声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:机器之心,授权Soraor转载发布。
GPT-4o mini主打一个字「快」。
昨晚,OpenAI突然上线新模型 GPT-4o mini, 声称要全面取代 GPT-3.5Turbo。
在性能方面,GPT-4o mini 在 MMLU 上的得分为82%,在 LMSYS 排行榜的聊天方面分数优于 GPT-4。
在价格方面,GPT-4o mini 比之前的 SOTA 模型便宜一个数量级,商用价格是每百万输入 token15美分,每百万输出 token60美分,比 GPT-3.5Turbo 便宜60% 以上。

OpenAI表示,ChatGPT 的免费版、Plus 版和 Team 用户将能够从周四开始访问 GPT-4o mini(其知识截至2023年10月),以代替 GPT-3.5Turbo,企业用户可以从下周开始访问。
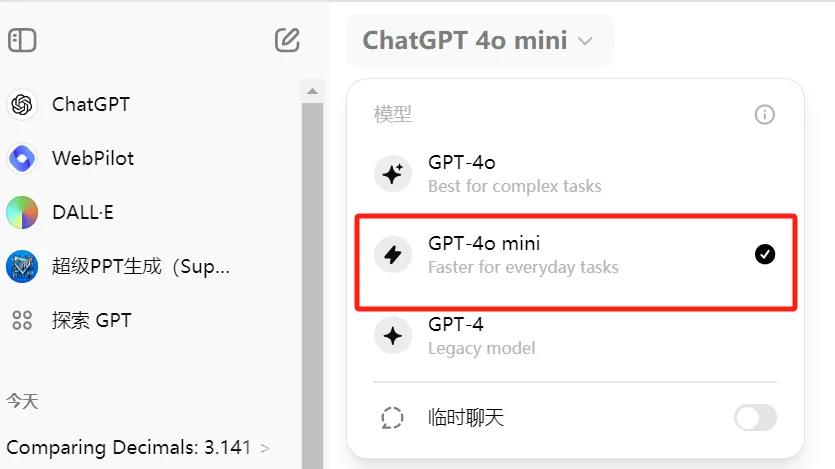
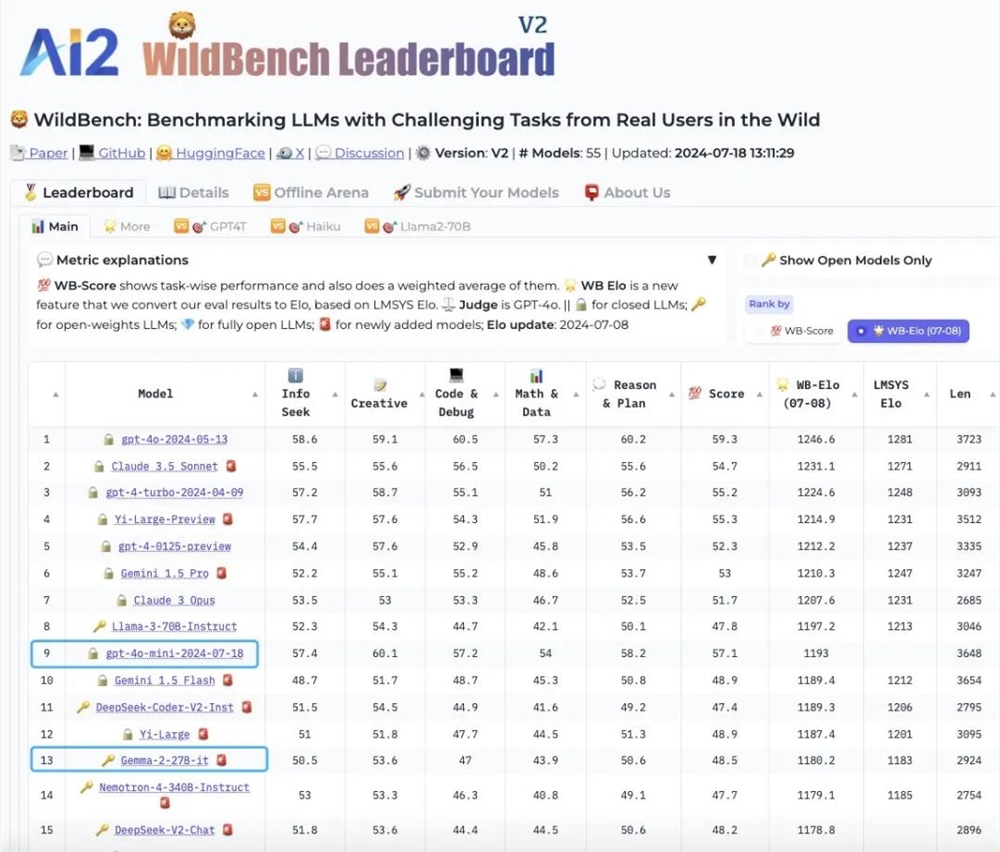
目前,GPT-4o mini 在 WildBench 测试上排名第九,优于谷歌的 Gemini-flash 以及 Anthropic 的 Claude3Haiku。
在今天的凌晨的文章中,我们已经介绍了 GPT-4o mini 的一些基本情况(参见《GPT-4o Mini 深夜突发:即刻免费上线,API 降价60%》)。在这篇文章中,我们将补充介绍模型的实际使用体验以及这份工作背后的研究者。
GPT-4o mini 一手评测
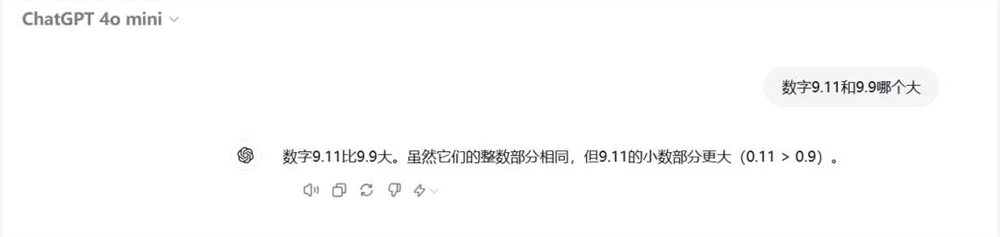
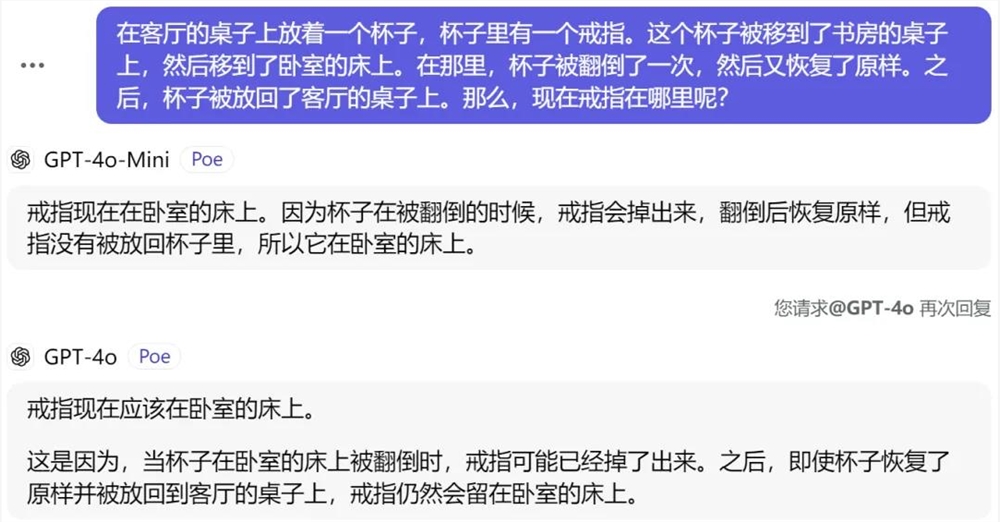
在 GPT-4o mini 开放测试的第一时间,我们问了它一个最近比较热门的话题,9.11和9.9哪个大,很遗憾,GPT-4o mini 依然没有答对,还一本正经地回答0.11>0.9。
