的图像中有出色的表现,但在解释抽象图片方面,比如几何形状和科学图表,依旧能力有限,也无法理解学术图片中细微的语义差别。
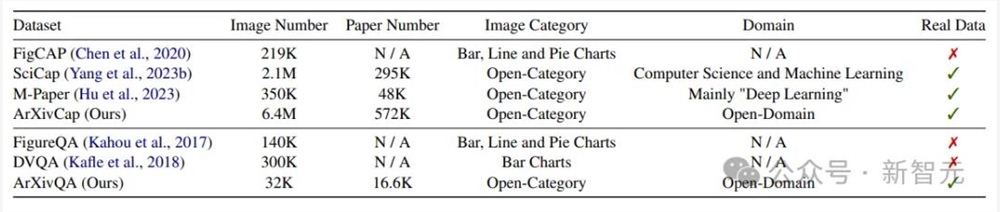
这篇论文构建的多模态arXiv数据集总共用到了各个STEM领域的57.2万篇论文,超过arXiv论文总数(2.5M)的五分之一,包含两部分:问答数据集ArXivQA和图片标注数据集ArXivCap。
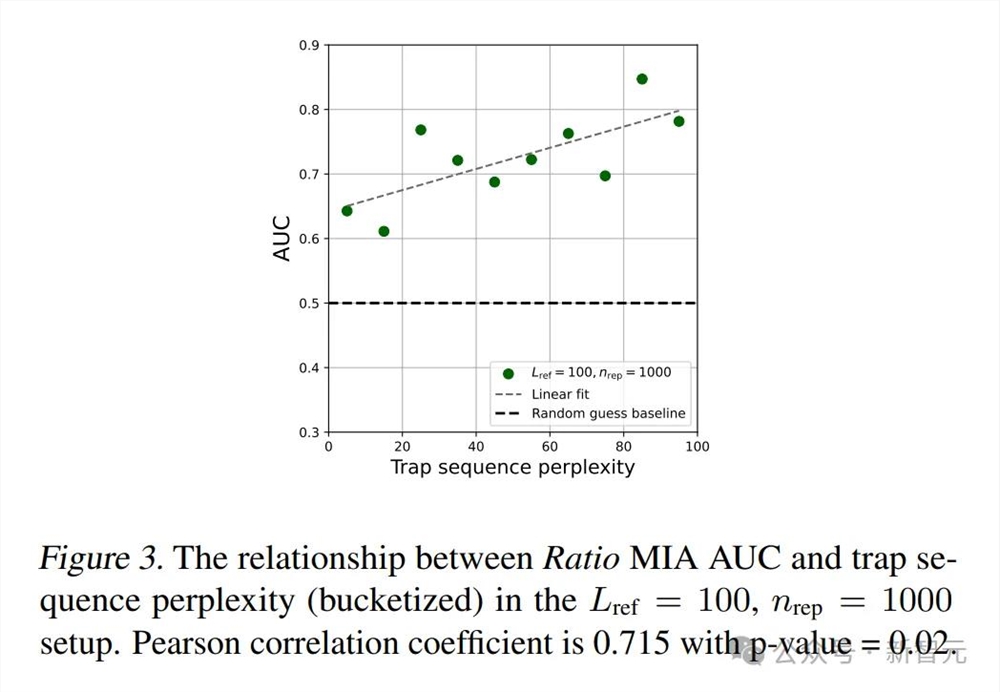
依托arXiv大量且多样的论文收录,与之前的科学图片数据集相比,ArXivCap的数据量是第二名SciCap的3倍,ArXivQA也是唯一涵盖广泛领域内真实论文的问答数据集。
通过使用这些领域特定数据进行训练,VLM的的数学推理能力有了显著增强,在多模态数学推理基准上实现了10.4%的准确率提升。
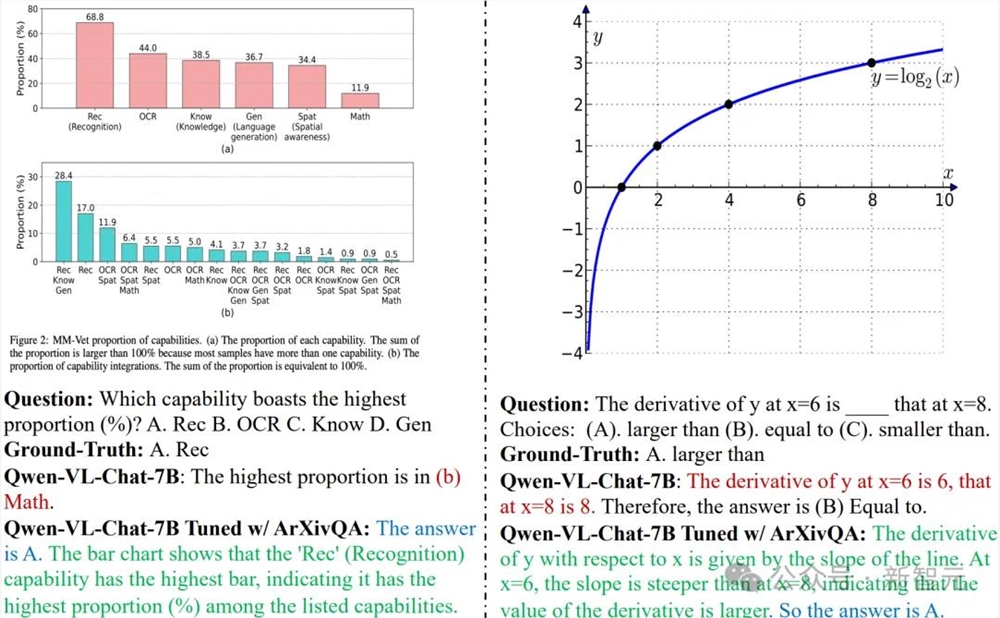
