声明:本文来自于微信公众号 元宇宙日爆,作者:元宇宙日爆,授权Soraor转载发布。
近日,人类神经科学和人工智能交叉领域的学者Gary Marcus发文,对生成式人工智能的未来做出了大胆预测:在接下来的12个月内,当前围绕生成式人工智能的泡沫将会破裂。他认为,“生成式人工智能最根本的缺陷在于其可靠性问题”,系统仍会产生幻觉进而生成虚假信息。
Marcus近年因在神经科学和人工智能交叉领域的研究而闻名,也是“呼吁暂停研究比GPT-4更强大的AI系统训练6个月”公开信的签名学者之一。一直以来,Marcus都认为当前的大语言模型(LLMs)是“近似于语言使用而非语言理解”。
这位既是AI学者又有AI创业经验的专家,将支撑生成式AI背后的大语言模型(LLMs)比作“乘法表”——GPT们能熟记表内乘法并给出正确答案,但对表外乘法的答案得靠碰运气,更多时候因不具备自我验证能力而给出错误答案。
在他看来,为了避免幻觉导致的错误信息,研发LLMs的公司不得不造更大的模型,塞更多的数据,但这没有解决从根本上解决LLMs无法对自己的工作进行健全性检查的问题。
由于有认知心理学、神经学与人工智能交叉领域的学术背景,Marcus一直倡导神经符号学人工智能——一种将神经网络技术与逻辑学、计算机编程以及传统人工智能中普遍应用的符号方法融入AI研究的理论,他认为这一方法是自主AI的路径之一。
而Marcus认为,神经符号学AI因学术权威打压、资本担忧创新风险而无法成为AI研发的主流。不过,令Marcus欣慰的是,Google DeepMind的两套AI系统AlphaProof和AlphaGeometry2正验证了神经符号学AI的可行性。在他看来,Google的方向更接近AGI的路径。
以下是Gary Marcus《AlphaProof、AlphaGeometry、ChatGPT,为什么人工智能的未来是神经符号学?》全文编译:
引言
生成式人工智能(Generative AI)以其标志性的聊天机器人ChatGPT为代表,已经在全球范围内引发了广泛的关注和想象,然而,这种热潮可能即将退去,但不会完全消散。
曾经,“生成式AI最终将证明是无效”的观点被视为边缘意见,备受轻视。但如今,这一观点已经转变为广泛接受的预期,每天都有新的评论在主流媒体上发表,呼应着这一看法。
我坚信,在接下来的一年内,我们将目睹生成式AI泡沫的破裂,原因众多:
当前的技术方法似乎已抵达一个发展的瓶颈期
缺乏那种能够彻底改变游戏规则的杀手级应用
系统仍然会产生幻觉,即在没有确凿依据的情况下生成虚假信息
依然存在一些低级错误,反映出技术的不成熟
没有一家公司或技术能够建立起持久的竞争优势,即所谓的"护城河"
人们开始逐渐意识到上述问题
当生成式人工智能的泡沫逐渐破裂,一些人可能会因其高估和过度炒作而感到庆幸,而另一些人则可能对其衰退感到悲哀。我本人则持有一种矛盾的情感:虽然我认为生成式AI的光环被过分夸大,但我同样忧虑,它的衰退可能会触发一场类似20世纪80年代中期的“AI寒冬”,那时的“专家系统”经历了快速的崛起与跌落。
尽管如此,我确信这场即将到来的崩溃不会标志着人工智能的终极消亡。毕竟,人工智能领域牵涉到的利益关系太过深远。
生成式AI的衰退或许会在一段沉寂之后迎来复兴的曙光,它可能不再像过去一年那样备受追捧,但新的技术革新将应运而生,它们将更为高效,能够弥补生成式AI的不足之处。
生成式人工智能最根本的缺陷在于其可靠性问题,鉴于其固有性质,我认为这个问题永远无法解决。在考虑生成式人工智能之后可能出现的情况之前,我们需要了解生成式人工智能的固有性质。
因此,本文将分为两部分:第一部分是对生成式AI及其局限的直观阐释;第二部分则探讨了可能克服这些局限的解决之道,特别是围绕Google DeepMind近期的一项令人瞩目的新成果——这是今年为数不多让我感到振奋的AI进展之一。
大语言模型为何有效又为何失败?
尽管我们能够编写大型语言模型(LLMs)的代码,却没有人能够完全理解它们的内部机制,或是预测它们在任何特定时刻的行为。部分原因在于,它们的输出极大地依赖于其训练数据的细节。然而,即便如此,我们仍能培养出一种基本的直觉,即便这种直觉略显粗糙。
在某种程度上,我们可以将生成式AI比作一个查找表,就像大家熟悉的乘法表。乘法表对于其内部包含的条目非常有用,但对于表外的情况则无能为力。例如,如果你的乘法表只覆盖到12乘以12,那么当你需要计算13乘以14时,你会发现自己束手无策,因为答案并不存在于表中。
系统性研究发现,LLMs在处理数学问题时也表现出类似的局限性,它们在处理较小的乘法问题(如四位数乘以四位数)时表现得更为出色,而在处理更大的问题(如六位数乘以六位数)时则力不从心。此外,它们在处理曾经训练过的问题时比处理未训练过的问题更为得心应手。
LLMs虽不是简单的查找表——它们能够进行一定程度的泛化——但它们与查找表的相似性足以帮助我们建立起直观的理解。经验一再告诉我们,LLMs在处理它们曾经遇到过的问题时,比处理新问题更为有效。当新问题在关键和微妙层面与旧问题不同时,它们会表现得尤其糟糕。
在众多GPT模型的"失败"案例中,统计学家兼机器学习专家Colin Fraser提供的许多例子最具启发性,他喜欢用细微的变化来考验最新模型的极限。以下是一个典型的例子:

仔细观察不难意识到ChatGPT给出的答案明显违背了常识,“医生是男人的另一位父母——他的母亲”完全错误,因为前文提到男人的母亲已经去世。
为什么ChatGPT会把事情搞得这么糟?
原因在于ChatGPT系统依赖于训练集中的传统谜题(其查找表功能的输入)来生成答案,但它未能深入理解问题的本质。举例来说,ChatGPT可能曾接受过这样的训练案例:
一位父亲和他的儿子遭遇车祸。父亲当场死亡,儿子被送往最近的医院。医生进来大喊:“我不能给这个男孩做手术。”
“为什么不呢?”护士问。
“因为他是我的儿子,”医生回答。
在ChatGPT错误引用的这个经典案例中,医生确实是患者的母亲。然而,作为一个单纯的文本预测器,ChatGPT根本无法识别它记忆的答案(“孩子的母亲”)在Fraser的复述中没有意义。它没有真正地推理(LLMs本质上并不具备这样的能力),而是检索了一个类似但有细微差别的问题答案,结果是错误的。
Fraser还探讨了经典的“带狼、山羊和卷心菜过河”的谜题,同样的现象也会出现。经典版本如下:
一个农夫想要过一条河,并带着一只狼、一只山羊和一颗卷心菜。
有一艘可以容纳他自己的船,外加一只狼、一只山羊或一棵卷心菜。
如果狼和山羊单独在岸边,狼会吃掉山羊。如果山羊和卷心菜单独在岸边,山羊会吃掉卷心菜。
农夫怎样才能让狼、山羊和白菜过河呢?
这需要精心的计划和多个步骤。
然而,当Fraser提出一个幽默的变体时,ChatGPT给出的答案在文本上类似于经典谜题的解答,但在这种情况下却完全不适用。它提出的解决方案不仅极其低效,而且缺乏常识。

每当Fraser或其他人(比如我自己)在社交媒体上分享这样的案例时,总会有爱好者提出自己的变体,使用不同的提示和LLMs。但结果总是一样,一些系统能够正确处理某些变体,但很少有系统能够做到始终可靠。总的来说,这些系统是不可靠的,这也是财富500强公司在最初的炒作后对LLMs失去了信心的原因之一。
我研究神经网络已有30多年(这是我论文的一部分),并且从2019年开始研究LLMs。我强烈的直觉是,LLMs根本就不可能可靠地发挥作用,至少不会像去年许多人所希望的那样以一般形式发挥作用。也许最深层次的问题是,LLMs实际上无法对自己的工作进行健全性检查。
LLMs本质上只是下一个词的预测器——或者,正如我曾经说过的,“超级自动完成”——没有内在的方式来验证它们的预测是否正确。缺乏这种检查导致它们在算术上犯错、犯愚蠢的错误、编造事实、诽谤他人等等,在从GPT-2、GPT-3到GPT-4再到最新的SearchGPT,每一个模型都是如此。用一句可能源自12-step社区的名言来说:“疯狂的定义是一遍又一遍地做同样的事情,并期望不同的结果。”
因此,LLMs中的任何“推理”或“计划”都是偶然的,如果特定情况的细节足够接近训练集中的内容,那么它是可行的,但如果不是就会非常脆弱。正如马克·吐温所说,“几乎正确的词和正确的词之间的区别真的很大”,这就像“萤火虫和闪电之间的区别”。
真正可靠的人工智能方法和偶尔通过类比存储的示例起作用的方法之间,区别也同样巨大。
幻觉、推理上的愚蠢错误以及我所说的“理解失调”,在我看来是LLMs不可避免的副产品。在某些时候,我们必须做得更好。
神经符号学人工智能指明了方向
鉴于大型语言模型(LLMs)不可避免地会产生幻觉,并且在本质上无法对自己的输出进行合理性检验,我们实际上面临两种选择:要么放弃这些模型,要么将它们融入更庞大的系统中,作为这些系统的一部分来实现更高级的推理和规划。
这类似于成年人和年长儿童使用乘法表辅助解决乘法问题,而不是依赖它作为唯一的解决方案。
在我的整个职业生涯中,无论是在认知科学的背景下,还是专注于人工智能的研究,我都提倡采用混合方法——神经符号学AI。这种方法融合了当前流行的神经网络技术(其设计灵感大致来源于1960年代的神经科学发现)与逻辑、计算机编程以及传统人工智能中普遍应用的符号方法。
我们的目标是汇聚两种方法的优势:利用神经网络在处理熟悉示例时的快速直觉能力(类似于丹尼尔·卡尼曼所说的系统I),同时结合显式的符号系统,运用形式逻辑和其他推理工具进行深入分析(类似于卡尼曼的系统II)。
这正是我在2001年出版的《代数思维》一书中的核心议题。该书副标题所表达的是尝试将连接主义(即神经网络)与操纵符号的认知科学相结合。

然而,科学界的权力结构和学术社会学已经让AI领域遭受了不小的损失。
在AI界,两位极具影响力的人物(在我看来也是最具误导性的人物)Geoffrey Hinton和Yann LeCun,多年来一直反对这种潜在的方法,并通过无休止的人身攻击来抵制不同的声音,尽管原因各不相同,但从未得到充分解释。
LeCun最近对神经符号学方法表达了悲观态度,他表示:“至少可以说,我对神经符号学方法非常怀疑。你不能使逻辑推理与基于梯度的学习兼容,因为它是离散的,不可微的。”(在我看来,这表明想象力不足,我们将在下文中讨论这个问题)
Hinton则认为将符号与神经网络结合,就像是将过时的燃气发动机无端地附加在更先进的电动机上。他们的质疑和嘲讽在学术界引起了共鸣。Hinton还认为,符号(很大程度上是由他的曾曾祖父乔治·布尔开发的)就像燃素一样,是一个巨大的科学错误。
OpenAI在很大程度上追随了Hinton和LeCun的理念,将主要精力投入到“扩展”LLMs上,即让模型规模越来越大,数据量越来越丰富,并尽量避免使用符号和符号规则,即便在不可避免时也将其隐藏起来。
大多数其他的大型企业和投资者也采取了相似的策略,他们更倾向于追求那些立竿见影的短期成果,而不是冒险投资于那些可能真正颠覆现有领域的创新思想。
正如Phil Libin在今天的短信中向我指出的,“AI的进步需要算法上的创新,而不仅仅是规模的扩大。为何这会引起争议?因为算法创新是不可预测的,是民主化的。现在的金钱主宰着一切,它急功近利,专横跋扈。作为一个投资者,我更愿意投资一万亿美元去建造芯片工厂(并在过程中获得一些收益),也不愿意在未来的发明上冒险。”
这种以短期投资为主的氛围极大地限制了对真正新奇和创新思维的追求。
因此,我们发现自己陷入了一个局面,几乎所有的主要技术公司都在制造本质上相同的产品——基于大量数据的庞大LLMs,得到的成果也几乎如出一辙(一系列GPT-4级别的模型,它们之间几乎没有区别,都在与幻觉和愚蠢的错误作斗争),而对其他任何事物的投资却微乎其微。
好消息是,在这股潮流中,Google DeepMind(以下简称GDM)从未如此教条并以冒险精神脱颖而出,值得称赞。不同于其他公司固守传统,GDM始终保持着探索未知的勇气。
让我印象深刻的是GDM近期在国际数学奥林匹克竞赛中取得的进展。他们不仅荣获银牌,更是以卓越成绩超越了大多数人类的能力。
这一成就的背后是GDM开发的两个先进系统:专注于定理证明的AlphaProof,以及专注于几何问题、更新版的AlphaGeometry2。这两个系统都是神经符号学AI的典范,它们将神经网络的直觉力与符号推理的严谨性完美结合。
正如GDM明确指出,AlphaGeometry是一个结合了神经语言模型和符号推理引擎的神经符号学系统,它们协同工作,为复杂的几何定理寻找证明。这种设计类似于人类思维中的“快速思考”与“慢速思考”,一个系统提供快速直观的想法,另一个则进行深思熟虑、理性的分析。
今年早些时候,GDM明确指出了AlphaGeometry的神经符号本质:
AlphaGeometry是一个结合了神经语言模型和符号推理引擎的神经符号学系统,它们协同工作,为复杂的几何定理寻找证明。这种设计类似于人类思维中的“快速思考”与“慢速思考”,一个系统提供快速直观的想法,另一个则进行深思熟虑、理性的分析。
在描绘原始AlphaGeometry的图中(新系统尚未提供,但它们看起来基本相似),你可以非常直接地在中间框中看到其“直观”语言模型(LLM)与审议符号引擎之间的交互。
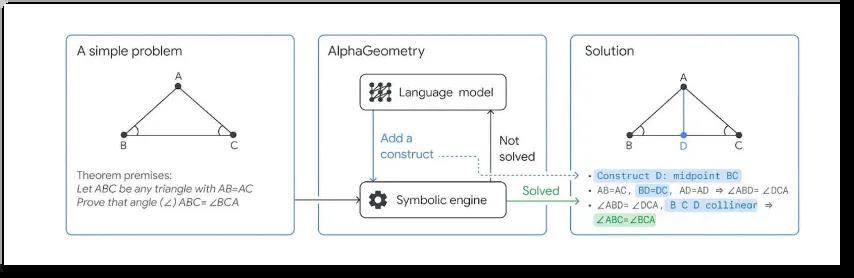
而在新的系统中,GDM进一步强化了这种交互,采用了基于Gemini、经过大量合成数据训练的语言模型,并引入了AlphaProof这一新系统,它同样采用了神经符号学结构,将语言模型的输入用于在Lean证明助手系统中搜索和验证形式证明。
尽管我对这两个系统充满敬意,但它们也存在一个明显的缺陷:它们依赖于人类编码者将奥林匹克的输入句子翻译成数学形式。这表明,如果没有人类编码者的参与,我们还不能实现真正的自主AI。
这让我回想起我曾写过的Doug Lenat的复杂符号系统,他在《人工智能的下一个十年》中展示了如何用符号系统解读《罗密欧与朱丽叶》。尽管符号推理表现出色,但背后依然需要人类的翻译工作。
尽管存在争议,GDM的最新成就却是对概念验证的一次有力展示!它证明了神经网络与符号系统的结合不仅可行,而且能够取得显著成果,这与Hinton和LeCun的怀疑态度形成了鲜明对比。
谷歌DeepMind已经勇敢地迈出了这一步,尽管还有许多其他研究者也在这一领域取得了进展,但GDM的成果无疑是其中最引人注目的。
Doug Lenat,以其开创性的常识知识库Cyc而闻名,是人工智能领域真正的思想巨人。他对推理的微妙性和挑战有着深刻的理解,远超许多当代AI研究者。去年夏天,我有幸与Doug合作,完成了他生前最后一篇论文,题为《从生成式人工智能到可信赖人工智能:LLMs可能从Cyc学到什么》。
在这篇论文中,我们探讨了神经符号学人工智能的潜力,并在文末提出了五种将符号系统集成的方法。AlphaProof和AlphaGeometry2正是我们讨论的第一种方法的体现,它们利用类似于Cyc这样的正式系统来审查由LLMs生成的解决方案。
我们还提出了使用像Cyc这样的符号系统作为真理的源泉,引导LLMs朝着正确性发展。事实上,这种方法已经在为AlphaProof和AlphaGeometry2生成合成数据时得到了应用,虽然不是直接使用Cyc,但采用了在关键方面与Cyc类似的系统。
尽管如此,神经符号学方法的发展空间仍然巨大。正如我在其他场合所强调的,神经符号学本身并非万能钥匙或灵丹妙药。我们还需要更多的基础建设,包括知识基础设施的构建,以及从文本和视频等输入中派生出认知模型的方法。但这些步骤对于我们走向更遥远的旅程是必不可少的。
归根结底,期望AI在没有符号操作的“系统II”机制下实现通用人工智能(AGI),无异于期待熊能解决量子力学问题。没有神经符号人工智能,我们无法找到通往AGI的道路。我很高兴看到Google DeepMind已经朝着这个方向迈出了坚实的步伐。