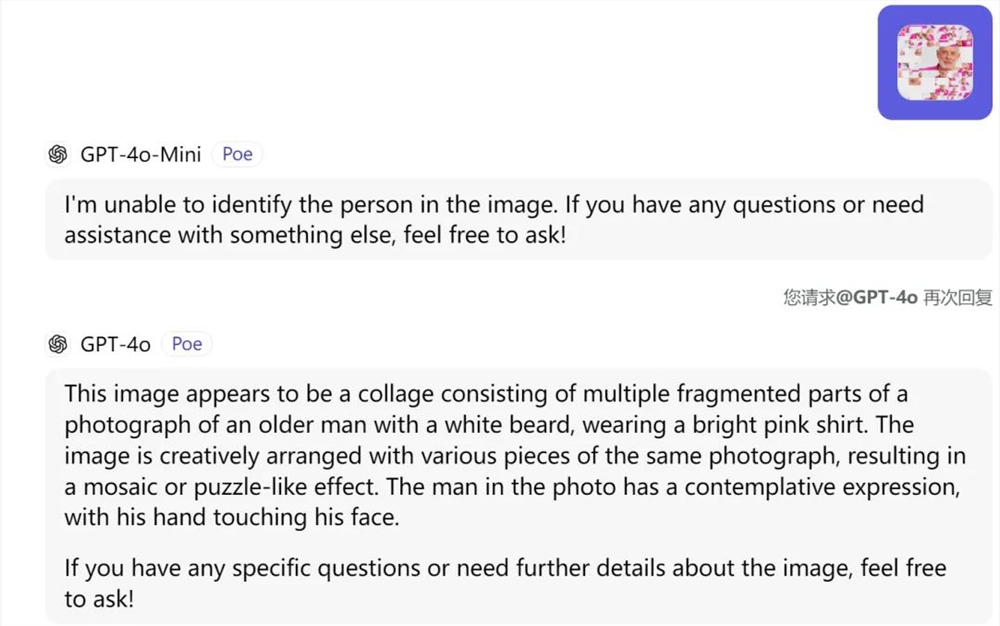
接着我们在 Poe(Quora 开发的应用程序,已经集成了 GPT-4o mini)中输入人物传记电影《Eno》的设计封面,让两个模型解读,结果 mini 翻车了。GPT-4o mini 直接表示「自己认不出照片上的人。」
与之相对的,GPT-4o 的回答就比较准确。「这张图片看起来像是一幅拼贴画,由一张照片的多个碎片组成,照片中是一位留着白胡子、身穿亮粉色衬衫的老人。这幅图由同一张照片的不同部分创造性地排列而成,产生了马赛克或拼图般的效果。照片中的男子表情若有所思,手抚摸着脸。」
接着我们又测试了另一个问题:在客厅的桌子上放着一个杯子,杯子里有一个戒指。这个杯子被移到了书房的桌子上,然后移到了卧室的床上。在那里,杯子被翻倒了一次,然后又恢复了原样。之后,杯子被放回了客厅的桌子上。那么,现在戒指在哪里呢?如果我们分开问,答案不一样,GPT-4o 似乎更聪明点。


但是,如果我们一起发问,它们的答案又会变得雷同:
GPT-4o mini 回答数学题的表现如何呢?机器之心用丘成桐少年班2024年选拔试题测试了一下它解决数学问题的能力。

虽然 GPT-4o mini 对问题的解读都比较清晰,但在分析过程中出现「胡言乱语」的逻辑错误,像极了上数学课根本听不懂但硬答的学生。
不过也不必着急,毕竟 GPT-4o 的回答更不理想,它甚至没有看懂数字表示的是正方形的边长。

在文字的总结能力上,GPT-4o mini 与 GPT-4o 的能力不相上下。都能将重点信息进行抓取,但 GPT-4o 的回答更显条理。
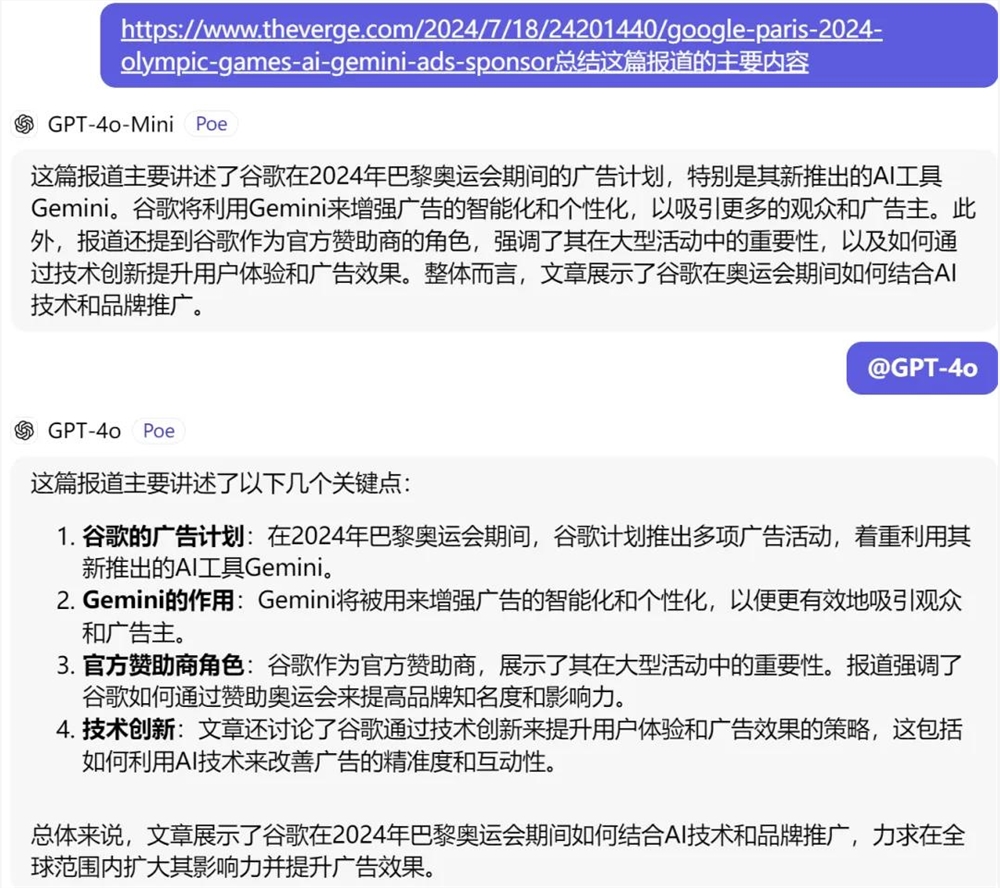
不过主打「Faster for everyday tasks」的 GPT-4o mini,响应速度确实对得起「Faster」之称。和它对话,几乎无需等待,输出速度也是快得离谱。