比如,在ArXivQA上训练过的Qwen7B模型能够正确理解条形图并回答相关问题(左图),数学能力也有所提高(右图)。不仅答案正确,给出的推理过程也更加完整充分。
数据集的构建流水线如下图所示。由于arXiv是预印本平台,所以需要先通过发表记录筛选出被期刊或会议接收的论文,以保证数据质量。
提取论文中的图片-文字对并进行基于规则的清理后,组成ArXivCap;ArXivQA则由GPT-4V生成,但使用了精心设计过的prompt模板。

ArXivCap中的一个单图标注对:
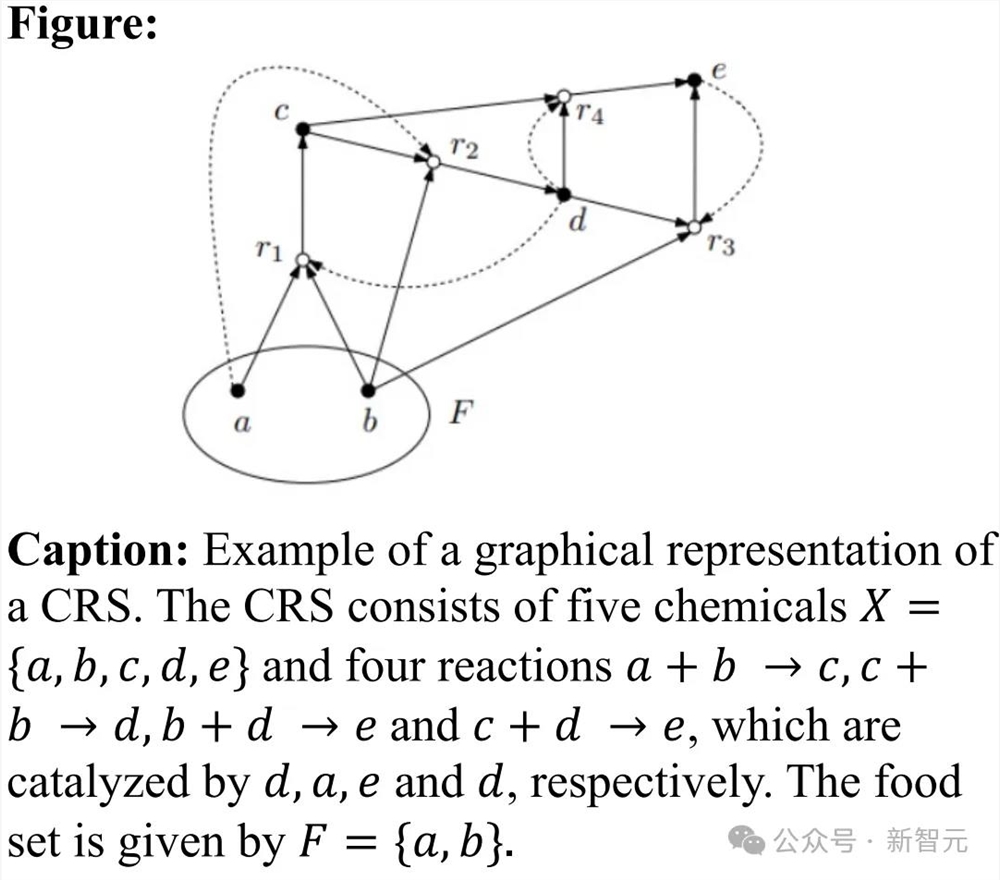
2019年论文「Semigroup models for biochemical reaction networks」
ArXivCap数据集中的一个多图标注对:
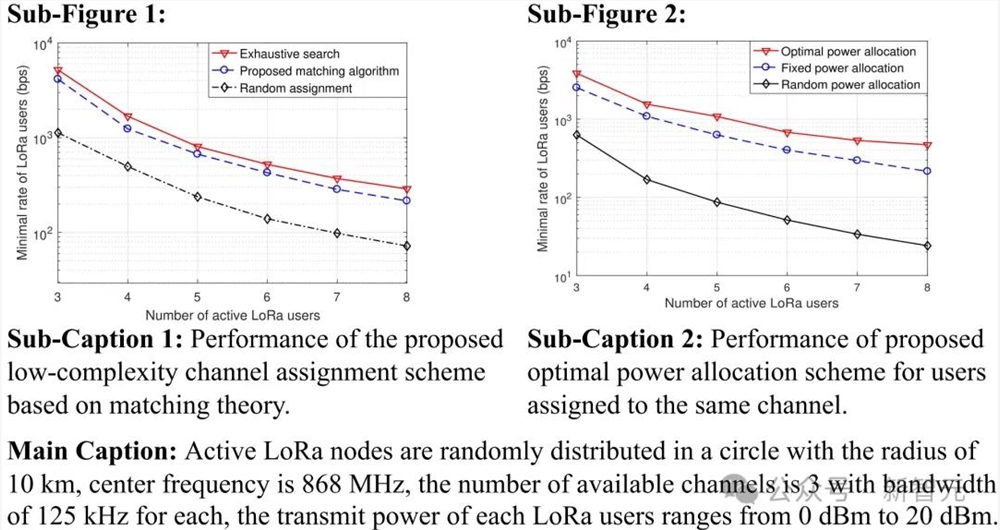
2018年论文「Low-Power Wide-Area Networks for Sustainable IoT」
