声明:本文来自于微信公众号 新智元(ID:AI_era),作者:新智元,授权Soraor转载发布。
【新智元导读】刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT- 4 掰手腕!
就在刚刚,英伟达再一次证明了自己的AI创新领域的领导地位。
它全新发布的Nemotron-4 340B,是一系列具有开创意义的开源模型,有可能彻底改变训练LLM的合成数据生成方式!

论文地址:https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron4340B8T0.pdf
这一突破性进展,标志着AI行业的一个重要里程碑——
从此,各行各业都无需依赖大量昂贵的真实世界数据集了,用合成数据,就可以创建性能强大的特定领域大语言模型!

现在,Nemotron-4 340B已经取得了辉煌战绩,直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT- 4 一较高下!
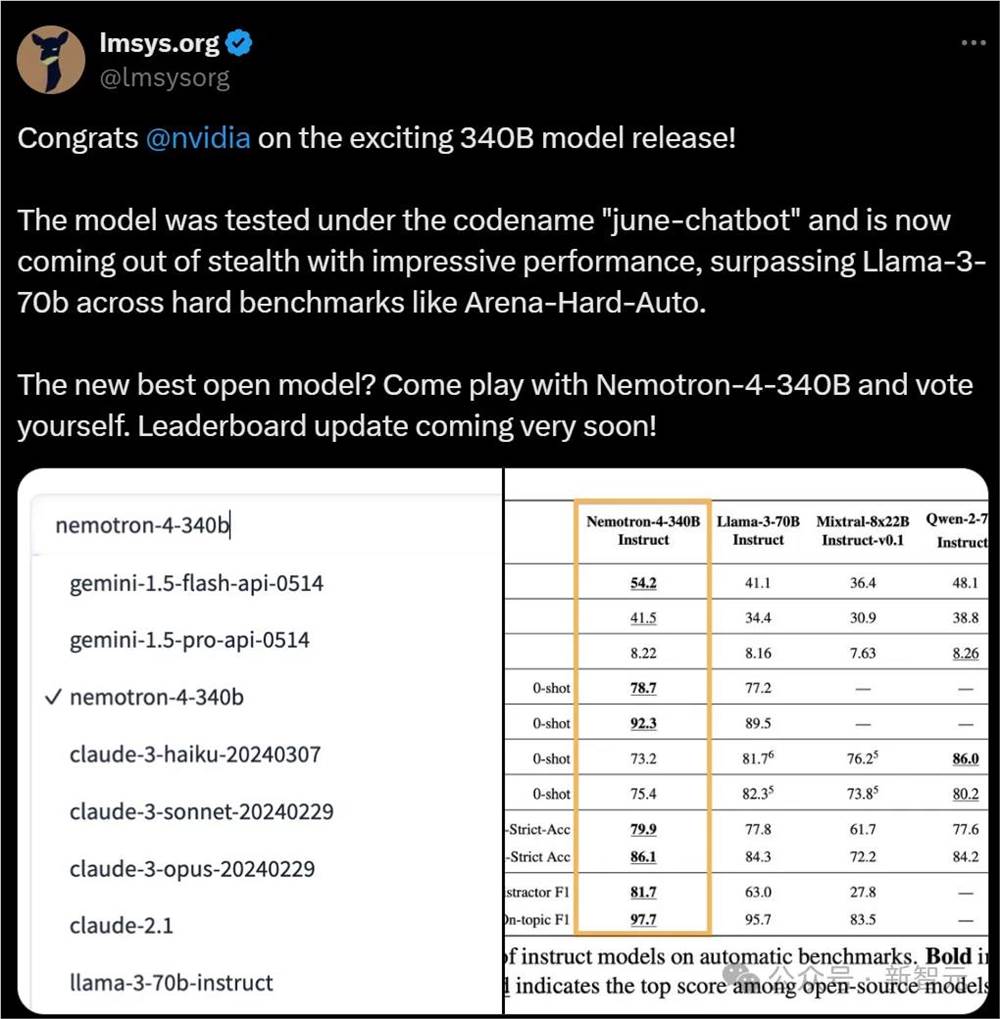
其实,以前这个模型就曾登上大模型竞技场LMSys Chatbot Arena,当时它的别名是「june-chatbot」
具体来说,Nemotron-4 340B包括基础模型Base、指令模型Instruct和奖励模型Reward,并构建了一个高质量合成数据生成的完整流程。
模型支持4K上下文窗口、 50 多种自然语言和 40 多种编程语言,训练数据截止到 2023 年 6 月。
训练数据方面,英伟达采用了高达 9 万亿个token。其中, 8 万亿用于预训练, 1 万亿用于继续训练以提高质量。
值得一提的是,指令模型的训练是在98%的合成数据上完成的。
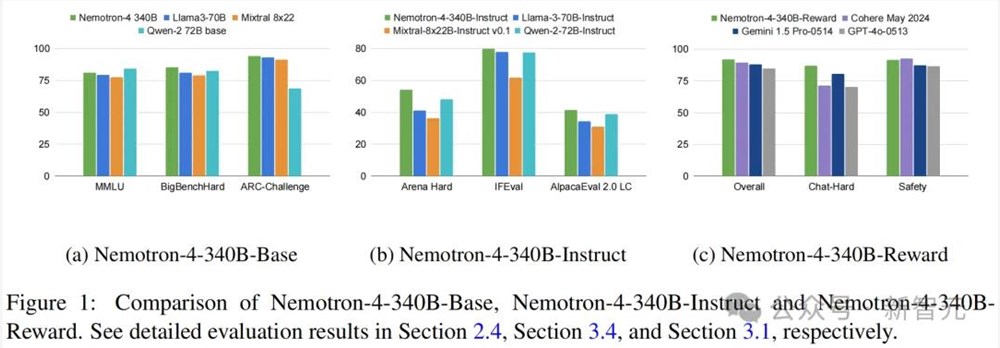
结果显示,Nemotron-4-340B-Base在常识推理任务,如ARC-Challenge、MMLU和BigBench Hard基准测试中,可以和Llama-3 70B、Mixtral 8x22B和Qwen-2 72B模型媲美。
而Nemotron-4-340B-Instruct,在指令跟随和聊天能力方面也超越了相应的指令模型。
Nemotron-4-340B-Reward在发表时,在RewardBench上实现了最高准确性,甚至超过了GPT-4o- 0513 和Gemini 1.5 Pro- 0514 这样的专有模型。
在BF16 精度下,模型的推理需要 8 块H200,或 16 块H100/A100 80GB。如果是在FP8 精度下,则只需 8 块H100。

除此之外,Nemotron-4 340B还有一个非常显著的特点——对商用十分友好的许可。
高级深度学习研究工程师Somshubra Majumdar对此表示大赞:「是的,你可以用它生成你想要的所有数据」
LLM无法获得大规模、多样化标注数据集,怎么破?