日本网友用 GPT-4o mini 搭建了一款 AI 聊天机器人,响应速度依然快得惊人。
还有网友将 GPT-4o 和 GPT-4o mini 输出速度进行了对比,GPT-4o mini 明显更快:
从大家体验效果上来看,GPT-4o mini 主打一个字「快」,但实际使用体验可能还是差了一些。
作者介绍
随着 GPT-4o mini 的发布,很多人表示 OpenAI 又一次给大家带来了一点点震撼。其实,这背后是一群年轻的学者,还有多位华人的身影。
GPT-4o mini 项目负责人是 Mianna Chen。
Mianna Chen 于去年12月加入 OpenAI,此前在谷歌 DeepMind 任产品主管。
她在普林斯顿大学获得学士学位,2020年获得宾夕法尼亚大学沃顿商学院 MBA 学位。
该项目的其他领导者还包括 Jacob Menick、Kevin Lu、Shengjia Zhao、Eric Wallace、Hongyu Ren、Haitang Hu、Nick Stathas、Felipe Petroski Such。
Kevin Lu 是 OpenAI 的一名研究员,2021年毕业于加州大学伯克利分校。曾与强化学习大牛 Pieter Abbeel 等人一起研究强化学习和序列建模。
Shengjia Zhao 于2022年6月加入,现在是 OpenAI 的一名研究科学家,主攻 ChatGPT。他的主要研究方向是大语言模型的训练和校准。此前,他本科毕业于清华大学,博士毕业于斯坦福大学。
Hongyu Ren 在去年7月加入,现在是 OpenAI 的一名研究科学家,他还是 GPT-4o 的核心贡献者,并致力于 GPT-Next 的研究。Hongyu Ren 本科毕业于北京大学、博士毕业于斯坦福大学。此前,他在苹果、谷歌、英伟达、微软等工作过。
Haitang Hu 于去年9月加入 OpenAI,曾任职于谷歌。他本科毕业于同济大学、硕士毕业于霍普金斯约翰大学。