ArXivQA数据集示例:

2020年论文「Skyrmion ratchet propagation: Utilizing the skyrmion Hall effect in AC racetrack storage devices」
根据在MathVista数据集上的结果,ArXivCap和ArXivQA共同提升了Qwen-VL-Chat的整体性能,超越了Bard的表现。
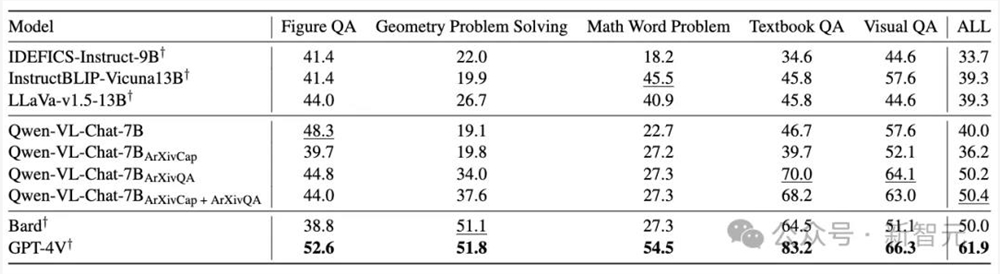
最佳结果以粗体显示,次佳结果以下划线标记
在为单张图片生成图注的任务中,提升效果更加显著,经过ArXivCap训练的Qwen7B模型可以匹配甚至超过GPT-4V。
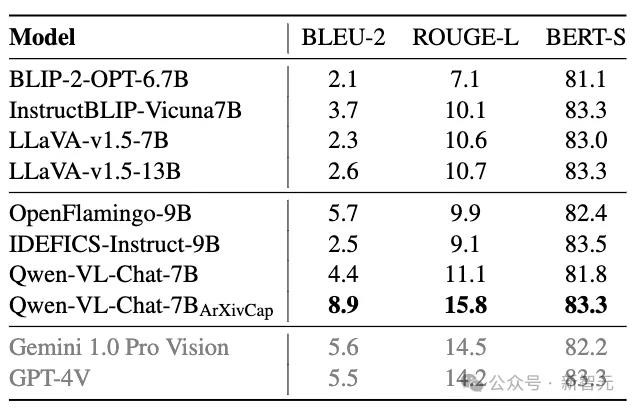
灰色结果由数据集中500个样本的测试得到
论文提出了三个新定义任务:多图的图注生成、上下文中的图注生成以及标题生成。经过ArXivCap训练的Qwen8B的所有分数都超过了GPT-4V,且多数情况下是最佳结果。