Nemotron-4 340B指令模型,可以帮助开发者生成合成训练数据。
这些多样化的合成数据,模仿了真实世界的数据特征,因而数据质量明显提升,从而提升了各领域定制LLM的性能和稳定性。
而且,为了进一步提高AI生成数据的质量,开发者还可以用Nemotron-4 340B 奖励模型,来筛选高质量的响应。
它会根据有用性、正确性、一致性、复杂性和冗长性这 5 个属性,对响应评分。
另外,研究者可以使用自己的专用数据,再结合HelpSteer2 数据集,定制Nemotron-4 340B 基础模型,以创建自己的指令或奖励模型。
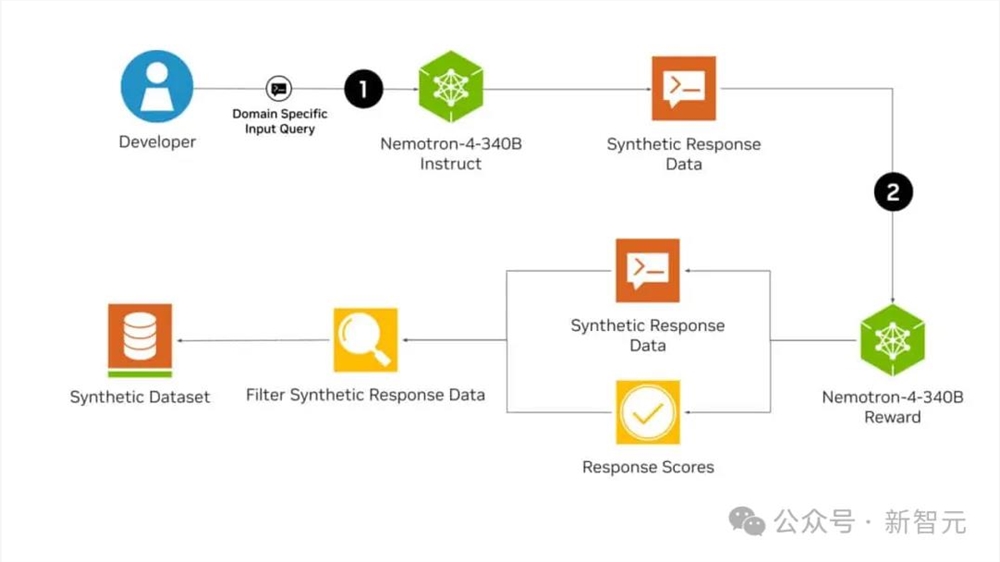
利用开源的NVIDIA NeMo和NVIDIA TensorRT-LLM,开发者可以优化指令模型和奖励模型的效率,从而生成合成数据,并对响应进行评分。
所有Nemotron-4 340B模型都利用张量并行性经过TensorRT-LLM优化,这种模型并行性可以将单个权重矩阵分割到多个GPU和服务器上,从而实现大规模高效推理。
其中,基础模型可以使用NeMo框架进行定制,以适应特定的用例或领域。广泛的预训练数据使得我们可以对它进行微调,并且为特定的下游任务提供更准确的输出。
通过NeMo框架,英伟达提供了多种定制方法,包括监督微调和参数高效微调方法,如低秩适应(LoRA)。
为了提高模型质量,开发者可以使用NeMo Aligner和由Nemotron-4 340B奖励模型标注的数据集来对齐模型。

显然,Nemotron-4 340B对各行业的潜在影响是巨大的。
在医疗领域,如果能生成高质量合成数据,可能会带来药物发现、个性化医疗和医学影像方面的突破。
在金融领域,基于合成数据训练的定制大语言模型,则可能会彻底改变欺诈检测、风险评估和客户服务。
在制造业和零售业方面,特定领域的LLM可以实现预测性维护、供应链优化和个性化客户体验。
不过,Nemotron-4 340B的发布,也提出了一些隐忧,比如数据隐私和安全怎样保证?
随着以后合成数据的普及,企业是否有防护措施来保护敏感信息,并防止滥用?
如果用合成数据训练AI模型,是否会引发伦理问题,比如数据中的偏见和不准确可能引发意料外的后果?
但至少在目前,越来越多迹象表明,只有合成数据才是未来。

下面,我们就来看看,英伟达都提出了哪些创新的方法:
数据
预训练数据是基于三种不同类型的混合,共有9T token。其中,前8T用于正式预训练阶段,最后1T用于继续预训练阶段。
英语自然语言(70%):由不同来源和领域的精选文档组成,包括网页文档、新闻文章、科学论文、书籍等。
多语种自然语言(15%):包含 53 种自然语言,由单语语料库和平行语料库中的文档构成。
代码(15%):包含 43 种编程语言。
架构
与Nemotron-4-15B-Base类似,Nemotron-4-340B-Base基于的也是仅解码器Transformer架构。
具体来说,模型使用因果注意力掩码来确保序列的一致性,并采用旋转位置嵌入(RoPE)、SentencePiece分词器、分组查询注意力(GQA),以及在MLP层中使用平方ReLU激活。
此外,模型没有偏置项,丢弃率为零,输入输出嵌入不绑定。
模型超参数如表 1 所示,有 94 亿个嵌入参数和 3316 亿个非嵌入参数。

训练
Nemotron-4-340B-Base使用 768 个DGX H100 节点进行训练,每个节点包含 8 个基于NVIDIA Hopper架构的H100 80GB SXM5 GPU。
每个H100 GPU在进行 16 位浮点(BF16)运算时,峰值吞吐量为989 teraFLOP/s(不含稀疏运算)。
英伟达采用了 8 路张量并行、 12 路交错流水线并行和数据并行相结合的方法,并使用了分布式优化器,将优化器状态分片到数据并行副本上,以减少训练的内存占用。
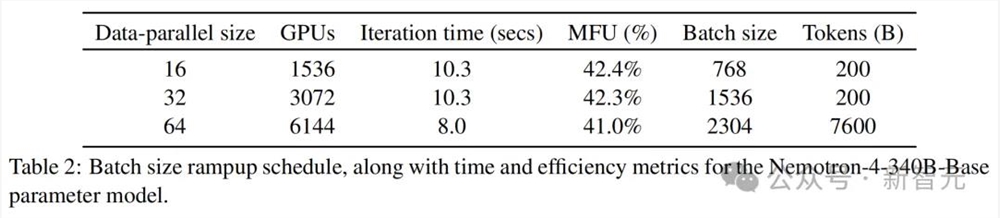
表 2 总结了批大小增加的 3 个阶段,包括每次迭代时间,以及GPU利用率(MFU)等,其中100%是理论峰值。
在这一部分,我们报告了 Nemotron-4-340B-Base 的评估结果。我们将该模型
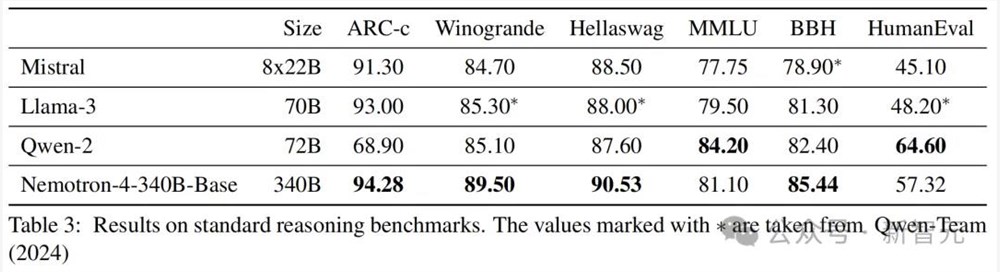
表 3 是Nemotron-4-340B-Base与Llama-3 70B、Mistral 8x22 和Qwen-2 72B三款开源模型的比较结果。
可以看到,Nemotron-4-340B-Base在常识推理任务以及像BBH这样的流行基准测试中拿下了SOTA,并在MMLU和HumanEval等代码基准测试中位列第二。
奖励模型构建
奖励模型在模型对齐中起着至关重要的作用,是训练强指令跟随模型时用于偏好排序和质量过滤的重要评判者。
为了开发一个强大的奖励模型,英伟达收集了一个包含10k人类偏好数据的数据集——HelpSteer2。
与成对排名模型不同,多属性回归奖励模型在区分真实有用性和无关伪影(如仅因长度而偏好较长但无用的回复)方面更有效。此外,回归模型在预测细粒度奖励、捕捉相似回复之间的有用性细微差别方面表现更好。
回归奖励模型建立在Nemotron-4-340B-Base模型之上,通过用一个新的奖励「头」替换模型的最终softmax层。