Karpathy:模型变小是自然趋势
这次,OpenAI 还是发了 GPT-4的衍生模型。所以很多人还是会问:GPT-5啥时候来?
这个问题目前没有官方信息。但从 OpenAI 等 AI 巨头纷纷发布小模型的动作来看,小模型正在成为一个新战场。
OpenAI 创始成员 Karpathy 对此表示,「LLM 模型大小竞争正在加剧…… 但方向是相反的」!
我敢打赌,我们会看到非常小的模型,它们思考得非常好,而且非常可靠。甚至 GPT-2参数的设置很可能会让大多数人认为 GPT-2很智能。
当前模型如此之大的原因在于我们在训练过程中表现得很浪费 —— 我们要求 LLM 记住互联网上的整个内容,令人惊讶的是,它们确实可以做到,例如背诵常用数字的 SHA 哈希值,或者回忆起非常深奥的事实。(实际上,LLM 非常擅长记忆,比人类好得多,有时只需要一次更新就可以长时间记住很多细节)。
但想象一下,如果你要接受闭卷考试,考卷要求你根据前几句话背诵互联网上的任意段落。这是当今模型的(预)训练目标。想要做的更好,面临着一个难点,在训练数据中,思考的展示与知识「交织」在一起的。
因此,模型必须先变大,然后才能变小,因为我们需要它们(自动化)的帮助来重构和塑造训练数据,使其成为理想的合成格式。
这是一个改进的阶梯 —— 一个模型帮助生成下一个模型的训练数据,直到我们得到「完美的训练集」。当你用 GPT-2对其进行训练时,按照今天的标准, 它会成为一个非常强大、智能的模型。也许它在 MMLU(大规模多任务语言理解) 方面会低一点,因为它不会完美地记住所有的细节。也许它偶尔需要查找一下,以确保信息的准确性。

按照 Karpathy 的说法,以后小模型会变得越来越多,越来越好用。这个领域的竞争会有多激烈?我们拭目以待。
参考链接:https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/