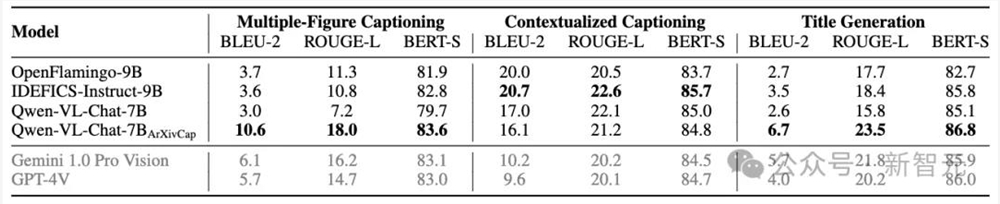
最佳结果以粗体显示
按照研究领域划分,ArXivQA数据集上的训练在天体物理、凝聚态物理、数学、计算机科学这些领域都能带来相当显著的提升,超过60%,准确率变化比例超过60%。
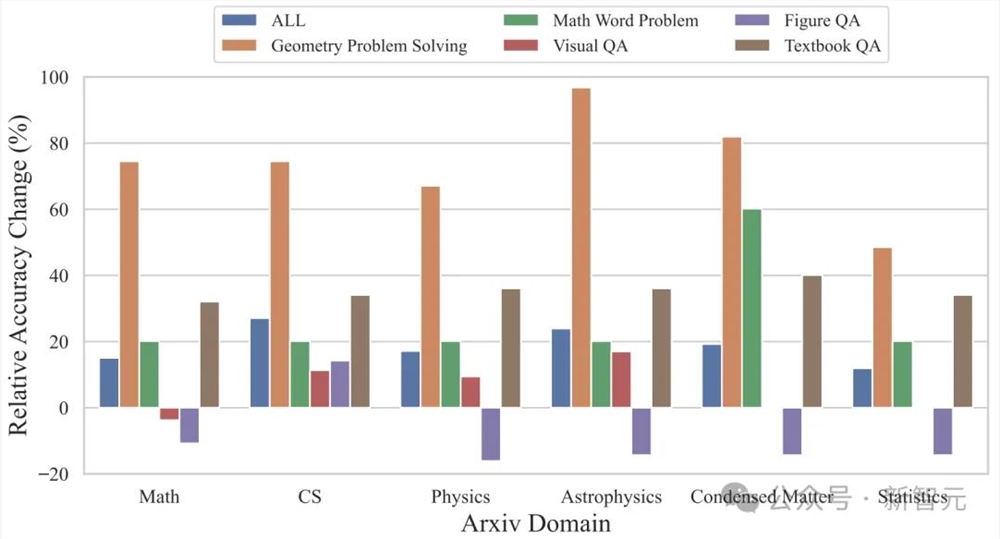
前面所述的文本生成质量和准确率都是基于算法的自动评估,研究团队还对单图的图注生成任务进行了人工评估,但只专注于计算机科学领域的论文。
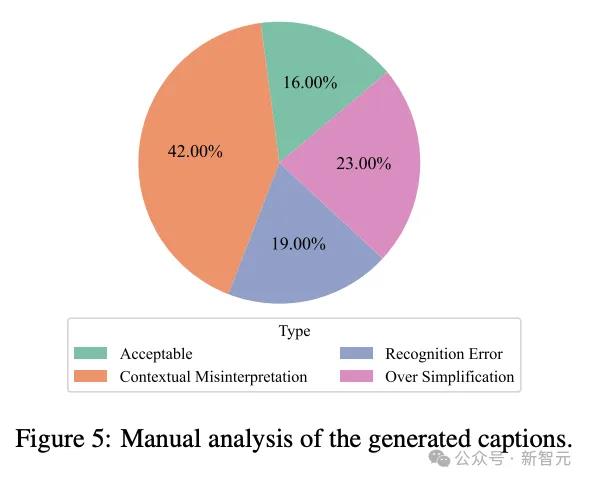
与前面的基准测试结果相比,人工评估的结果并不理想,100个案例中只有16%被认为是「可接受的」,「上下文误读」的问题相对严重,也有一定比例的「过度简化」和「识别错误」。

参考资料:
https://www.nature.com/articles/d41586-024-02599-9