这个「头」是一个线性投影,将最后一层的隐藏状态映射到一个包含HelpSteer属性(有用性、正确性、一致性、复杂性、冗长性)的五维向量。
在推理过程中,这些属性值可以通过加权求和聚合为一个总体奖励。
数据对齐
值得注意的是,在整个对齐过程中,英伟达仅使用了大约20K的人工标注数据,而数据生成管线则生成了用于监督微调和偏好微调的98%以上的数据。
提示生成准备
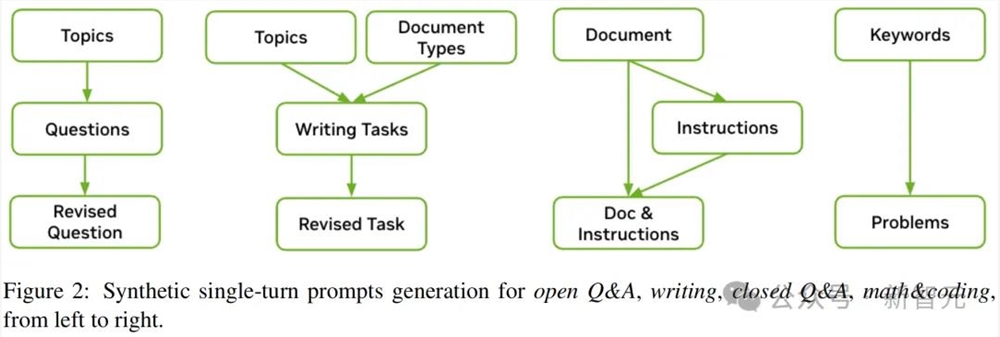
生成合成提示,是合成数据生成(SDG)的第一步。
这些提示在不同维度上的多样性至关重要,包括任务多样性(如写作、开放问答、封闭问答)、主题多样性(如STEM、人文、日常生活)和指令多样性(如JSON输出、段落数量、是或否回答)。
对此,英伟达使用Mixtral-8x7B-Instruct-v0. 1 作为生成器,分别对这些任务的合成提示进行了生成。
单轮合成提示
为了收集多样化的主题,英伟达先引导生成器输出一组多样化的宏观主题,然后再为每个合成的宏观主题生成相关的子主题。
加上人工收集的,最终得到的主题达到了3K个。
用于合成提示生成的提示如下:

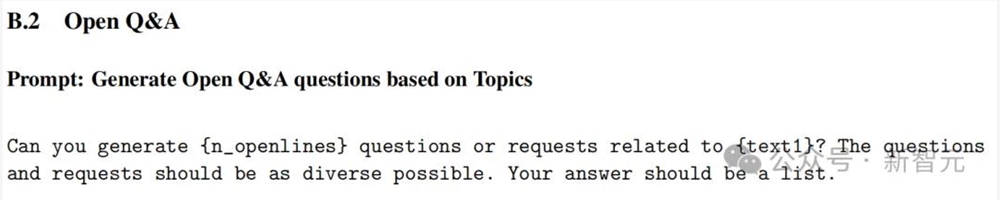
合成指令跟随提示
为了提升对于对齐模型至关重要的指令跟随能力,就需要生成合成的指令跟随提示(例如,「写一篇关于机器学习的文章,你的回答应包含三个段落」)。
具体来说,先随机选择一些合成提示。对于每个合成提示,从「可验证」指令模板中随机生成一个合成指令(例如,「你的回答应包含三个段落」)。然后,使用手动定义的模板将提示和指令连接在一起。
除了单轮指令跟随提示外,英伟达还构建了多轮指令跟随提示,这些指令适用于所有未来的对话(例如「根据以下指令回答问题和所有后续问题:[指令开始]用三个段落回答。[指令结束]」)。
此外,英伟达还构建了第二轮指令跟随提示,可以根据给定的指令修改之前的回答。
合成两轮提示
为了在偏好微调中提高模型的多轮对话能力,英伟达构建了两轮提示来建立偏好数据集。
具体来说,提示包含一个用户问题,一个助手回答,和另一个用户问题,形式为「用户:XXX;助手:XXX;用户:XXX;」。
英伟达从ShareGPT中获取第一个用户提示,并使用中间指令模型生成助手回答和下一轮问题。
真实世界的LMSYS提示
为了更好地模拟真实世界的用户请求,英伟达将LMSYS-Chat-1M中的提示按平衡比例进行组合,并将其分为两个不同的集合,一个用于监督学习,另一个用于偏好学习。
在监督学习部分,英伟达移除了LMSYS中被标记为潜在不安全的提示,以避免引发不良对话。但在偏好学习部分则进行了保留,以便模型能够学习如何区分安全和不安全的响应。
从图 3 中可以看到,合成提示的平均有用性高于LMSYS提示。由于简单提示更容易「有用」,这意味着LMSYS提示比合成单轮提示平均来说更难且更复杂。
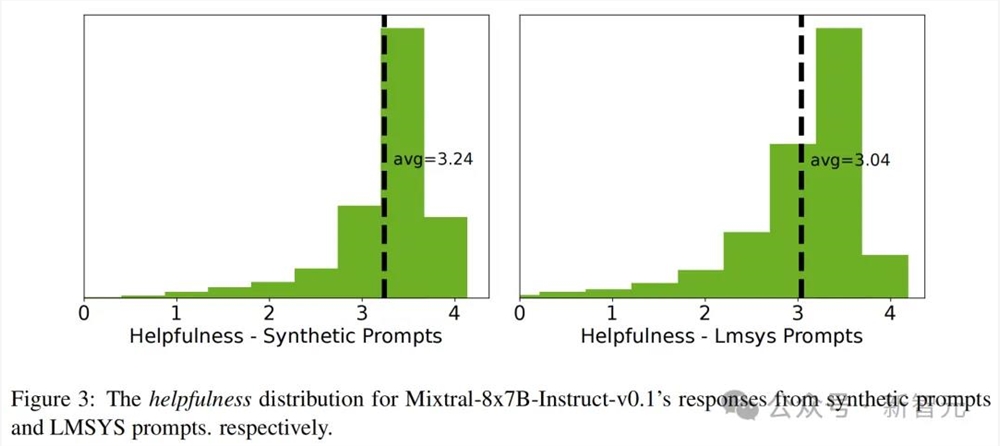
合成对话生成
通过监督微调,模型就可以学习到,如何以对话形式与用户互动。
英伟达通过提示指令模型生成基于输入提示的响应,来启动合成对话。
