声明:本文来自于微信公众号 AIGC开放社区,作者:AIGC开放社区,授权Soraor转载发布。
随着GPT-4o、Gemini等多模态大模型的出现,对训练数据的需求呈指数级上升。无论是自然语言文本理解、计算机视觉还是语音识别,使用精心标注的数据集能带来显著的性能提升,同时大幅减少所需的训练数据量。
但目前多数模型的数据处理流程严重依赖于人工筛选,不仅费时、费力并且成本非常高,难以应对大规模数据集的需求。
因此,谷歌Deepmind的研究人员提出了创新数据筛选方法JEST,通过联合选择数据批次来加速多模态大模型的学习效率。与目前最先进的算法相比,JEST可以将大模型的数据筛选效率提升13倍,算力需求降低10倍。
论文地址:https://arxiv.org/abs/2406.17711

JEST三种评分策略
传统的数据标注方法通常针对单个数据点进行操作,但一个批次数据的质量不仅取决于其内部各个数据点的独立质量,还受到它们组合方式的影响。那些难解的负样本,也就是标签虽不同却紧密聚集在一起的点,被证明比容易解决的例子更能提供有效的学习信号。
而JEST算法可以从更大的超级批次中高效地挑选出相关性高的子批次。与传统的优先级采样方法不同,JEST不是给每个单独的例子打分,而是对整个子批次进行评分,根据这些批次级别的分数进行采样。
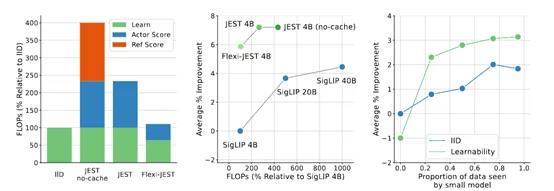
JEST的核心在于使用模型为基础的评分函数,这些函数结合了学习者模型的损失或预训练参考模型的损失,并提供硬学习者、易参考和可学习性三种评分策略。
硬学习者策略通过计算子批次在当前学习者模型下的高损失,选择那些模型尚未掌握的样本,以避免浪费资源在已知信息上。但是,对于大而杂乱的数据集,这种策略可能适得其反,因为会过度采样噪声样本。
易参考策略恰好相反,它优先选择对预训练参考模型而言比较的数据,损失较低的样本。这种策略在多模态学习中已被成功应用,用于识别高质量的例子,但缺点是过于依赖参考模型的选择,可能不适用于大规模计算预算。

可学习性策略则合了前两种方法的优点,通过计算学习者模型和参考模型的损失之差,选择那些既未被学习者掌握又对参考模型相对简单的样本。
这种策略既能避免噪声数据的干扰,又能保证选取的数据是模型可以学习,因此在大规模学习中即使对单个例子进行优先级排序也能加速训练过程。
模型近似和多分辨率训练
为了进一步增强JEST算法的性能以及对算力需求的降低,还使用了模型近似和多分辨率训练两种方法。
模型近似主要通过两种方式实现:一是降低图像分辨率,二是减少模型层的计算,帮助大模型在保持模型性能的同时,显著减少每次迭代所需的算力需求。
降低图像分辨率是一种直观的近似方法。在传统的高分辨率图像处理中,模型需要对每一个像素点进行分析和学习,这无疑增加了算力负担。
而在JEST算法中,通过将图像分辨率降低,减少了模型需要处理的像素数量,从而降低了单次迭代的计算成本,并且对模型的性能影响很小。
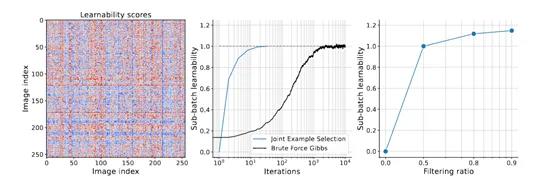
减少模型层的计算则是另一种有效的近似手段。深度学习模型通常包含多个层次,每个层次都可能带来计算量的增加。JEST算法通过在评分阶段使用简化的模型结构,减少了模型在每次迭代中的算力负荷,也不会影响模型最终的训练结果。
多分辨率训练允许模型在不同的分辨率下处理数据,从而在训练过程中实现更高的灵活性和效率。
在多分辨率训练中,模型首先在较低分辨率下对数据进行初步处理,这有助于快速捕捉数据的大致特征。然后,模型在较高分辨率下对数据进行更细致的分析,以提取更精细的特征信息。这种分阶段的处理方式不仅提高了模型对数据的理解能力,也使得模型能够在不同层次上进行有效的学习。
此外,多分辨率训练还有助于提高模型的泛化能力。通过在不同分辨率下训练,模型能够学习到不同尺度的特征,这使得模型在面对不同尺寸和分辨率的输入数据时,都能够表现出良好的适应性。
为了测试JEST算法的有效性,在ImageNet、COCO等数据集上,对图像分类、零样本学习、图像到文本的检索和文本到图像检索等任务上进行了综合测试。
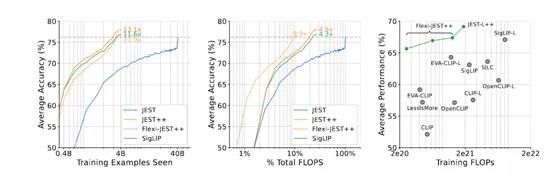
结果显示,JEST在多个任务上都取得了显著的数据筛选效率,例如,当过滤90%的数据时,JEST仅需使用6700万样本即可达到传统方法使用30亿样本的性能水平,相当于效率提升13倍和算力降低了10倍,同时还能帮助大模型提升大约6%的性能。