声明:本文来自于微信公众号 机器之心(ID:almosthuman2014),作者:吴昕,授权Soraor转载发布。
用十年时间成为全球在线服务数亿用户的财富管理平台后,摆在蚂蚁财富面前的是一段少有人走过的路:
这5亿活跃用户第一次动动手就能接触到各类普惠的理财产品,但真正理财行为成熟的仅占两成。而放眼中国7.2亿基金投资者里,每3600人才能分到1位传统理财顾问来服务。投多顾少,对很多普通投资者来说,往往处于专业服务的「无人区」。俗话说,「瞎子引瞎子,二人掉深渊」,用户侧对专业服务的需求呼唤技术的进步。
2020年,「 AI 理财助理」支小宝正式对外上线,蚂蚁财富希望能补足行业服务的空白。不久,蚂蚁财富又投入50个人年—— 一个操作系统的开发成本——再造支小宝 (1.0)。
谁曾想半年后,这位刚达专业水准的 AI 助理,又率先搭上大模型的快车,从检索式 AI(1.0)进化到生成式AI(2.0),让4300万普通投资者先一步拥有了自己的「私人理财专家」。
据蚂蚁财富保险智能服务部总经理陆鑫介绍,技术团队用最新的大模型技术去实现支小宝这样一个严谨产业应用时,做了三层工作:底层是面向严谨应用定制的凤凰大模型 Finix,中间层是模仿专家思考和工作流程的 agentUniverse (下文简称 aU )专业智能体框架,两者结合支撑了最上层支小宝有效的投顾服务。
一、空降热搜,AI 的话大家听懂了
两个月前,金价狂飙,连带新版支小宝空降热搜。

「能不能买?」「要不要买?」用户的咨询如潮水般涌来。一个月内,支小宝已发出上万次针对黄金的理性投资提醒。虽有些「爹味」,但支小宝却真的让很多盲目跟风的人冷静了一下。在热搜话题里,有人甚至调侃,「 AI 几句话,立省10万。」

热搜似乎只是一个缩影,实际上反映出大语言模型焕新理财助理后产生的巨大变化——提醒变得通俗易懂,让人听得进去。新版支小宝上线不久,用户已超四千万。
「黄金现在能买吗?」面对这个大家普遍关心的问题,支小宝很快给出直观全面的分析,提醒在高点保持观望,不急于马上增持。论据上,既综合了平台上几十家基金公司的共识和分歧、利空利好因素,也考虑了个人持仓。
同样的问题扔给通用大模型,TA 的回答更像隔靴搔痒,因为不会对我们的问题做任何假设,所以,说了很多,却又像什么都没说。

面对「小米现在怎么样」这样有些没头脑、模糊的查询,支小宝现在也能给出满意的答复。
支小宝底层引入严谨应用大模型 Finix 和专业智能体框架 aU 后,金融意图识别准确率从80% 提升到95%,用户的平均对话轮次增加了约40%。这无疑是质的提升,技术团队说到,面向严谨应用去定制大模型技术后,让支小宝不仅「更像一个人」还能「像一位专家」,能解决用户的真实疑惑。
余音未落,我们瞥见支小宝首页右上方显示,已有600多万人发起了提问。
二、「模仿专家」的关键:意图理解的飞跃
在「模仿专家、成为专家」的「职业规划」下,支小宝的技术发展也被分为两层:一层,让支小宝模仿专家去理解用户;第二层,让它不再被动等待问题,通过主动服务用户,成为专家。
「模仿专家」准确把握用户意图,这在投顾服务中尤其具有挑战性。
不同于搜索场景中明确详细的用户 query,理财对话中,用户的表达往往简单模糊,如「小米现在怎么样」、「现在黄金怎么样」,乃至错字或缩写,如「推荐一支军工基」。前大模型时代,AI 依靠关键词匹配或浅层语义分析,很容易判断失误,导致服务偏离用户真实需求。
支小宝1.0尝试过用上下文建模缓解这一问题,终究不过扬汤止沸。接入大语言模型后,基于大语言模型的多智能体( Agent )框架(「仿金融专家多智能体协同推理」)彻底颠覆了传统从 NLU 到生成的 Pileline 。
当你问「小米现在怎么样」,可以脑补这样一段画面,支小宝内部的多个 Agent 将各司其职:
一个用户服务 Agent 结合服务历史和用户画像,生成多个可能的意图假设,一个知识检索 Agent 为每个假设搜集背景知识和相关资讯,一个专业顾问 Agent 从市场和投顾专业视角补充观点和建议。
通过多专家的「协同推理」,这些来自不同 Agent 的信息联合起来确定最可能的用户意图,置信度最高的意图被认定为用户真实意图。最后,Agent 们协作生成最终回答。
这种基于大语言模型的多智能体框架,很容易让人联想到电影《头脑特工队》中人脑的运作。乐乐、忧忧、怒怒、厌厌和惊惊,各司其职,共同决定主人莱莉对外界刺激的反应。
新的解题模式与传统方式有两个明显不同。
新框架下,系统不是直接做出判断,而是沿着分歧的「枝条」、「分叉」,推理各种可能。「你可以理解成是一个地图,或者是一棵带有分支的树,然后沿着分支漫游。」技术团队打了个比方。
另外,得益于「协同推理」,即便个别 Agent 判断失误,其他 Agent 也可以通过协同推理予以纠正,大大提高了系统的鲁棒性。
「我们利用专家多智能体的专业知识和推理能力,吃掉了用户表达中不可避免的的模糊和存疑,最后,用更大规模的严谨应用大模型兜住了前面所有可能的误差。」技术团队解释道,将对话系统的基础从传统 Pipeline 升级到严谨应用大模型 Finix和专业智能体框架 aU 的组合后,金融意图识别准确率从80% 跃升至95%。
值得一提的是,在「仿金融专家多智能体协同推理」过程中,「用户画像」扮演着关键角色,这也是蚂蚁财富的传统强项。
大模型技术突破之前,他们就能通过分析用户在平台上的有效脱敏信息,包括理财行为、理财偏好等生成用户画像。1.0阶段就沉淀了多个专业的金融模型,能在平台噪音中提炼用户动机,预测用户行为。
现在,支小宝还有一个专门团队负责用户画像生产,借助大语言模型,用户画像的颗粒度和洞察深度又被提升到了新高度。
三、「成为专家的 AI 」: 不止被动解答还能主动搭话
蚂蚁财富很早就涉足到理财这个垂直领域的自然语义理解,投入很多精力去让机器人听懂问题,但结果发现大部分人在专业严谨应用中难以开口问出有效问题,所以支小宝在技术上做了一些尝试,跳出问答界面,成为专家,去主动服务,询问用户是否需要帮助
在支小宝问答首页,大量用户真实问题聚合成的「猜你想问」、「热门问题」很接地气,能免去小白和 i 人用户「难以开口」的尴尬。
「帮我挑只新能源基金」,接到命令后,支小宝迅速调用各类 API,筛选出10只备选基金,提示风险并表达对新能源行业的中性立场,也主动提供看好的消费行业基金供参考。
完成对话后,支小宝还会主动预判下一步需求,如「看看消费行业的基金」或「新能源行业的后市展望。」选择其中一个,对话会继续开展下去。
除了中心化的对话窗口,现在的支小宝还能深入到用户理财场景中,作为专家主动和用户交互,发起对话,引导 TA 进入下一个服务场景。
比如,用户查看基金持仓阵地、进入基金详情页时,支小宝会主动搭话,问询是否需要解读涨跌,或者调整持仓。如果主动引导「命中」用户需求,让他们觉得有用,用户很可能会继续提问,推动服务走向深入。
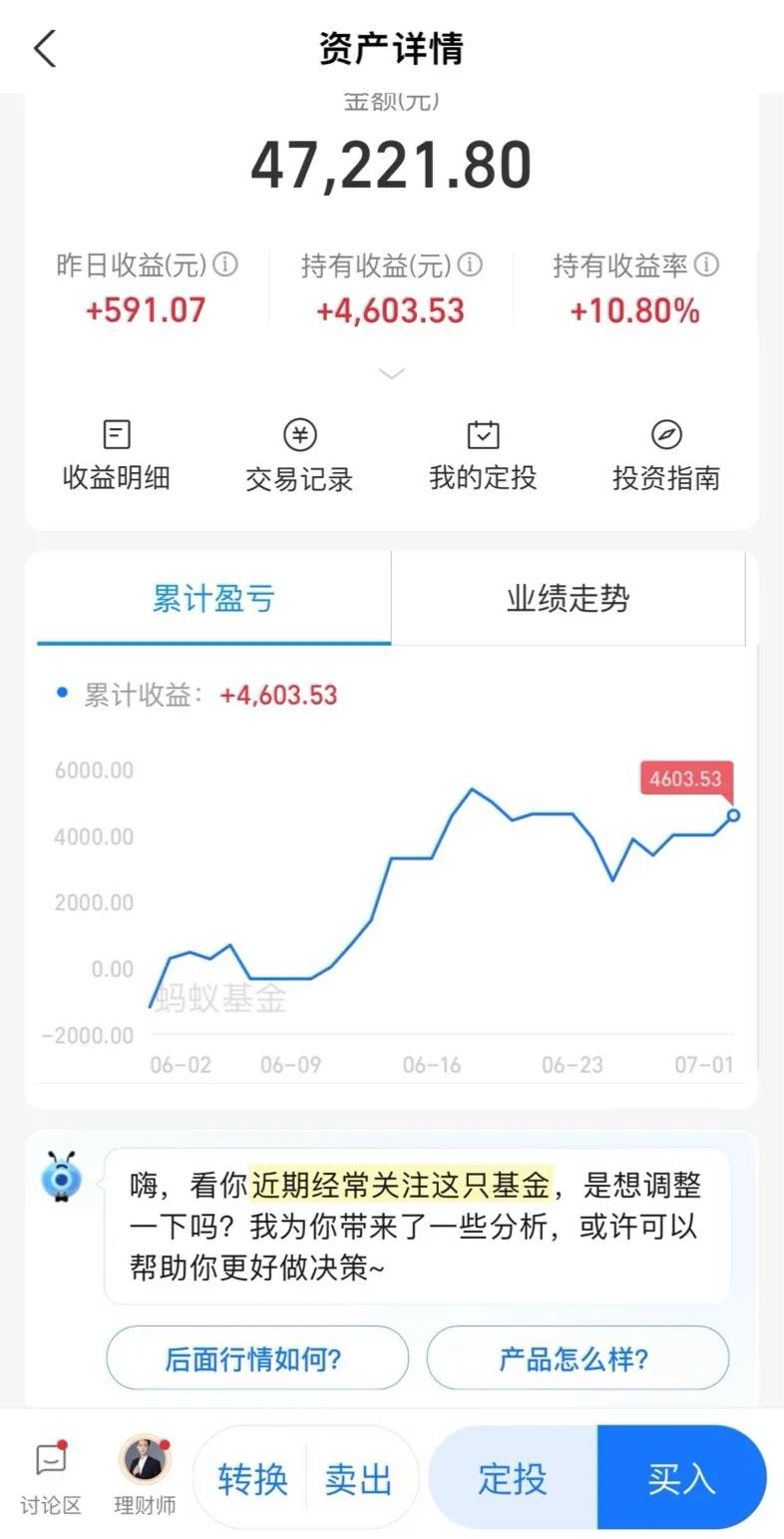
这种多轮沟通的能力,正是破解金融服务难题的关键所在。这就像我们在看病求医问药的时候,需要医生和我们的多轮复杂沟通才能摸清「症结」,「开具处方」。
技术团队进一步解释说,大模型压缩了海量的世界知识和金融知识,有一定的推理能力,而专家智能体引入行业专家的 SOP 进一步强化了这种推理能力,让支小宝学会预测用户在享受某项服务后,下一步最可能需要什么。
过去,由于技术局限性,支小宝追求对话准确性,并不会特别关注轮次。现在,轮次已经成为衡量服务深度的重要指标:用户与新版支小宝的对话轮次提升了约40%。
四、对齐:成为「专家」的关键一环
在向「专家」进阶的路上,AI 其实也跟人一样努力。每个月,技术团队都会拿出包含2000多个问题的评测数据集,让人类专家和支小宝来一场双盲 PK,看看后者有没有长进。
现在,面对「巴菲特现在为什么加倍下注油气股票 」、「巴菲特为什么减持比亚迪」、「桥水基金的投资哲学是什么」这样的问题,支小宝也能像金融专家一样解读。
通用大语言模型虽然可以通过检索增强生成( RAG )迅速捏合一个摘要式答案,却难以像分析师一样深入剖析问题。
回答「巴菲特现在为什么加倍下注油气股票 」。
让支小宝向专家对齐,正是这支队伍的核心工作,其中一个极其重要的工作就是「对齐训练」,这也是 ChatGPT 获得成功的关键。
不过,「理财专家」定位使得支小宝的对齐水位需要比 OpenAI 的「3H 」( Helpful、Harmless、Honest )更高,面向理财这样的严谨应用,支小宝技术团队「由内到外」向专家对齐,对齐标准从3H 升级为严谨性和专业性,整体工作也可谓细致入微。
首先,对齐工作背靠两个核心训练环节——监督微调( SFT )和基于人类反馈的强化学习( RLHF ),前者明确指示模型应该完成哪些任务,后者教导模型如何以人类偏好的标准完成这些任务。
为了让支小宝能严谨地完成任务,大模型底座就需要努力克服众所周知的模型幻觉。类似于驾照训练让司机对齐了安全驾驶的标准,支小宝底层模型也对齐了严谨的标准。在监督微调( SFT )阶段,他们从数据、量纲、实体、关系、事实、观点和计算等维度拆解「严谨」,为不同任务场景准备相应的数据集,教会支小宝如何严谨地处理数字、观点、实体,保障它们的可信可溯源。
在基于人类反馈的强化学习( RLHF )环节,他们进一步训练大模型对严谨性和专业性的自发遵从,这也是让大语言模型胜任严谨应用的关键。新版支小宝会在缺乏信息时「认怂」,避免强答;会像人类专家一样,提供专业分析的同时,识别和安抚用户情绪,这都归功于这个训练环节为系统对齐了专家的回答标准。
接受完监督微调( SFT )和基于人类反馈的强化学习( RLHF )「调教」的大语言模型,就像手握驾照的司机,上路总归有危险,还需要安全的汽车和交通系统。为此,技术团队也安排了数据链路、智能体反思、安全围栏、攻防巡检等系统性措施进一步保障支小宝的严谨性。
不过,知易行难,最大的挑战其实是构建专家水平的高质量指令集所需要的定力和资源——当你为大语言模型写好剧本后,接下来就要准备相应的指令数据(和银子)。
技术团队花了大量心思构建金融能力指令集。他们借鉴了布鲁姆模型,这是教育心理学中一种广受认可的能力评估方法,提供了清晰的认知发展路径,将能力培养划分为记忆、理解、应用、分析、评价、创造等递进阶段,为训练过程提供了明确主线。
通过将这六个认知层次与不同业务场景交叉对应,技术团队详细定义了支小宝在每个场景和认知阶段应掌握的具体技能,并据此设计训练任务,最终形成了一套专业的金融能力培养方案。
在数据标注上,蚂蚁财富也投入了大量精力和资源。支小宝底层的严谨应用大模型面向专家进行对齐训练,这意味着只有专家水准的人才能满足标注工作的严谨性和专业性,他们不仅为此组建了一个具有专业标注能力的团队,还维护着一支具有金融和算法复合能力的技术队伍,专门针对高难度问题构建精准的金融语料和数据,确保支小宝能够在复杂的金融领域游刃有余。
五、接力:「原生大模型技术人员」
时间倒转2018年,支小宝的「前身」——内部代号为「安娜」的智能理财 AI 项目启动,恰逢 OpenAI 的 ChatGPT 前身 GPT-1.0开始研发。当时,AI 的真正威力尚未完全释放。
支小宝的初期团队汇聚了 NLP、CV 和工程技术等多领域的精英。他们怀着探险家的热情出发,却很快发现前路崎岖难行。每一步都像在荒野中开辟道路,即便亲眼目睹大语言模型带来的巨大突破,仍难以完全信任它的潜力。过往积累的知识和技能仿佛一夜贬值,也徒增一些不安与压力。
如今,这个技术团队也不断扩充着新鲜血液,一群「原生大模型技术人员」正成为团队中坚力量。这些人能丢掉之前的技术包袱,天生以大模型思维解决问题,仿佛从不担心技术的边界,在不知不觉中拓展了曾经的技术边界。
技术更迭如同潮水,一浪高过一浪。就像多年前支付宝的扫码支付,当那声清脆的「滴」响起,曾经令人惊叹的技术复杂性瞬间归于平静。总有一天,轰轰烈烈的大模型还有它的原生技术人员,也将沉淀为后代生活中一个平凡的 Token。
但更多的普通人,已经就此获益。