为了培养多轮对话能力,他们把每个对话设计成包含三轮,好让对话流程更加动态、更有互动性。
通过迭代角色扮演,模型会交替模拟助手和用户的角色。
英伟达发现,为了在用户回合中引导所需的行为,就需要提供明确的提示来定义不同的用户个性。
并且,附上对话历史是至关重要的。
他们对用户回合进行了后处理,排除了礼貌陈述(如「谢谢你...」,「当然,我很高兴...」)来模拟真实世界的用户问题。
生成演示数据,是采用的贪婪采样方法。
此外,英伟达会使用Nemotron4-340B-Reward评估对话质量,为每个样本分配一个分数,并过滤掉那些低于预定阈值的样本。
这就提供了额外的质量控制层,保证保留下来的都是高质量数据。



合成偏好数据生成
英伟达使用了10K人工标注的HelpSteer2 偏好数据,来训练Nemotron-4-340B-Reward。
不过,他们还需要具有更广泛提示领域、更高质量响应的偏好数据,这些响应来自顶级的中间模型,并在可能的情况下包含额外的真实信号。
因此,英伟达生成了三元组形式的合成偏好数据(提示,选择的响应,被拒绝的响应)。
生成响应
偏好数据包含合成的单轮提示、指令跟随提示、双轮提示,以及来自真实世界的提示,包括ShareGPT提示、LMSYS提示、GSM8K和MATH训练数据集中的提示。
对于每个提示,英伟达都使用了随机的中间模型生成响应。
通过多个模型生成响应,就能确保偏好数据集具有多样化的响应,以供模型学习。
此外,他们还生成了更具挑战性的合成偏好示例,这些示例是根据MT-Bench从表现最好的模型中多次随机生成的响应,这样就可以进一步提升模型的性能。
以基准真相作为判断标准
对于每个提示给出的多个响应,英伟达都需要对其偏好排序进行判断,并选择出被选中的响应和被拒绝的响应。
一些任务可以使用基准真相(例如GSM8K和MATH训练数据集中的答案)或验证器(例如指令跟随响应可以用 Python程序验证)来评估。
以LLM/奖励模型为裁判
大多数提示,是没有客观答案的。因此,英伟达尝试了以大语言模型为裁判和以奖励模型为裁判。
在第一种情况中,英伟达向裁判的大语言模型提供提示和两个响应,并要求其比较这两个响应。
为了避免位置偏差,他们会交换响应顺序后,再次询问大语言模型。当大语言模型两次判断一致时,就会选出有效的三元组(提示、被选中的、被拒绝的)。
另外,为了进一步探索了以奖励模型为裁判的情况,英伟达要求Nemotron-4-340B-Reward 预测每个(提示、响应)对的奖励,并根据奖励决定偏好排序。
奖励基准得分显示以,奖励模型为裁判的准确性,要高于以大语言模型为裁判。
特别是在Chat-Hard类别中,选择的响应和被拒绝的响应难以区分,以奖励模型为裁判的表现,要远优于以大语言模型为裁判,平均准确率为0. 87 对0.54。
在这个过程中,英伟达注意到:Chat-Hard类别的评分对于合成数据生成中的偏好排序特别重要。
因此,在后来的数据集迭代中,他们转而使用以奖励模型为裁判。

从弱到强的迭代对齐
如前所述,高质量的数据对于模型的对齐至关重要。
在数据合成过程中,需要一个对齐的大语言模型来准确遵循指令。
这就引发了一系列重要的问题:哪个模型最适合作为生成器?生成器的强度与数据质量之间有何关系?如何改进数据生成器?
