OpenAI和谷歌又又又打起来了!
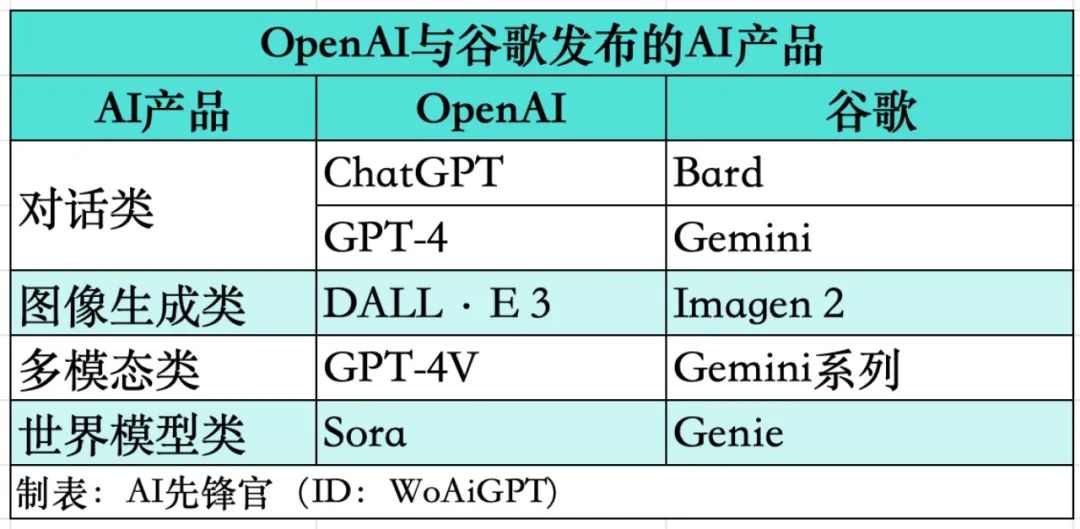
这一波AI浪潮磅礴而来,OpenAI和谷歌的竞争呈白热化状态,谁也不服谁。
这不,Sora问世才不到两周,谷歌又祭出基础世界模型——Genie。

今天咱们就来聊聊这个Genie究竟是个啥玩意?
Genie论文已发布,感兴趣的朋友可以去瞅瞅。
论文地址:
https://arxiv.org/pdf/2402.15391.pdf
项目主页:
https://sites.google.com/view/genie-2024/home?pli=1
-1-
这究竟是个啥玩意?
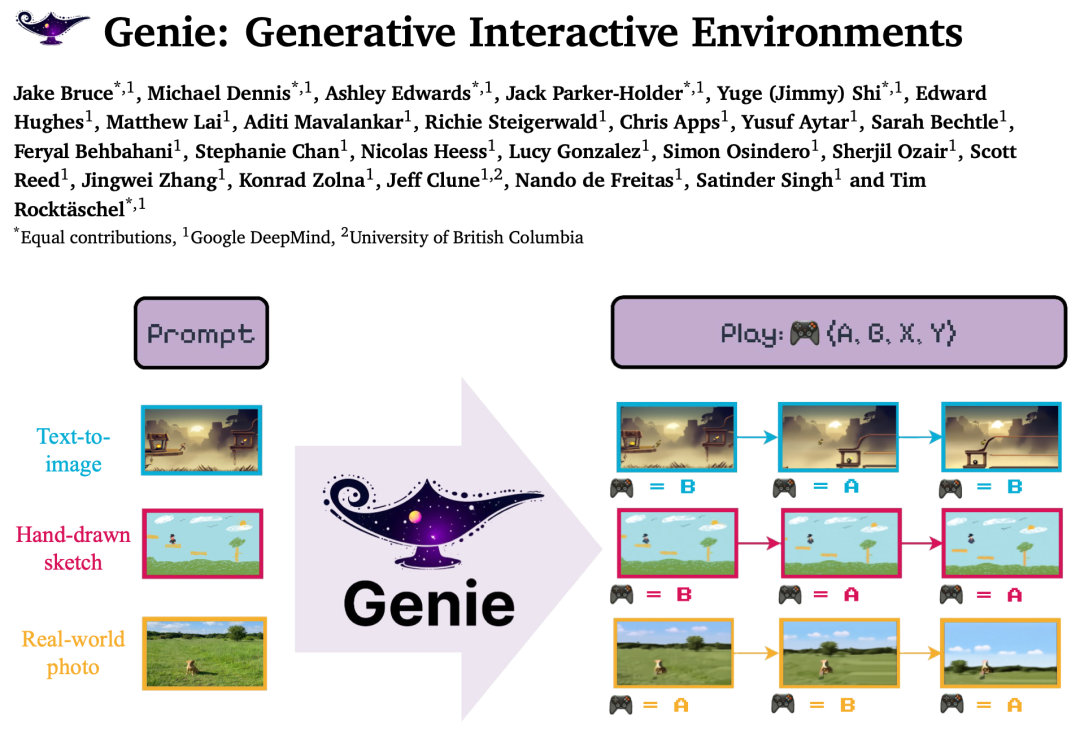
据官方介绍,Genie是一个 110 亿参数的基础世界模型,可以从合成图像、照片甚至草图中生成无穷无尽的可玩(可操作可控)世界。
Genie是第一个经过无监督训练的生成式交互环境,其训练数据来自未标记的互联网视频。
要知道,传统AI是需要人给图片打标签来训练AI识别图片。这意味着Genie需要从视频中自行识别不同动作的特征和模式。
Genie可以通过它从未见过的图像来提示,例如现实世界的照片或草图,使人们能够与他们想象中的虚拟世界互动。
Genie包含三个关键组件:
一个潜在动作模型(LAM),用于推断视频帧之间的潜在动作;
一个视频tokenizer,将原始视频帧转换为离散的 token;
一个动态模型,根据当前帧的token 和潜在动作预测下一个帧。
整个模型分为两个阶段进行训练,首先训练视频tokenizer,然后训练潜在动作模型和动态模型。
谷歌表示,虽然他们专注于2D平台游戏和机器人的视频,但方法是通用的,适用于任何类型的领域,并且可以扩展到更大的互联网数据集。
网友评价:


-2-
它牛逼在哪?
第一,Genie 可以在没有动作标签时学习控制。
Genie的独特之处在于它能够完全从互联网视频中学习细粒度的控制,即使这些视频没有标注正在执行的动作或应该控制图像的哪个部分。
这意味着它可以在没有明确指导的情况下,从大量未标记的数据中学习。

第二,Genie可以培养下一代创作者。
Genie只需要一张图片就可以创建一个全新的互动环境。这为各种生成和进入虚拟世界的新方法打开了大门。
例如,我们可以采用最先进的文本到图像生成模型,并使用它来生成开始帧,再用Genie使其变得生动。在这里,我们使用Imagen2生成图像,并使用Genie赋予它们生命。
在如下动图中,谷歌使用Imagen2 生成了图像,再使用 Genie 将它们变为现实:

不止如此,Genie还可以应用到草图等人类设计相关的创作领域。

或者,应用在真实世界的图像中:

第三,Genie是实现通用智能体的基石。
以往的研究表明,游戏环境可以成为开发AI 智能体的有效测试平台,但常常受到可用游戏数量的限制。
现在借助Genie,未来的 AI 智能体可以在新生成世界的无休止的 curriculum 中接受训练。谷歌提出一个概念证明,即 Genie 学到的潜在动作可以转移到真实的人类设计的环境中。
第四,Genie是生成式虚拟世界的未来。
Genie是一种通用方法,可以应用于许多领域,而不需要任何额外的领域知识。
谷歌在RT1 的无动作视频上训练了一个较小的 2.5B 模型。与 Platformers 的情况一样,具有相同潜在动作序列的轨迹通常会表现出相似的行为。
这表明Genie 能够学习一致的动作空间,这可能适合训练机器人,打造通用化的具身智能。

Genie还可以模拟可变形的物体,对于可以从数据中学习的人类设计的模拟器来说,这是一项具有挑战性的任务。
Genie开启了一个能够从图像或文本生成整个交互式世界的时代。谷歌相信,这将成为培训未来多面手智能体的催化剂。
-3-
背后团队啥情况?
Genie这篇论文的作者有25人,其中核心贡献者9人。

与OpenAI的Sora团队一样,Genie团队中也有华人学者。
石宇歌【Yuge (Jimmy) Shi】就是Genie论文一作之一。她目前是谷歌 DeepMind 研究科学家, 2023 年获得牛津大学机器学习博士学位。
论文地址:
https://arxiv.org/pdf/2402.15391.pdf
项目主页: