声明:本文来自于微信公众号新智元,作者:新智元,授权Soraor转载发布。
9次迭代后,模型开始出现诡异乱码,直接原地崩溃!就在今天,牛津、剑桥等机构的一篇论文登上了Nature封面,称合成数据就像近亲繁殖,效果无异于投毒。有无破解之法?那就是——更多使用人类数据!
用AI生成的数据训练AI,模型会崩溃?
牛津、剑桥、帝国理工、多伦多大学等机构的这篇论文,今天登上了Naure封面。
如今,LLM已经强势入侵了人类的互联网,极大地改变了在线文本和图像的生态系统。
如果网络上的大部分文本都是AI生成的,我们用网络数据训练出的GPT-n,会发生什么?

论文地址:https://www.nature.com/articles/s41586-024-07566-y
研究者发现,如果在训练中不加区别地使用AI产生的内容,模型就会出现不可逆转的缺陷——原始内容分布的尾部(低概率事件)会消失!
这种效应,被称为「模型崩溃」。
换句话说,合成数据就像是近亲繁殖,会产生质量低劣的后代。

模型崩溃在LLM、变分自编码器VAEs和高斯混合模型GMM中,都可能会发生。
有网友认为,是时候敲响警钟了!
「如果大模型真的在AI生内容的重压下崩溃,这对它们的可信度来说是一个末日场景。如果它们吃的是机器人的反刍的内容,我们真的能相信LLM的输出吗」?

真实数据,价值连城
我们都知道,如今全球已陷入高质量数据荒。
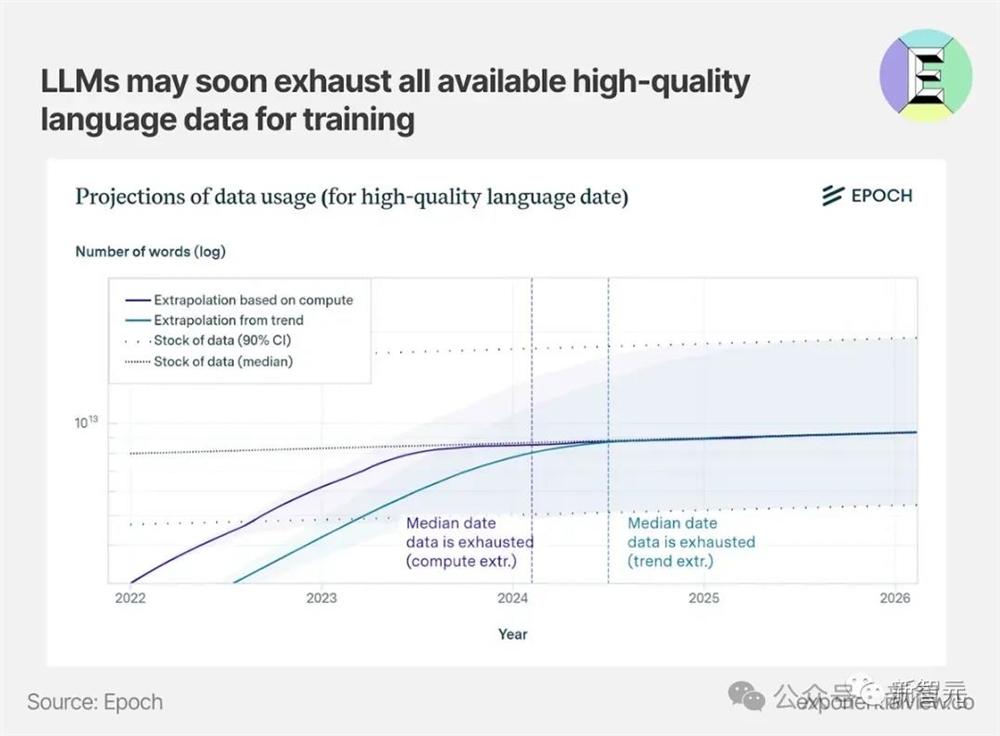
EpochAI预测,全球在今年就会陷入高质量数据荒
当前的大模型(包括GPT-3)还是主要基于人类生成的文本进行训练的,但是未来可就不一定了!
Meta研究员Thomas Scialom表示,Llama3在后训练阶段没有使用任何人类编写的答案,全是Llama2合成的数据
如果未来,大多数模型的训练数据也是从网上抓取的,那它们不可避免地会用上前辈模型生成的数据。
如果当某个版本的GPT生成的大部分文本,成为了后续模型的训练数据集,随着版本号的增加,GPT-{n}会发生什么变化?
LLM迭代至第9代,完全胡言乱语
简单讲,LLM生成的数据最终污染了下一代模型的训练集,就会出现「模型崩溃」(model collapse)的现象。
由于在被污染的数据上进行训练,LLM随后会错误地感知现实。
这样一来,会导致多代AI生成模型的退化。
也就是那句经典名言——垃圾进,垃圾出。

合成数据,无异于给数据集「投毒」。
研究中,作者们使用维基百科文章先训练了模型OPT-125m,并在前一代模型生成的文本上,训练了多代模型。
模型们被要求续写一段来自wiki的关于「萨默塞特(Somerset)一级登录建筑」条目的文本。

输入的提示如下所示,这是关于设计14世纪教堂塔楼主题的文本:

输入:据Poyntz Wright所说,一些教堂塔楼在1360年之前就开始建造了,通常是由一位大师石匠和一小队流动石匠完成,辅以当地教区的工人。但其他作者不同意这种观点,他们认为主要是由著名建筑师根据早期的垂直风格设计了这些教区教堂的塔楼。
在第0代模型中,输入同样的提示,得到的输出是:
可以看到,Gen0的续写已经开始有点前言不搭后语了,而且还出现了诡异的符号「@-@」。
奇怪的事实错误是,圣约翰大教堂位于纽约,不在伦敦。

第0代:复兴建筑的典型例子包括伦敦的圣约翰大教堂。最早的垂直复兴建筑实例可以在18@-@世纪的根西岛圣母教堂中找到,该教堂实际建于19世纪晚期。垂直教堂有两种类型:那些。
在Gen1中,虽没有奇怪符号的输出,但同样出现了事实错误——
圣彼得大教堂(St. Peter's Basilica)真正位于梵蒂冈,而不是什么罗马、布宜诺斯艾利斯。
而且建造于公元1506和1626年之间,由教皇朱利奥二世开始建造,直至教皇奥本八世。

第1代:像罗马的圣彼得大教堂或布宜诺斯艾利斯的圣彼得大教堂这样的建筑。虽然没有证据表明这些建筑是在教皇英诺森三世统治期间建造的,但它们有可能是在他的继任者教皇英诺森统治期间建造的。
接下来,到了第五代模型,输出的结果完全是胡言乱语了。
以ism起句,讲了一大堆语种,根本不是续写的相关素材。

第5代:ism,已被翻译成100多种语言,包括英语、法语、德语、意大利语、西班牙语、葡萄牙语、荷兰语、瑞典语、挪威语、波兰语、匈牙利语、斯洛伐克语、立陶宛语、爱沙尼亚语、芬兰语、罗马尼亚语、保加利亚语、土耳其语、克罗地亚语、塞尔维亚语、乌克兰语、俄语、哈萨克语、吉尔吉斯语。
再到第9代,奇怪的@-@符号又出现了,而且还输出了更加无关的内容——tailed jackrabbits。

第9代:建筑。除了拥有世界上最大数量的黑@-@尾兔、白@-@尾兔、蓝@-@尾兔、红@-@尾兔、黄@-。
以下是所有迭代模型,完整输出的过程。每一代新的模型都是在前一代生成的数据上进行训练的。

看得出,模型在每一代次迭代中退化。研究人员发现,所有递归训练后的模型,皆会输出重复的短语。
另一个案例是,今天杜克大学助理教授Emily Wenger,发表在Nature上一篇社论文章中指出:
AI基于自身数据训练,生成的图像扭曲了狗的品种。

数据集中,不仅有金毛、柯基,还有法国斗牛犬、小体巴塞特雪橇犬等。
基于真实数据训练后的模型,输出的图像中,常见品种如金毛寻回犬占大多数,而不太常见的品种斑点狗会消失。
然后,基于AI生成的数据训练模型,生成的品种全是金毛了。
最终,经过多次迭代,金毛的图像就完全出现混乱,脸不是脸鼻子不是鼻子,LLM就此完全崩溃了。
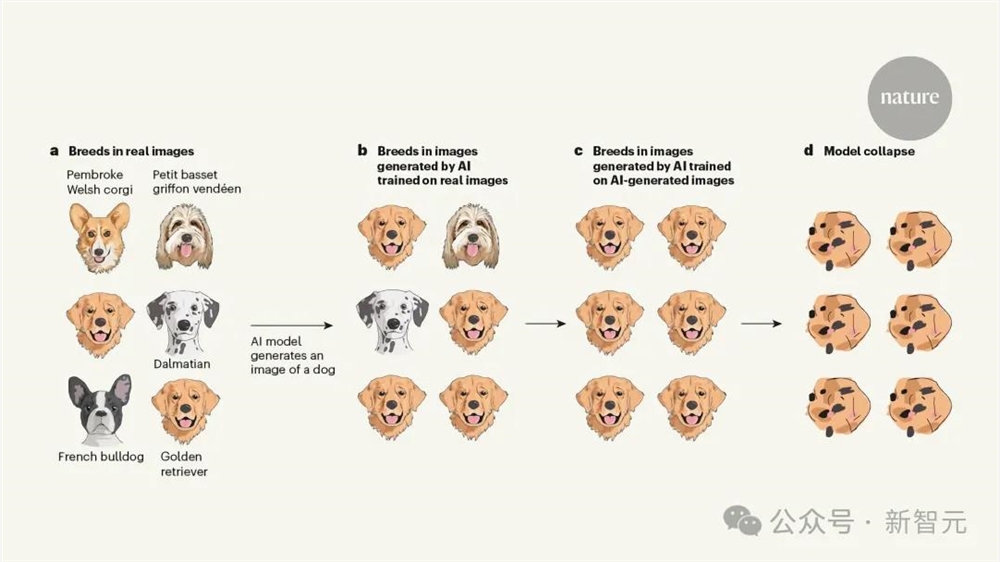
此外,2023年来自斯坦福和UC伯克利的一项研究中,作者同样发现了,LLM在少量自己生成数据内容重新训练时,就会输出高度扭曲的图像。

论文地址:https://arxiv.org/pdf/2311.12202
他们还在实验中展示了,一旦数据集受到污染,即便LLM仅在真实图像上重新训练,模型崩溃现象无法逆转。
作者警示道,为了模型不再被自己「降级」,AI需要能够区分真实和虚假内容。