受到弱到强泛化的启发,英伟达开发了一种新颖的迭代方法,逐步优化数据。这种方法结合了对齐训练与数据合成的优势,使它们能够相互增强,并且持续改进。
图 4 展示了从弱到强的迭代对齐的工作流程。
首先,使用一个初始对齐模型来生成对话和偏好数据。然后,通过监督微调和偏好调优,利用它们对更好的基础模型进行对齐。
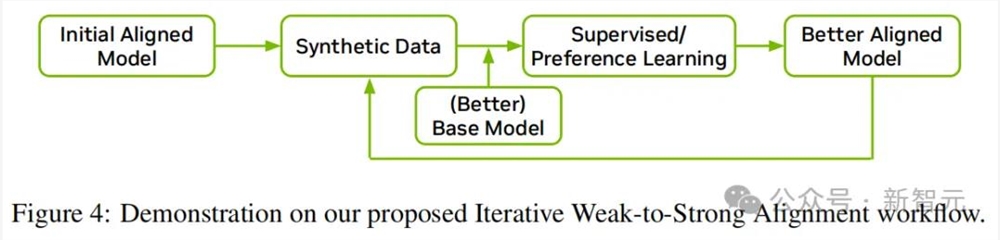
有趣的是,英伟达发现,教师模型并不会限制学生模型的上限——
随着基础模型和对齐数据的改进,新对齐的模型能够显著超过初始对齐模型。注意,对齐过程与基础模型的预训练是并行进行的。
在第一次迭代中,英伟达选择了Mixtral-8x7B-Instruct-v0. 1 作为初始对齐模型,因为它是一个具有许可的强大模型。
生成的数据用于训练Nemotron-4-340B-Base的一个中间检查点,称为340B-Interm-1-Base。
值得注意的是,340B-Interm-1-Base的表现优于Mixtral 8x7B基础模型,这反过来使得最终的340B-Interm-1-Instruct模型,能够超过Mixtral-8x7B-Instruct-v0. 1 模型。
这就证明,可以通过弱监督引出模型强大的能力。
在第二次迭代中,英伟达使用生成的340B-Interm-1-Instruct模型,作为新的数据生成器。
由于它比Mixtral-8x7B-Instruct-v0. 1 更强,第二次迭代生成的合成数据质量就更高。
生成的数据用于训练340B-Interm-2-Base模型,使其升级为340B-Interm-2-Chat模型。
这个迭代过程形成了一个自我强化的飞轮效应,改进主要来自两个方面——
(1)当使用相同的数据集时,基础模型的强度直接影响指令模型的强度,基础模型越强,指令模型也越强;
(2)当使用相同的基础模型时,数据集的质量决定了指令模型的效果,数据质量越高,指令模型也越强。
在整个对齐过程中,英伟达进行了多轮数据生成和改进,不断提升模型的质量。
附加数据源
此外,英伟达还结合了多个补充数据集,以赋予模型特定的能力。
主题跟随
主题连贯性和细粒度指令跟随是,指令模型的重要能力。
因此,英伟达结合了CantTalkAboutThis训练集,其中包括了覆盖广泛主题的合成对话,并故意插入干扰回合以分散聊天机器人对主要主题的注意力。
这就能帮助模型,在任务导向的交互中更好地专注于预定的主题。
无法完成的任务
某些任务可能由于需要特定的能力(如互联网访问或实时知识)而无法由模型独立完成。
为减少这种情况下的幻觉,英伟达采用少样本方法,使用人类编写的示例来提示大语言模型生成各种问题。
然后,他们会明确要求大语言模型以拒绝的方式回应,收集这些回应,并将其与相应的问题配对。
这些配对数据就可以用于训练模型,让它们能够更好地处理无法完成的任务。
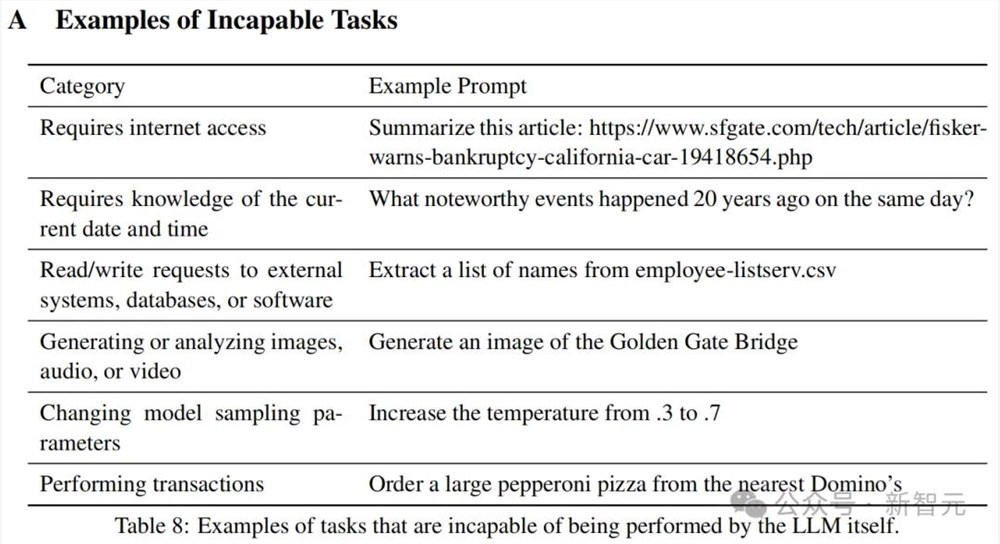
STEM数据集
Open-Platypus已被证明可以提高STEM和逻辑知识。因此,英伟达将具有许可的子集(如PRM800K、SciBench、ARB 、openbookQA)纳入训练数据中。
基于文档的推理和问答
基于文档的问答是大语言模型的重要用例。
英伟达利用FinQA数据集提高了数值的推理能力,使用人工标注数据提高了上下文问答的准确性,并使用 wikitablequestions数据集,增强了模型对半结构化数据的理解。
函数调用
此外,英伟达还使用了一部分来自Glaive AI的样本,以增强模型在函数调用方面的能力。
对齐算法
分阶段的监督微调
监督微调(Supervised Fine-tuning,SFT)是模型对齐的第一步。
为了改善传统SFT方法存在的缺陷,英伟达设计了一种两阶段的SFT策略,使模型能够依次、有计划地学习不同的行为。
结果显示,这种方法在所有下游任务中都产生了更好的效果。
代码SFT
为了在不影响其他任务的情况下提高编码和推理能力,英伟达选择先在编码数据上进行SFT。
为了获得大量的数据,英伟达开发了一种名为Genetic Instruct的全新方法——通过对进化过程的模拟,利用自我指令和向导编码器突变,从少量高质量种子生成大量合成样本。
过程中,英伟达还引入了一种适应度函数,利用LLM评估生成指令及其解决方案的正确性和质量。
然后,通过这些评估和检查的样本会被添加到种群池中,进化过程会持续进行,直到达到目标种群规模。
最终,经过广泛的去重和过滤后,英伟达保留了大约 80 万条样本用于代码SFT训练。
通用SFT
第二阶段,就是通用SFT了。
这里,英伟达采用的是一个包含 20 万样本的混合数据集。
为了减轻遗忘的风险,数据混合中还包括了前一个代码SFT阶段的2%的代码生成样本。
偏好微调
在完成监督微调后,英伟达继续通过偏好微调来改进模型。
在这个阶段,模型将学习偏好示例,其形式是:提示,选择的响应,被拒绝的响应。
直接偏好优化(DPO)
DPO算法通过优化策略网络,来最大化选择和被拒绝响应之间的隐含奖励差距。
在策略学习区分选择和被拒绝的响应时,可以观察到,随着差距的增加,选择和被拒绝响应的概率都在一致地下降,即使选择的响应是高质量的。
根据经验,当训练时间足够长时,策略网络容易过拟合,一个指标(例如,MT-Bench)的改进通常伴随着其他指标(例如,零样本MMLU)的退化。
为了解决这些问题,英伟达在选择的响应上添加了加权的SFT损失,以补充原始的DPO损失。
额外的SFT损失有助于防止策略网络大幅偏离偏好数据,特别是因为偏好数据不是从参考策略生成的。
为了避免模型学习低质量的选择响应,当没有可用的真实值时,英伟达使用了Nemotron-4-340B-Reward来挑选高质量的选择响应示例。最终,这产生了一个包含 16 万示例的偏好数据集。
奖励感知偏好优化(RPO)
为了解决DPO存在的过拟合问题,英伟达提出了一种新算法——奖励感知偏好优化(RPO)。它尝试使用由策略网络定义的隐含奖励近似奖励差距。
基于此,便得到了一个新的损失函数:
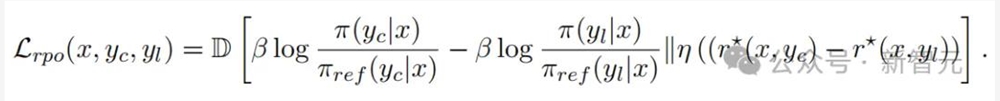
结果显示,随着RPO迭代次数的增加,模型还可以持续地在所有任务上获得提升。
经过三次RPO训练迭代后的检查点,就是最终的Nemotron-4-340B-Instruct。
指令模型评估
自动基准测试
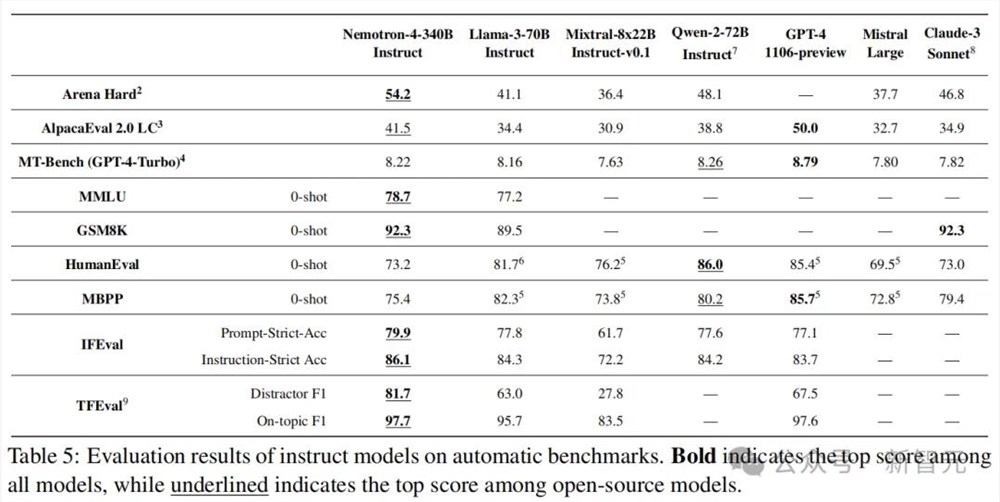
英伟达对Nemotron-4-340B-Instruct进行了全面的自动基准测试评估:
单轮对话:AlpacaEval 2.0 LC和Arena Hard
多轮对话:MT-Bench(GPT-4-Turbo)。需要注意的是,这是原始MT-Bench的修正版本,得分平均要低0. 8 分。
综合基准测试:MMLU(零样本)
数学:GSM8K(零样本)
代码:HumanEval(零样本)和 MBPP(零样本)上的Pass@ 1 得分
指令跟随:IFEval
主题跟随:TFEval
正如表 5 所示,Nemotron-4-340B-Instruct在当前可用的开源模型中表现出色,具备很强的竞争力。
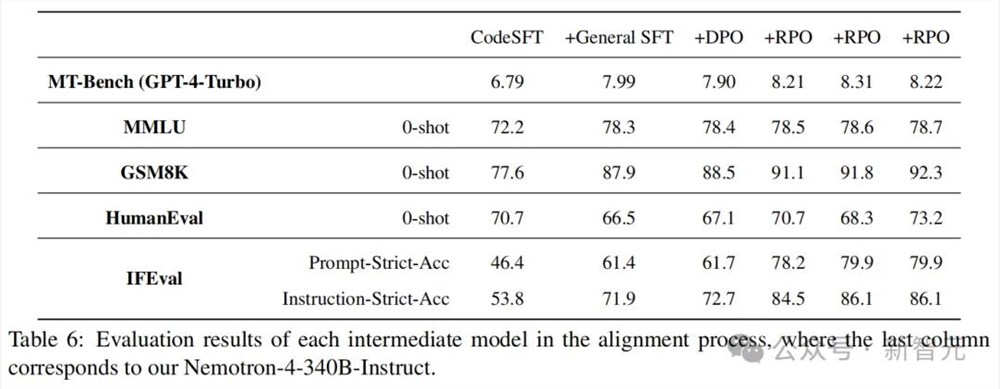
对齐训练包括:代码SFT、通用SFT、DPO和三轮RPO。
表 6 展示了模型最终的成绩,并量化了每个对齐阶段的中间模型的性能:
CodeSFT阶段显著提高了HumanEval得分,从基础模型的57. 3 提升到70.7;
接下来的通用SFT阶段大幅提升了其他类别的准确性,如MT-Bench和MMLU,尽管HumanEval得分略有下降;
DPO阶段进一步提升了大多数指标,但MT-Bench的得分略有下降;
最后的RPO阶段均匀地提升了所有指标。特别是,MT-Bench得分从7. 90 增加到8.22,IFEval Prompt-Strict-Acc的得分从61. 7 增加到79.9。
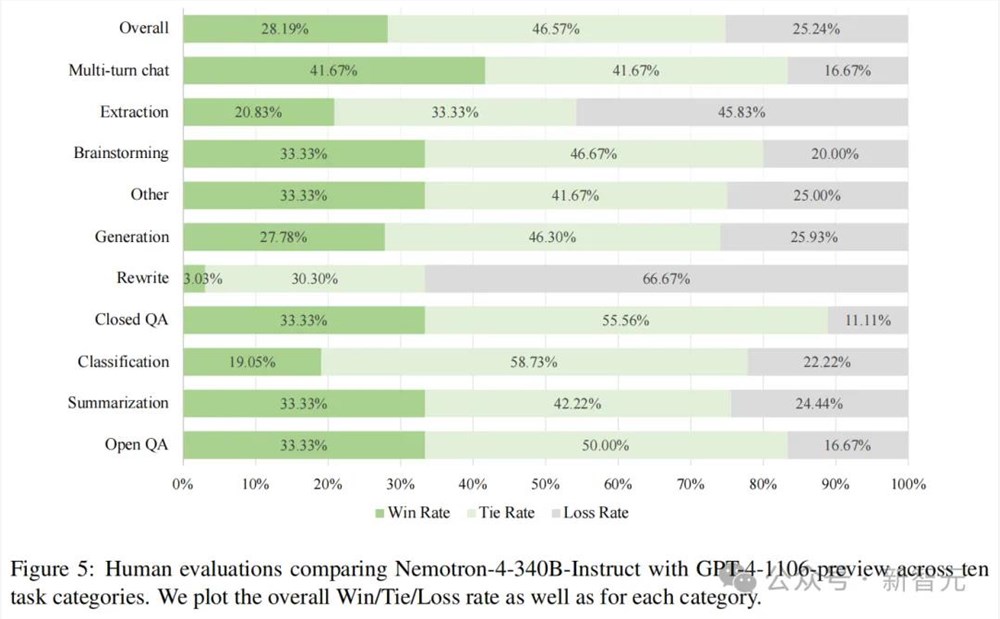
人类评估
除了自动评估外,英伟达模型进行了人类评估。其中,标注员被提供了 136 个提示,分为 10 个不同的任务类别。
基于「有用性」和「真实性」这两个维度,英伟达详细定义了 5 个质量等级的具体内容,从而在减少了主观性的同时,提升了可靠性。
在标注设计中,每个提示都与固定模型集合中的三个不同响应配对。每个提示的响应顺序是随机的,所有提示和响应都由同一组标注员进行评估。
标注完成后,将评分转换为相对于GPT-4-1106-preview的相对胜/平/负率。
从图 5 中可以看到,除了提取和重写任务外,Nemotron-4-340B-Instruct的胜率与GPT-4-1106-preview相当或更好,特别是在多轮对话中表现出色。
整体来说,Nemotron-4-340B-Instruct的胜:平:负比率为28.19%:46.57%:25.24%。
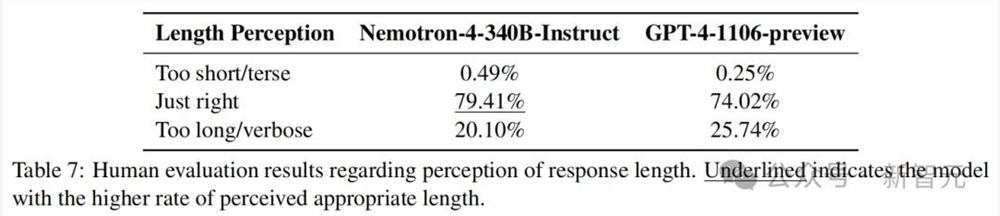
从表 7 中则可以看到,与GPT-4-1106-preview相比,标注员认为Nemotron-4-340B-Instruct的响应长度更为合适(79.41%对74.02%)。
值得注意的是,这一优势主要来自较低的长/冗长响应率(20.10%对25.74%)。

参考资料:
https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
https://venturebeat.com/ai/nvidias-nemotron-4-340b-model-redefines-synthetic-data-generation-rivals-gpt-4/