声明:本文来自于微信公众号新智元,作者:新智元,授权Soraor转载发布。
【新智元导读】斯坦福炒虾机器人作者,又出新作了!通过模仿学习,达芬奇机器人学会了自己做「手术」——提起组织、拾取针头、缝合打结。最重要的是,以上动作全部都是它自主完成的。
斯坦福炒虾机器人作者,又出新作了。
这次,机器人不是给我们炒饭了,而是给我们做外科手术!
最近,约翰霍普金斯和斯坦福大学的研究者们,进行了一项新的探索——
著名的医疗机器人达芬奇,是否可以通过模仿学习,来学习外科手术的操作任务呢?
经过实验后,他们成功了!
组织操作、针头处理和打结这三项基本的手术任务,达芬奇都可以自己独立完成了。
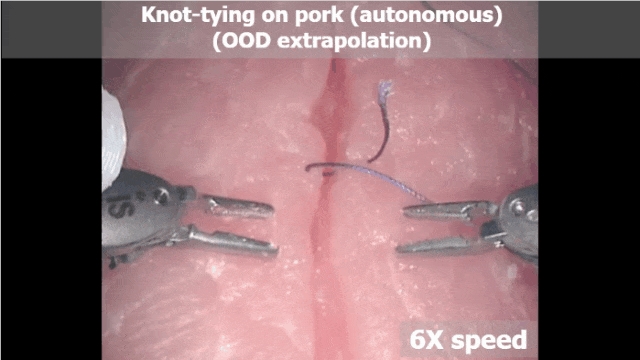
首先是需要医学生苦练指法的缝合打结技术,只见达芬奇「飞针走线」,很熟练地就可以把结打好:

接下来是针的拾取和移交,达芬奇也能够一次精准操作,动作绝无拖泥带水。

第三大任务是提起组织,可以看到达芬奇选择了正确着力点,轻松提起了组织。

最重要的是,以上动作全部都是达芬奇自主完成的!
翻开研究作者一栏,赫然出现了炒虾机器人的作者Tony Zhao和Chelsea Finn。

果然,这种程度的精细操作,怎么看都有一股熟悉的味道。

论文地址:https://arxiv.org/abs/2407.12998
博客地址:https://surgical-robot-transformer.github.io/
要知道,跟家庭环境中的桌面操作相比,手术任务需要精确操纵可变形物体,还要面对不一致的照明和遮挡的硬感知问题。
另外,手术机器人通常可能还有不准确的本体感觉和迟滞。
这些问题,他们都是如何克服的?
大型临床数据存储库,机器人可以学习了
大规模模仿学习,在操作任务的通用系统上显示出了巨大的前景,比如让机器人给我们做家务。
不过这次研究者们盯上的,是外科领域。
外科领域是一个尚未开发、潜力巨大的领域,尤其是在达芬奇手术机器人的加持之下。
截止2021年,全球已经有67个国家使用了6500套达芬奇系统,进行了超过1000万例手术。
而且,这些手术的过程都被全程记录了下来,从而让我们有了大量的演示数据存储库。
如此大规模的数据,能否利用起来,构建一个自主手术的通才系统?
然而,当研究者们下手研究时却发现:让达芬奇机器人通过模仿学习来做外科手术,存在一个难点——
由于达芬奇系统本身的特殊性,就导致了独特的挑战,阻碍了模仿学习的实施。
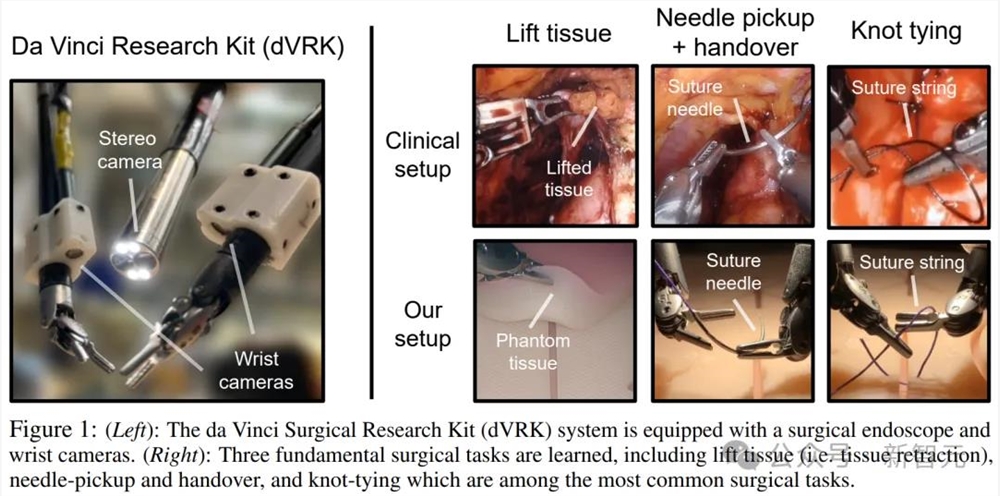
右上是真实的医疗环境,右下是研究人员的实验设置
而且,由于联合测量不精确,其正向运动学就会不一致,如果只是简单地使用这种近似运动学数据训练一个策略,通常会导致任务的失败。
很简单的视觉伺服任务,机器人也无法执行。训练输出绝对末端执行器姿势的策略(这是训练机器人策略的常用方法),在所有任务中的成功率都接近于0。
怎样克服这种限制?
团队发现,达芬奇系统的相对运动,比它的绝对正向运动学更加一致。
因此,他们想到一个办法:引入一种相对动作公式,使用它的近似运动学数据,来进行策略训练和部署。
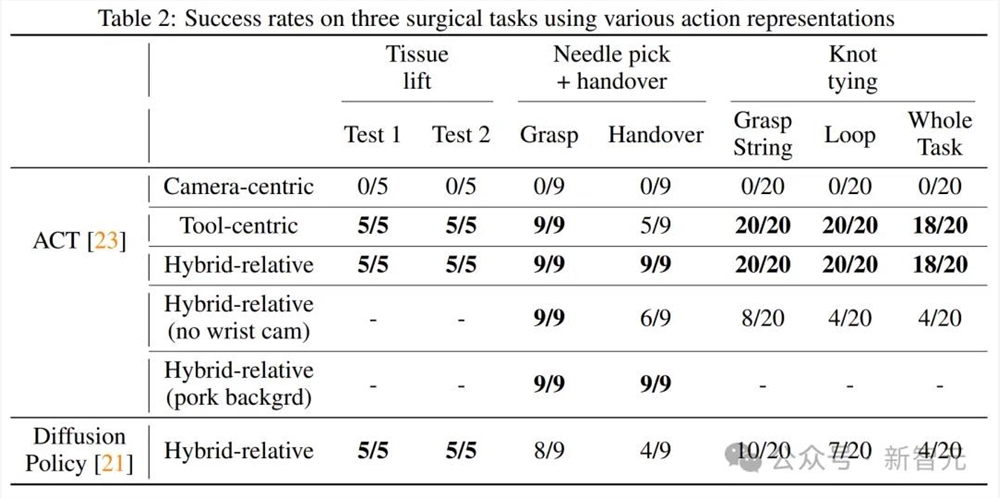
他们考虑了以下三个选项:以相机为中心、以工具为中心和混合相关操作。
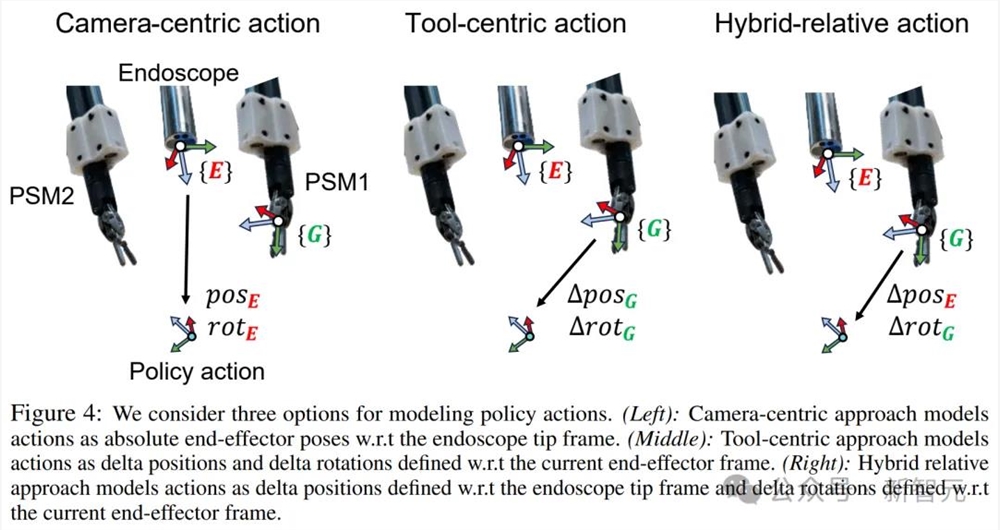
以相机为中心的动作表示是一种基线方法,它将动作建模为末端执行器相对于内窥镜尖端的绝对姿势。另外两个是定义相对于当前工具(即末端执行器)框架或内窥镜尖端框架的动作的相对公式
然后,使用图像作为输入和上述动作表示,来训练策略。
这一点,他们的做法跟此前的工作不一样,后者会使用运动学数据作为输入,然而在这项工作中,达芬奇的运动学数据可能并不可靠。
他们的模型基于ACT,一种基于Transformer的架构。
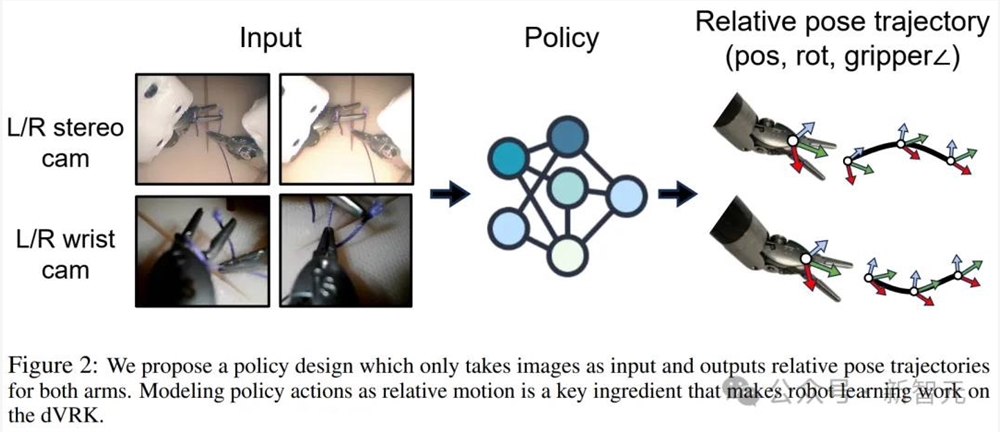
团队提出了一种策略设计,仅将图形作为输入,并输出相对姿态轨迹
如果这种方法成功,那么包含近似运动学的大型临床数据存储库,就可以直接用于机器人学习,而无需进一步校正了。
这对于机器人的临床手术操作,无疑意义重大。
果然,在引入相对动作公式后,团队便利用近似运动学数据,在达芬奇上成功地演示了模仿学习,不仅不需要进一步的运动学矫正,而且效果也大大优于基线方法。
实验表明,模仿学习不仅可以有效地学习复杂的手术任务,还能推广到新的场景,比如在看不见的真实人体组织上。
另外,腕式摄像机对于学习手术操作任务,也十分重要。

现在,除了之前已经展示的组织操作、针头处理和打结等自主任务外,达芬奇机器人还可以完成下面多种操作。
斯坦福团队的模型显示出了适应新场景的能力,例如在出现未知的动物组织的情况下。
这是一段达芬奇在缝合猪肉并打结的视频——
换成是鸡肉,达芬奇也能精确地拿起放在肉表面的手术针。

这显示出其在未来临床研究中进行扩展的前景。
那么,如果存在一些环境扰动,达芬奇是否还能稳定发挥呢?
可以看到,在其他器械突然闯入,并将手术缝合线故意剥落之后,达芬奇并没有停下动作,仍然将打结行为进行了下去。

在下面整段视频中,达芬奇在第一次操作中没有拾起手术针,它很快意识到了这一事实,通过自动调整成功拾取。

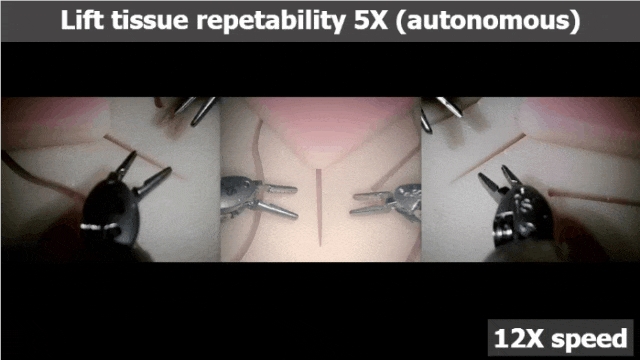
临床手术非同儿戏,必须保证临床机器人具有可重复性,「万无一失」是其必要能力。
研究团队放出了达芬奇的重复性测试视频,在不同视角下观察它的多次操作,基本无可挑剔。

技术路径
如下图所示,达芬奇机器人的dVRK系统,由一个内窥镜摄像操纵器(ECM)和两个共享同一机器人底座的患者侧操纵器(PSM1、PSM2)组成。
每个手臂都是被动设置关节的顺序组合,而后面是机动主动关节。
然而,一般情况下,如果在所有关节中都使用电位器,会导致手臂的正向运动学不准确,甚至有高达5厘米的误差。
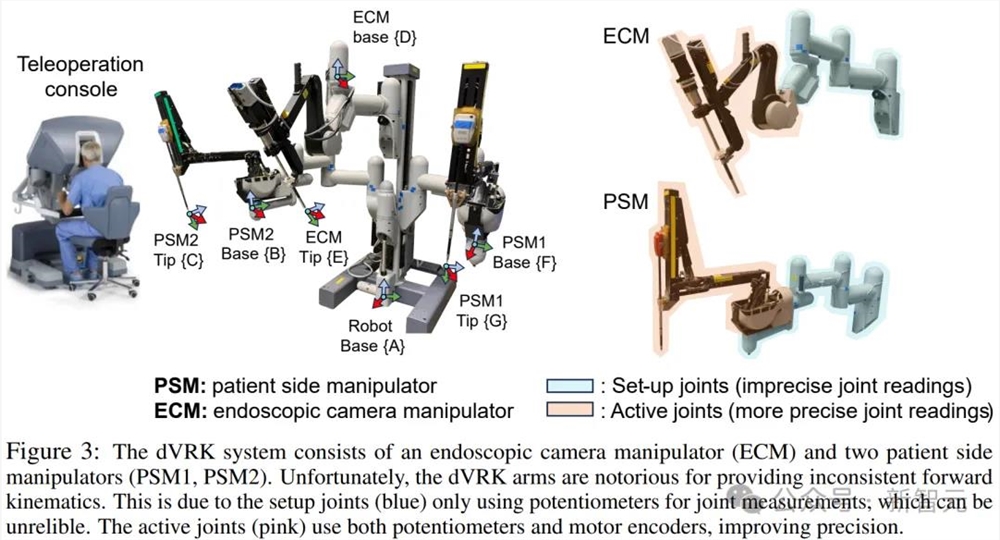
不幸的是,dVRK提供的正向运动学数据并不稳定。这是因为设置关节(蓝色)仅使用电位计进行关节测量,并不可靠。主动关节(粉色)同时使用电位器和电机编码器,提高了精度
为了让达芬奇完成通过模仿学习来完成手术操作任务这一目标,鉴于机器人的前向运动学不准确,团队提出了前文中所提到的三种动作表示法,其中混合相对方法进一步提高了平移动作的准确性。
执行细节
为了训练可行的策略,研究使用带有Transformer的动作分块(ACT)和扩散策略。
他们使用了内窥镜和手腕相机图像作为输入来训练策略,这些图像均缩小为224x224x3的图像尺寸。
手术内窥镜图像的原始输入尺寸为1024x1280x3,手腕图像为480x640x3。
运动学数据不像其他模仿学习方法中常见的那样作为输入提供,这是因为由于dVRK的设计限制,运动学数据通常不一致。
策略输出包括末端执行器(delta) 位置、(delta) 方向和双臂下颌角度。
实验过程
在这次实验中,研究者的目标是弄清这些问题的答案——
模仿学习是否足以应对复杂的外科操作任务?
dVRK的相对运动是否比其绝对前向运动学更稳定?
使用腕式摄像头是否对提高成功率至关重要?
模型在未见过的新场景中能否有效泛化?
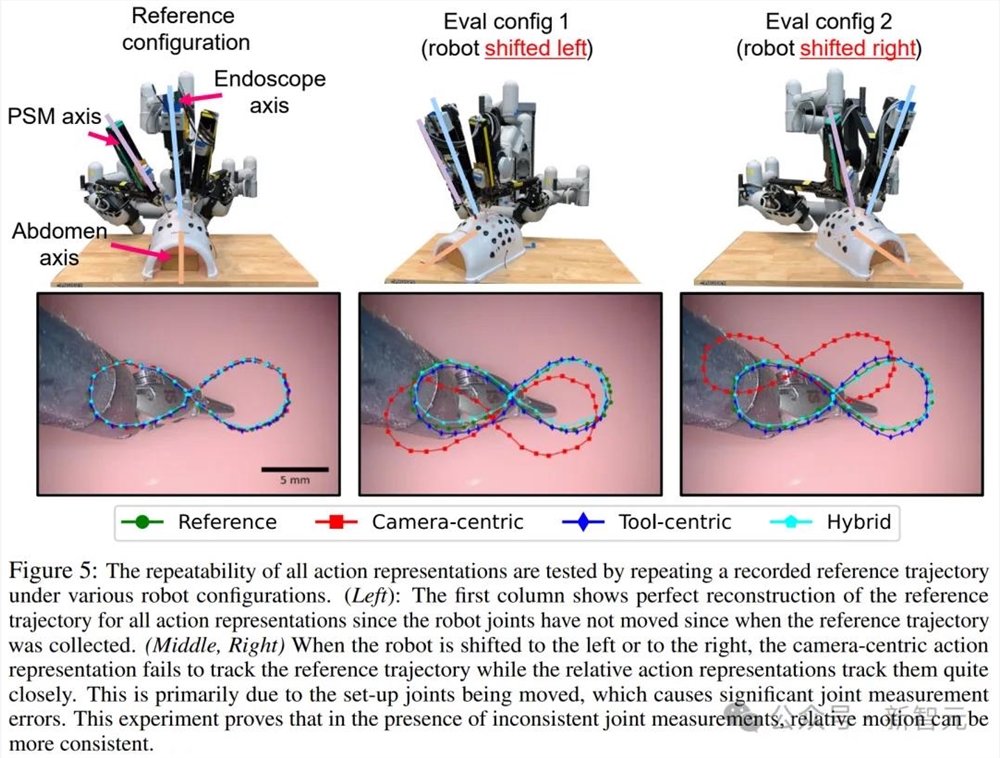
首先需要评估的是,达芬奇的相对运动是否比其绝对前向运动学更加一致。
评估方法是在不同的机器人配置下,使用绝对与相对运动公式重复记录参考轨迹。
具体来说,机器人需要在模拟人体腹部的圆顶,使用相同的孔,将手臂和内窥镜大致放置在相似的位置。
这项任务不简单,因为孔比内窥镜和工具轴的尺寸大得多,而且必须通过移动安装接头,将工具手动放置到孔中。
总体而言,实验表明,在存在测量误差的情况下,相对运动的一致性更高。因此,将策略动作建模为相对运动是更好的选择。
在这项配置中,共收集了224次组织提起实验、250次针的拾取和移交实验,以及500次打结实验
图5展示了在各种机器人配置下重复录制的参考轨迹,以此来测试所有动作表示的可重复性。
左图显示了所有动作表示法的参考轨迹的完美重构,因为自参考轨迹采集以来,机器人关节没有移动过。
而当机器人向左或向右移动时(中、右图),以摄像头为中心的动作表示法无法跟踪参考轨迹,而相对动作表示法则能很好地跟踪参考轨迹。
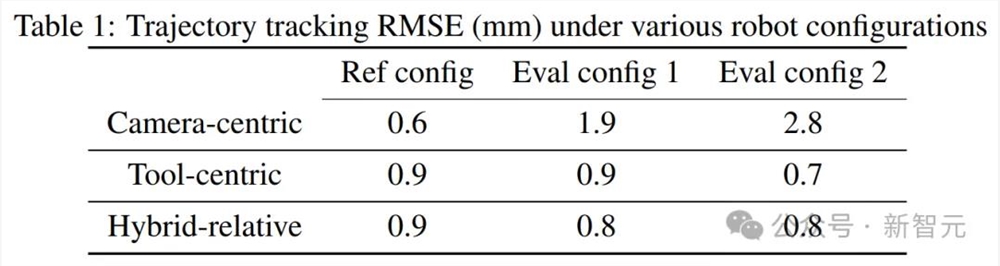
各种机器人配置下的轨迹跟踪
除此之外,团队还评估了使用各种动作表示法训练的模型的任务成功率。
结果表明,使用相对动作表述(以工具为中心的动作表述和混合相对动作表述)训练出来的策略表现良好,而使用绝对正向运动学训练出来的策略则失败了。
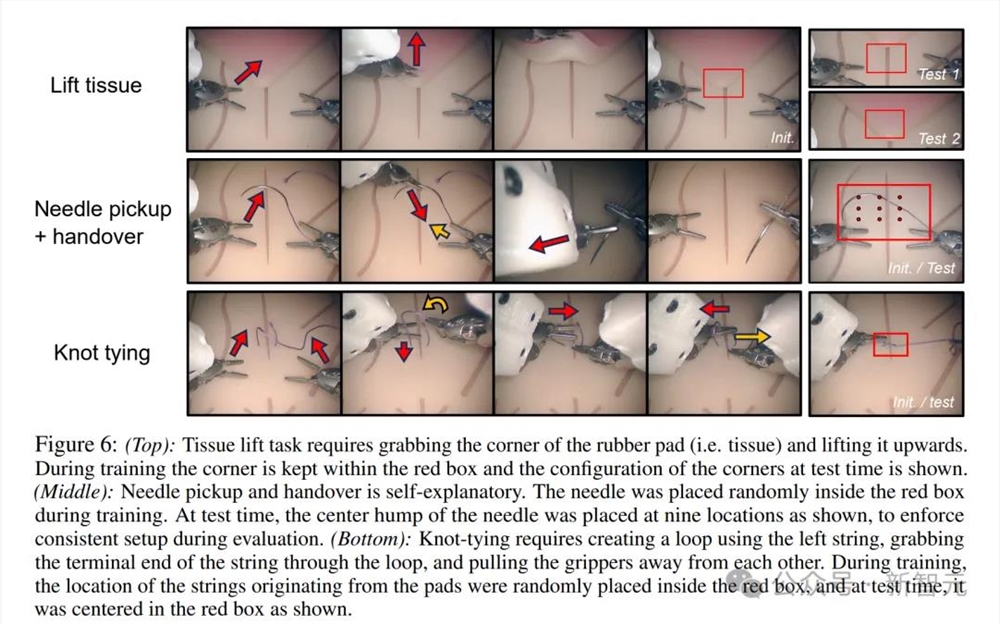
而在下图中,最上面一行,就是组织提起任务中,机器人需要抓住橡胶垫(组织)的一角,将其向上提起。
在训练期间,组织的一角保持着红色框内,显示测试时角的配置。
中间一行,是针的拾取和移交。
在训练过程中,针被随机放在了红色盒子内。测试时,针的中心隆起被放置在如图所示的9个位置,以在评估期间强制执行一致的设置。
下面一行,机器人在打结的过程中,需要使用左侧的绳子形成一个环,通过环来抓住绳子的末端,然后将夹具拉离彼此。
在训练期间,来自垫子的绳子位置随机放在红色方框内,而测试时,绳子被放在红色方框中央。
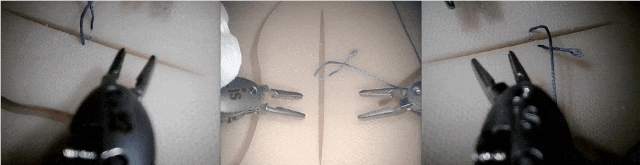
下面的视频显示了使用手臂的绝对前向运动学(以摄像头为中心的动作)训练策略的结果。
由于达芬奇手臂的前向运动学存在误差,在训练和推理之间会发生显著变化,因此这些策略无法完成任务。
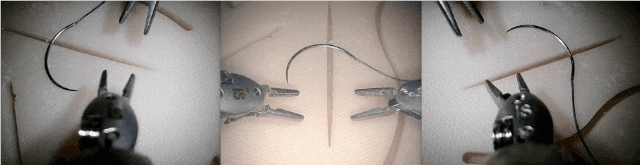
而且,研究人员还观察到,在学习外科手术操作任务时,腕部摄像头能带来显著的性能提升。
显然,能够自主学习的手术机器人,有望在未来进一步扩展外科医生的能力。
参考资料:
https://surgical-robot-transformer.github.io/