这一观点,与杜克Wenger不谋而合。
她认为,缓减LLM崩溃并不简单,不过领先科技公司已经部署了嵌入「水印」的技术,进而可以把标记AI生成内容,从数据集中剔除。
此外,模型崩溃的另一个关键寓意是,那些早已构建的AI模型,有着先发优势。
因为,从AI时代互联网获取训练数据的公司,可能拥有更能代表真实世界的模型。
什么是模型崩溃?
最新研究中,作者表示,模型崩溃包含了两种特殊的情况:早期模型崩溃、晚期模型崩溃。
在早期模型崩溃中,模型开始丢失关于数据分布尾部的信息;在晚期模型崩溃中,模型收敛到一个与原始分布几乎没有相似性的分布,通常方差显著降低。
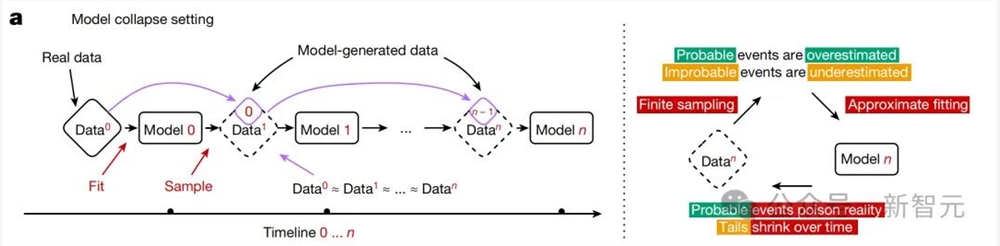
这一过程的发生,是由于三种特定误差源,在多代模型中逐渐累积,最终导致模型偏离原始模型:
- 统计近似误差
这是主要的误差类型,由于样本数量有限而产生,并且在样本数量趋向无限时会消失。这是因为在每一步重采样过程中,信息丢失的概率总是存在。
- 函数表达误差
这是次要误差类型,由于函数近似器(function approximator)的表达能力有限而产生。
特别是,神经网络只有在其规模无限大时,才能成为通用近似器。
因此,神经网络可能会在原始分布的支撑集(support)之外,引入「非零概率」,或在原始分布的支撑集内引入「零概率」。
一个简单的例子是,如果我们用单个高斯分布,来拟合两个高斯分布的混合。即使有完美的数据分布信息(即无限数量的样本),模型产生误差也是不可避免的。
然而,在没有其他两种类型误差的情况下,这种误差只会在第一代发生。
- 函数近似误差
这也是次要的误差类型,主要由于学习过程的限制而产生,例如随机梯度下降的结构偏差或目标函数选择的影响。
这种误差可以看作,即便在理想条件下,即拥有无限数据且完美表达能力,仍在每一代模型中产生。
综上所述,每种误差都可能会导致模型崩溃变得愈加严重,或得到一些改善。
更强的近似能力甚至可能是一把「双刃剑」。
因为更好的表达能力可能抵消统计噪声,从而更好地逼近真实分布,但同样也可能放大噪声。
更常见的情况下,我们会得到一种级联效应(cascading effect),其中个别的不准确性会结合起来,导致整体误差的增长。
例如,过拟合密度模型会导致模型错误地外推,并将高密度区域分配给训练集中未覆盖的低密度区域。
这些错误分配的区域,随后会被频繁采样。
值得注意的是,除上述内容之外,还存在其他类型的误差。比如,在实际操作中,计算机精度是有限的。
接下来,研究人员将通过「数学直觉」来解释上述误差是如何产生的,不同误差来源如何复合(compound),以及我们如何量化平均模型偏差。
理论直觉
在所有基于前几代生成数据进行递归训练的生成模型,这种现象都是普遍存在的。
所以,到底是什么原因,导致了模型崩溃?
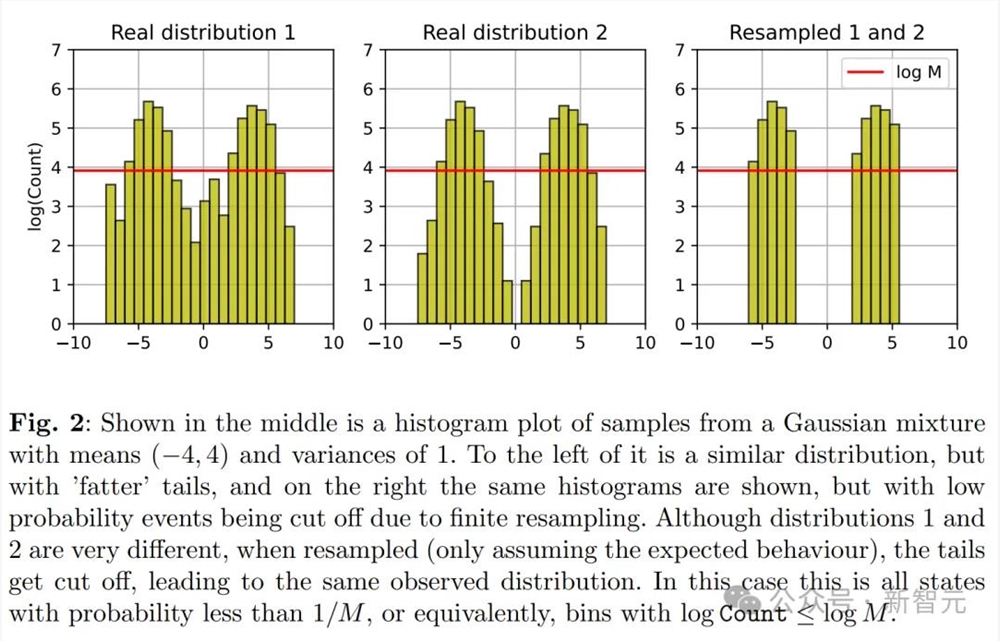
研究者提供了几种理论解释。
通过研究两个数学模型,研究者量化了前一部分讨论的误差来源。
这两个模型分别是一个在没有函数表达能力和近似误差情况下的离散分布模型,以及一个描绘联合函数表达能力和统计误差的多维高斯近似模型。
它们既足够简单,可以提供感兴趣量的解析表达式,同时也能描绘模型崩溃的现象——
考虑的总体随机过程,作者称之为「代际数据学习」。
第i代的数据集Di由具有分布pi的独立同分布随机变量
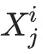
组成。
其中,数据集的大小j∈{1,…, M_i}。
从第i代到第i+1代,我们需要估计样本在新数据集D_i中的分布,近似为
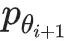
。
这一步称之为函数近似,
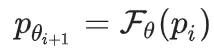
。
然后通过从
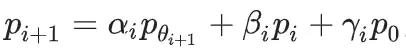
中采样,生成数据集
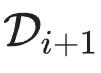
。
其中,非负参数αi, βi, γ_i的和为1,即它们表示来自不同代的数据的比例。
它们对应的混合数据,分别来自原始分布(γi)、上一代使用的数据(βi)和新模型生成的数据(α_i)。
这一步,称为采样步骤。
对于即将讨论的数学模型,我们考虑αi=γi=0,即仅使用单步的数据,而数值实验则在更现实的参数选择上进行。
在本小节中,我们讨论一种没有函数近似和表达误差的离散概率分布,即
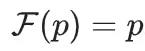
。
在这种情况下,模型崩溃的原因仅仅是采样步骤中的统计误差。
首先,由于低概率事件被采样到的概率很低,它们的尾部(低概率事件)会逐渐消失,随着时间的推移,分布的支持范围也会缩小。
假设样本量为M,如果我们考虑一个概率为q≤1/M的状态i,那么来自这些事件的i值样本的期望数量将小于1。
也就是说,我们会失去关于这些事件的信息。
如果更一般地考虑一个概率为q的状态i,使用标准条件概率,我们可以证明失去信息的概率(即在某些代中没有采样到数据)等于1−q。
这也就意味着,分布最终会收敛到某个状态处的δ函数,最终落在某个状态的概率等于从原始分布中采样该状态的概率。
将
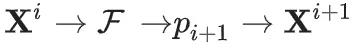
这个过程看作一个马尔可夫链,我们就可以直接证明上述结论,因为X^(i+1)仅依赖于X^i。
此外,如果所有
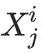
的值都相同,那么在下一代,近似分布将完全是一个δ函数。因此所有
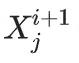
的值也将相同。
这就意味着,马尔可夫链至少包含一个吸收态,因此它会以概率1收敛到其中一个吸收态。
对于这个链,唯一的吸收态是那些对应于δ函数的状态。
因此,随着我们跟踪的模型逐渐崩溃,我们必然会陷入一个常数状态;当这条链被完全吸收时,原始分布的所有信息就都丧失了。
在一般情况下,这个论点也是成立的,因为浮点表征是离散的,因此使得模型参数的马尔可夫链也是离散的。
因此,只要模型参数化允许使用δ函数,我们一定会到达这个结论,因为由于采样误差的原因,唯一可能的吸收态就是δ函数。
基于上述讨论,我们可以看到,无论是早期模型崩溃(仅低概率事件被切断)还是后期模型崩溃(过程开始收敛到单一模式)的现象,只要是在具有完美函数近似的离散分布下,都必然会出现。
在讨论了离散分布之后,我们就可以提出一个更通用的结果,它可以在高斯近似的背景下得到证明。
在这种情况下,每一代的数据都是通过上一代的均值和方差的无偏估计来近似的。
假设原始数据是从分布D_0(不一定是高斯分布)中采样的,且样本方差不为零。假设X^n是递归地使用上一代的无偏样本均值和方差估计来拟合的,其中
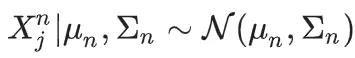
且样本量是固定的。
此时就可以得到

。
其中,W_2表示第n代的真实分布和其近似之间的Wasserstein-2距离。
换句话说,这意味着不仅第n代的近似值会任意远地偏离原始分布,而且随着代数的增加,它也会以概率1收敛到零方差,从而发生崩溃。
这个定理展示了后期模型崩溃的效果,即过程开始收敛到零方差。这个过程,与离散情况非常相似。
语言模型中的模型崩溃
模型崩溃在各种机器学习模型中都是普遍现象,然而像变分自编码器(VAE)和高斯混合模型(GMM)这样的小模型通常是从头开始训练的,而LLM则有所不同。

从头训练的成本非常高,因此通常使用预训练模型(如BERT、RoBERTa或GPT-2)进行初始化,然后再对预训练模型进行微调以适应各种下游任务。
那么,当LLM使用其他模型生成的数据进行微调会发生什么呢?
实验评估了训练大语言模型最常见的微调设置,其中每个训练周期(epoch)都从一个预训练模型开始,并使用最新数据。
这里的数据来自另一个已经微调过的预训练模型。
由于训练范围限制在生成接近原始预训练模型的模型,由于这些模型生成的数据点通常只会产生非常小的梯度,因此实验的预期是模型在微调后只会发生适度的变化。
实验微调了Meta通过Hugging Face提供的OPT-125m因果语言模型,在wikitext2数据集上对模型进行微调。
为了生成训练模型所需的数据,实验使用五向集束搜索(beam search)。
将训练序列限制为64个token,然后对于训练集中的每个token序列,让模型预测接下来的64个token。
用上面的方法调整所有原始训练数据集,并生成一个大小相同的人工数据集。
由于范围涉及所有原始数据集并预测了所有块(Block),如果模型的误差为0,它将生成原始的wikitext2数据集。
每一代的训练都从原始训练数据的生成开始,每个实验运行五次,结果显示为五次独立运行,使用不同的随机种子。
用wikitext2数据微调的原始模型,平均困惑度(perplexity)从零样本基线的115下降到34,说明它成功地学习了任务。
最后,为了尽可能接近现实情况,实验使用了在原始任务上表现最好的模型,使用原始wikitext2验证集进行评估,作为后续几代的基础模型。
这意味着,实际上观察到的模型崩溃可能更加明显。
实验还考虑了考虑两种不同的设置:
-5个epoch,不保留原始训练数据。
在这种情况下,模型在原始数据集上训练五个周期,但在后续的训练中不再使用原始数据。
整体的原始任务表现如图所示。
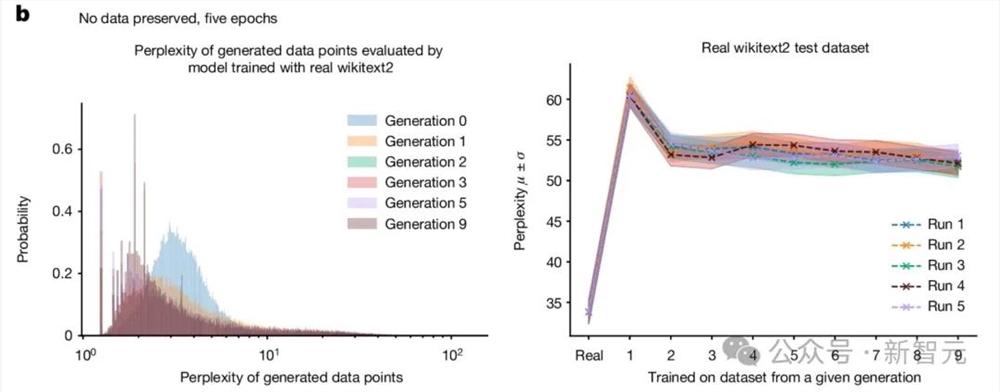
实验发现,使用生成的数据进行训练虽然能适应基本任务,但性能有所下降,困惑度从20增加到28。
-10个epoch,保留10%的原始训练数据。
在这种情况下,模型在原始数据集上训练十个周期,并且每次新的训练时,随机保留10%的原始数据点。
整体的原始任务表现如图所示。
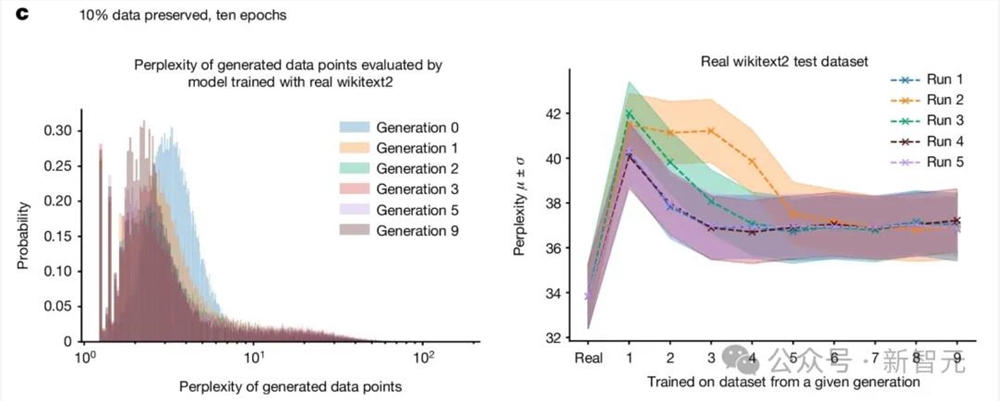
实验发现,保留部分原始数据可以更好地进行模型微调,并且仅导致性能的轻微下降。
虽然两种训练方式都导致了模型性能下降,但实验发现使用生成数据进行学习是可行的,模型也能成功地学习一些基础任务。
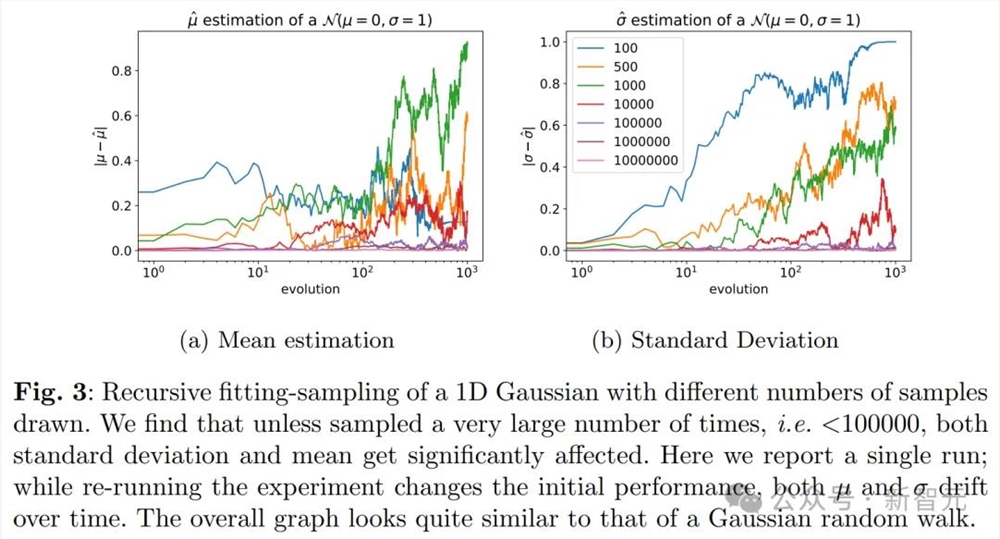
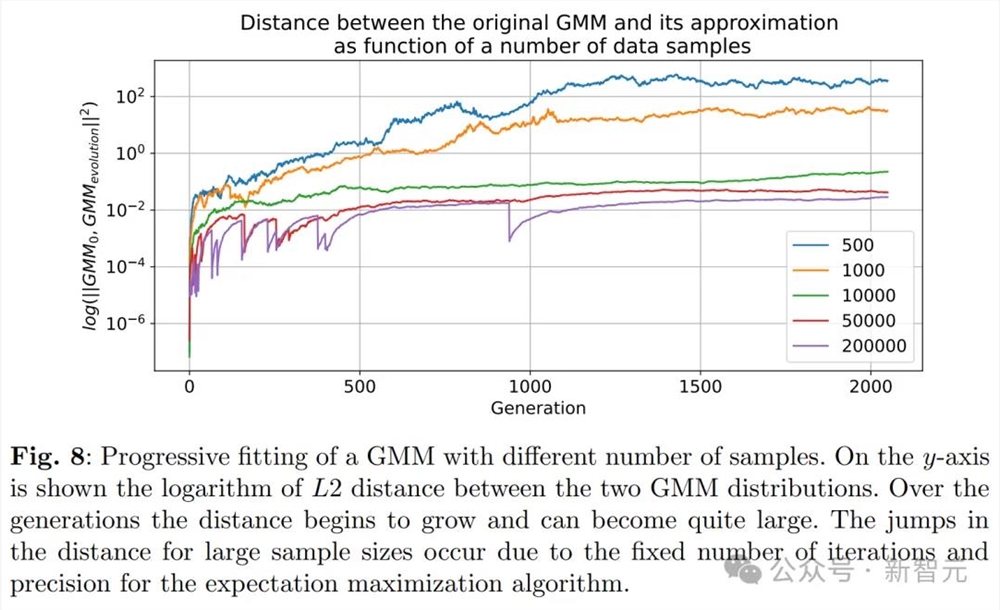
特别是,从图下及其3D版本中可以看到,模型崩溃现象确实发生了,因为低困惑度样本的密度随着训练代次的增加而开始累积。
这意味着,在多个训练代次中,采样数据可能会逐渐趋向于一个δ函数。
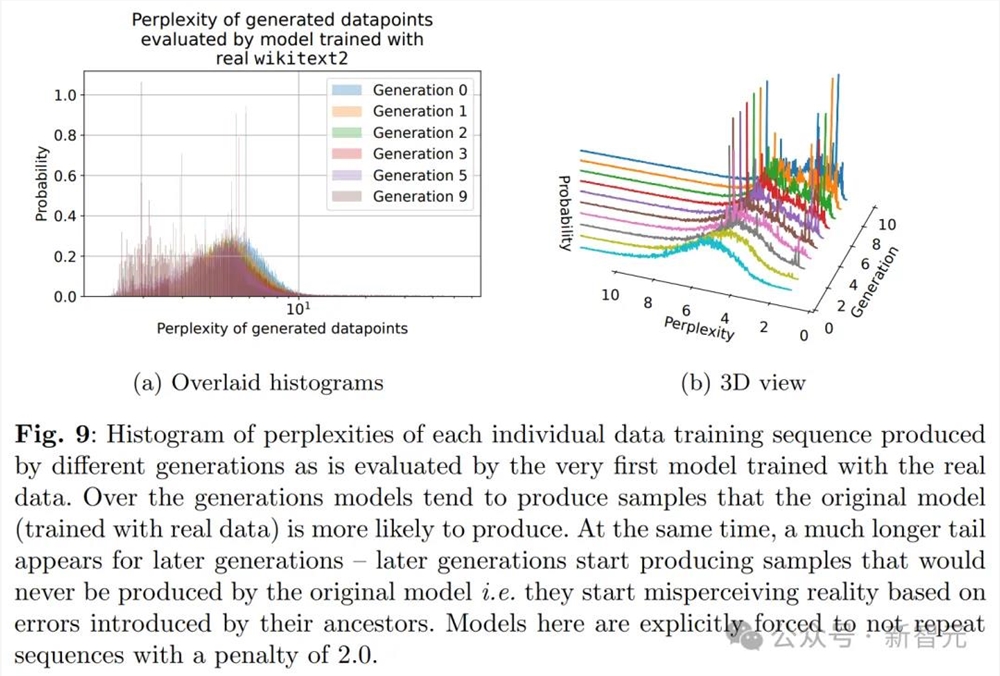
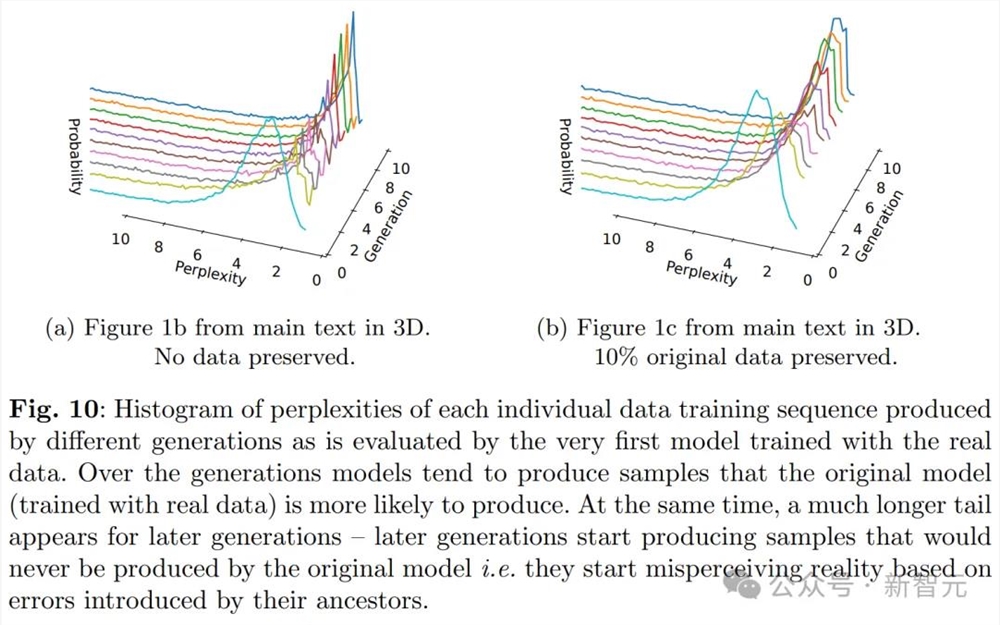
到这里,结论就和「理论直觉」中的一般直觉一致了。
可以看到,生成的数据有更长的尾部,这就表明某些数据是原始模型永远不会生成的。而这些错误,就是来自代际数据学习的积累。
这也给我们敲响了警钟——
如果没有大规模采用AI泛滥之前从网上抓取的数据,或者直接使用人类生成的大规模数据,训练新版本的LLM,恐怕会变得越来越困难!
有什么办法吗?
研究团队认为,AI生成数据并非完全不可取,但一定要对数据进行严格过滤。
比如,在每一代模型的训练数据中,保持10%或20%的原始数据;使用多样化数据,如人类产生的数据;或者研究更鲁棒的训练算法。
没想到吧,人类创造的数据,居然有一天会如此价值连城。
参考资料:
https://www.nature.com/articles/d41586-024-02420-7
https://www.nature.com/articles/s41586-024-07566-y